超大型数据库的大小常常达到数百GB,有时甚至要用TB来计算。而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长。这不但影响着数据库的运行效率,也增大数据库的维护难度。除了表的数据量外,对表不同的访问模式也可能会影响性能和可用性。这些问题都可以通过对大表进行合理分区得到很大的改善。当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分来提高系统的运行效率。如果系统有多个CPU或是多个磁盘子系统,可以通过并行操作获得更好的性能。所以对大表进行分区是处理海量数据的一种十分高效的方法。本文通过一个具体实例,介绍如何创建和修改分区表,以及如何查看分区表。
1 SQL Server 2005
SQL Server 2005是微软在推出SQL Server 2000后时隔五年推出的一个数据库平台,它的数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使用户可以构建和管理用于业务的高可用和高性能的数据应用程序。此外SQL Server 2005结合了分析、报表、集成和通知功能。这使企业可以构建和部署经济有效的BI解决方案,帮助团队通过记分卡、Dashboard、Web Services和移动设备将数据应用推向业务的各个领域。无论是开发人员、数据库管理员、信息工作者还是决策者,SQL Server 2005都可以提供出创新的解决方案,并可从数据中获得更多的益处。
它所带来的新特性,如T-SQL的增强、数据分区、服务代理和与.Net Framework的集成等,在易管理性、可用性、可伸缩性和安全性等方面都有很大的增强。
2 表分区的具体实现方法
表分区分为水平分区和垂直分区。水平分区将表分为多个表。每个表包含的列数相同,但是行更少。例如,可以将一个包含十亿行的表水平分区成 12 个表,每个小表表示特定年份内一个月的数据。任何需要特定月份数据的查询只需引用相应月份的表。而垂直分区则是将原始表分成多个只包含较少列的表。水平分区是最常用分区方式,本文以水平分区来介绍具体实现方法。
水平分区常用的方法是根据时期和使用对数据进行水平分区。例如本文例子,一个短信发送记录表包含最近一年的数据,但是只定期访问本季度的数据。在这种情况下,可考虑将数据分成四个区,每个区只包含一个季度的数据。
2.1 创建文件组
建立分区表先要创建文件组,而创建多个文件组主要是为了获得好的 I/O 平衡。一般情况下,文件组数最好与分区数相同,并且这些文件组通常位于不同的磁盘上。每个文件组可以由一个或多个文件构成,而每个分区必须映射到一个文件组。一个文件组可以由多个分区使用。为了更好地管理数据(例如,为了获得更精确的备份控制),对分区表应进行设计,以便只有相关数据或逻辑分组的数据位于同一个文件组中。使用ALTER DATABASE,添加逻辑文件组名:
ALTER DATABASE [DeanDB] ADD FILEGROUP [FG1]
DeanDB为数据库名称,FG1文件组名。创建文件组后,再使用 ALTER DATABASE 将文件添加到该文件组中:
ALTER DATABASE [DeanDB] ADD FILE ( NAME = N'FG1', FILENAME = N'C:\DeanData\FG1.ndf' , SIZE = 3072KB , FILEGROWTH = 1024KB ) TO FILEGROUP [FG1]
类似的建立四个文件和文件组,并把每一个存储数据的文件放在不同的磁盘驱动器里。
2.2 创建分区函数
创建分区表必须先确定分区的功能机制,表进行分区的标准是通过分区函数来决定的。创建数据分区函数有RANGE “LEFT | / RIGHT”两种选择。代表每个边界值在局部的哪一边。例如存在四个分区,则定义三个边界点值,并指定每个值是第一个分区的上边界 (LEFT) 还是第二个分区的下边界 (RIGHT)[1]。代码如下:
CREATE PARTITION FUNCTION [SendSMSPF](datetime) AS RANGE RIGHT FOR VALUES ('20070401', '20070701', '20071001')
2.3 创建分区方案
创建分区函数后,必须将其与分区方案相关联,以便将分区指向至特定的文件组。就是定义实际存放数据的媒体与各数据块的对应关系。多个数据表可以共用相同的数据分区函数,一般不共用相同的数据分区方案。可以通过不同的分区方案,使用相同的分区函数,使不同的数据表有相同的分区条件,但存放在不同的媒介上。创建分区方案的代码如下:
CREATE PARTITION SCHEME [SendSMSPS] AS PARTITION [SendSMSPF] TO ([FG1], [FG2], [FG3], [FG4])
2.4 创建分区表
建立好分区函数和分区方案后,就可以创建分区表了。分区表是通过定义分区键值和分区方案相联系的。插入记录时,SQL SERVER会根据分区键值的不同,通过分区函数的定义将数据放到相应的分区。从而把分区函数、分区方案和分区表三者有机的结合起来。创建分区表的代码如下:
CREATE TABLE SendSMSLog
([ID] [int] IDENTITY(1,1) NOT NULL,
[IDNum] [nvarchar](50) NULL,
[SendContent] [text] NULL
[SendDate] [datetime] NOT NULL,
) ON SendSMSPS(SendDate)
2.5 查看分区表信息
系统运行一段时间或者把以前的数据导入分区表后,我们需要查看数据的具体存储情况,即每个分区存取的记录数,那些记录存取在那个分区等。我们可以通过$partition.SendSMSPF来查看,代码如下:
SELECT $partition.SendSMSPF(o.SendDate)
AS [Partition Number]
, min(o.SendDate) AS [Min SendDate]
, max(o.SendDate) AS [Max SendDate]
, count(*) AS [Rows In Partition]
FROM dbo.SendSMSLog AS o
GROUP BY $partition.SendSMSPF(o.SendDate)
ORDER BY [Partition Number]
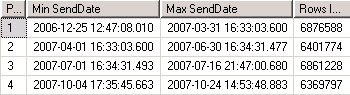
在查询分析器里执行以上脚本,结果如图1所示:
图1 分区表信息
2.6 维护分区
分区的维护主要设计分区的添加、减少、合并和在分区间转换。可以通过ALTER PARTITION FUNCTION的选项SPLIT,MERGE和ALTER TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。
3 性能对比
我们对2650万数据,存储空间占用约4G的单表进行性能对比,测试环境为IBM365,CPU 至强2.7G*2、内存 16G、硬盘 136G*2,系统平台为Windows 2003 SP1+SQL Server 2005 SP1。测试结果如表1:
表1:分区和未分区性能对比表(单位:毫秒)
测试项目 分区 未分区 |
1 16546 61466 |
2 13 33 |
3 20140 61546 |
4 17140 61000 |
说明:
1:根据时间检索某一天记录所耗时间
2:单条记录插入所耗时间
3:根据时间删除某一天记录所耗时间
4:统计每月的记录数所需时间
从表1可以看出,对分区表进行操作比未分区的表要快,这是因为对分区表的操作采用了CPU和I/O的并行操作,检索数据的数据量也变小了,定位数据所耗时间变短。
4 结束语
对海量数据的处理一直是一个令人头痛的问题。分离的技术是所有设计者们首先考虑的问题,不管是分离应用程序功能还是分离数据访问,如果加以了合理规划,都能十分有效的解决大数据表的运行效率低和维护成本高等问题。SQL Server 2005新增的表分区功能,可以对数据进行合理分区,当用户在访问部分数据时,SQL Server最佳化引擎可以根据数据的实体存放,找出最佳的执行方案,而不至于大海捞针。