一,错误日志
1,错误日志文件对Mysql的启动,运行,关闭过程进行了记录。默认名是:机器名.err
当Mysql不能正常启动时,我们应该查看该错误日志文件。
2,在配置文件中,我们可以修改错误日志的文件名
log_error = mysql.err
二,慢查询日志
我们可以设置一个阈值,把运行时间超过该值的所有SQL语句都记录到慢查询日志文件中。
默认情况下,Mysql数据库并不启动慢查询日志,我们可以在配置文件中,手动设置。
相关参数:
slow_query_log:是否开启慢查询日志 slow_query_log_file:慢查询日志文件名 long_query_time:指定慢查询阈值 min_examined_row_limit:扫描记录少于该值的sql不记录到慢查询 日志 log_queries_not_using_index:将没有使用索引的sql记录到日志 log_throttle_queries_not_using_indexes:限制每分钟记录没有使用索引的sql语句的次数 long_slow_admin_statement:记录管理操作,如alter table log_output:慢查询日志格式,可以输出到表或文件中。如: file|table 文件|表。 log_slow_slave_statements:在从服务器上开启慢查询日志 log_timestamps:写入时区信息

三,查询日志
记录所有对Mysql数据库请求的信息,默认文件名:主机名.log。还可以把记录放在mysql库下的general_log表中。
四,归档日志(binlog)
记录对数据库执行更改的所有操作,但是不包括select和show这类操作。默认情况下归档日志文件并没有启动
1,归档日志的作用:
恢复:做数据恢复时,可以通过归档日志进行point-in-time的恢复
复制:通过执行归档日志使得从库和主库进行实时同步
2,归档日志相关配置
max_binglog_size:单个归档日志文件的最大值,超过该值,就产生新的归档日志文件(后缀名+1)
binlog_cache_size:归档日志缓存大小,默认32K
sync_binlog:表示每写缓冲多少次就同步到磁盘,如果设置为1,表示采用同步写磁盘的方式来写归档日志,就不使用缓存了,直接写到文件中
binlog_format:[STATEMENT | ROW | MIXED],
STATEMENT记录的是sql语句。比如:update t2 set username = upper(username) where id = 1
ROW记录的行更改的情况,记两条,更新前和更新后的都记录。
3,当时用InnoDB存储引擎时,所有未提交的归档日志会被记录到一个缓存中。
事务提交后,再把缓存中的归档日志写入文件中。所以,归档日志并不是每次写的时候都同步到磁盘。
五,重做日志(redo log)
1,默认情况下会有两个文件,分别为ib_logfile0和ib_logfile1。

每个InnoDB存储引擎至少有一个重做日志文件组,每个文件组下至少有2个重做日志文件,比如默认:ib_logfile0,ib_logfile1。
日志组中每个重做日志文件的大小一致,以循环的方式使用。

2,参数配置
innodb_log_file_size:重做日志文件大小
innodb_log_files_in_gourp:日志文件组中重做日志文件的数量,默认为2
inndo_mirrored_groups:日志镜像文件组,默认为1,没有镜像
innodb_log_group_home_dir:日志文件组所在的路径
3,当有一条记录需要更新的时候,InnoDB引擎会先把记录写到redo log里,并更新内存(此时该表的查询缓存失效),这时更新就算完成了。然后 InnoDB引擎会在适当的时候(系统比较闲的时候),把这个操作记录更新到磁盘里。
注意:写入重做日志的操作也不是直接写,而是先写入一个重做日志缓冲中。

4,InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,从头开始写,写到末尾就又回到开头循环写。如图:
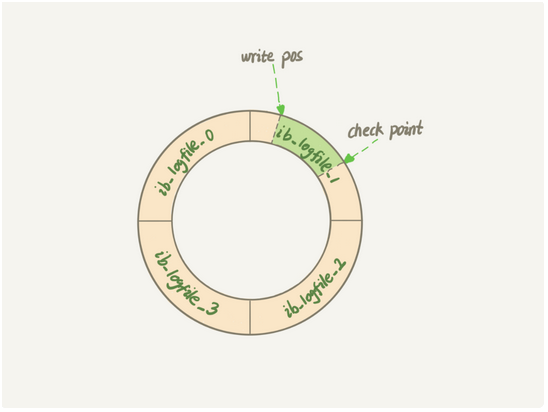
write pos:当前记录的位置,一边写,一边后移。写到第3号文件末尾就回到0号文件开头。
checkpoint:是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
Write pos 和 checkpoint之间是空着的部分,用来记录新的操作。如果write pos追上checkpoint,这是后不能在执行新的更新,得先停下来把部分记录更新到数据文件,把checkpoint推进一下。
5,有了redo log,InnoDB可以保证即使数据库发生异常重启,之前的记录都不会丢失,这个能力叫 crash-safe。
六,归档日志和重做日志写入的先后顺序是怎样的?
1, 当执行update语句时,执行器和InnoDB内部的流程:
执行器先找引擎取 ID=2的行,引擎找到这一行然后返回(如果这一行的所在的数据页在内存中,直接返回。否则,从磁盘读到内存,然后返回)
执行器拿到数据,把这个值加1,得到新的一行数据。然后调用引擎接口写入这行新数据
引擎把这行新数据更新到内存中,,同时把这个更新操作记录到redo log中,此时redo log处于 prepare状态。通知执行器随时可以提交事务。
执行器生成上面加1操作的binlog,并把binlog写入磁盘。
执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交状态。

注意:redo log的写入拆成了两个步骤:prepare和commit,这就是两阶段提交。
2,为什么要有两阶段提交?
2.1, 为了保证两份日志之间的逻辑一致
如果redo log只是完成了prepare,而binlog又失败,那么事务本身会回滚,所以这个库里面的status的值为0.
如果通过binglog恢复出一个库,status的值也是0。这样就不算丢失。
两阶段就是为了保证一致性用的。
2.2,如果不用两阶段提交,通过日志恢复出来的库和数据库的数据可能不一致
比如:先写binlog后写redo log,如果在binlog写完之后crash掉,由于redo log还没写,系统恢复后这个事物无效,所以这一行的值为0.但是binlog里面已经记录了 “把c从0改为1”这个日志。以后用binlog来恢复的时候,恢复出来的这一行c的值就是1,和原库的值不同。