第一周:深度学习的实用层面
项目进展得一个关键性得因素就是划分高质量得训练集,验证集,测试集。这有助于提高循环迭代得效率。验证集也称为development set
也称为dev set。
验证集主要用于评价不同得模型,通过验证来选择最终得模型。或者说是验证不同得算法,检验那种算法更有效。
然后测试集在选择得模型上进行评估。
三种集合要来自于同一种划分。
深度学习的趋势是权衡方差和偏差
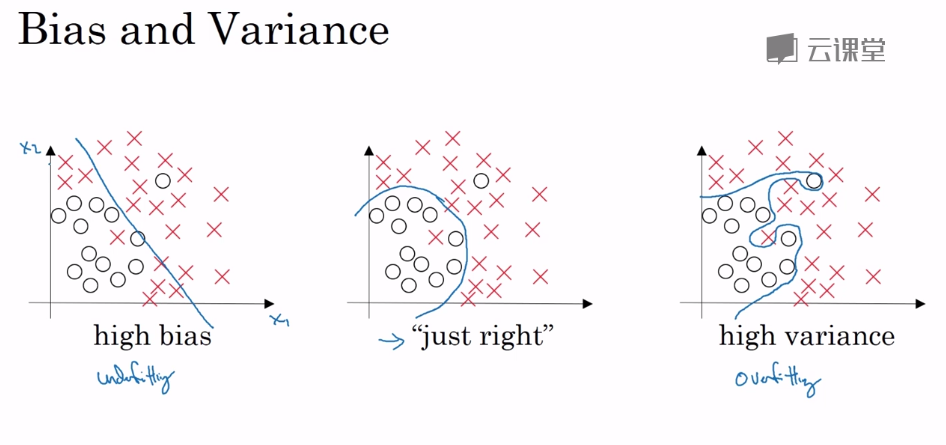
通过训练集与验证集的正确率来观察偏差和方差。假设验证集和训练集是同一分布


紫色的线部分欠拟合,部分过拟合,所以具有高偏差和高方差。
当我们训练好模型后首先要知道模型的偏差是否过高,如果偏差过高甚至无法拟合训练集,那么选择一个新的网络,比如含有更多隐藏层和隐藏单元的网络,
花费更多的时间来训练网络,直至网络拟合训练集。
之后观察方差是否过高,如果方差过高,那么采用更多的数据,或者正则化。
重复此过程,直至找到一个低偏差和低方差的网络







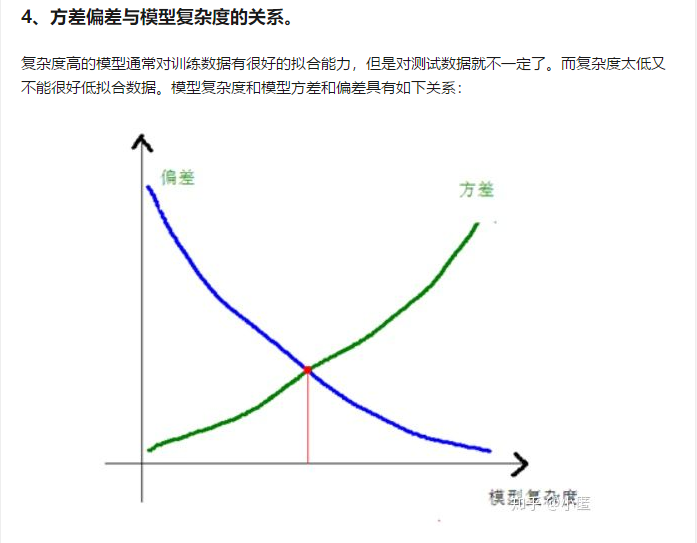



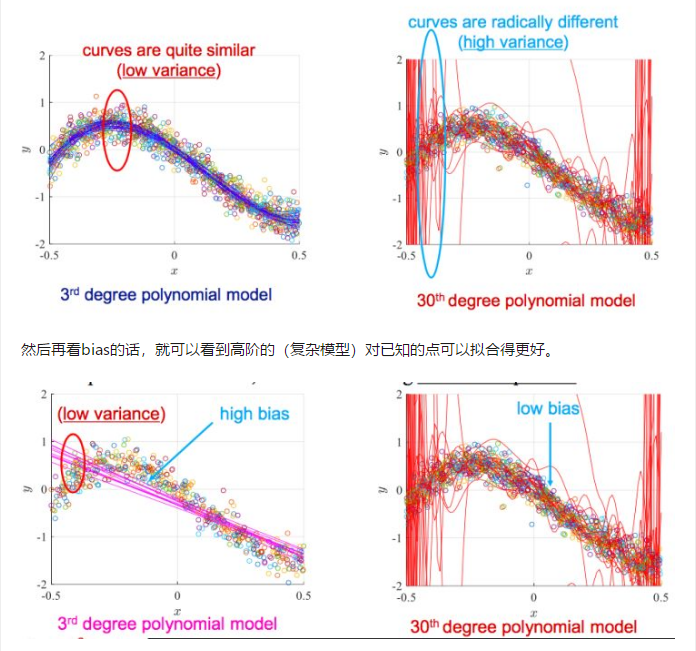
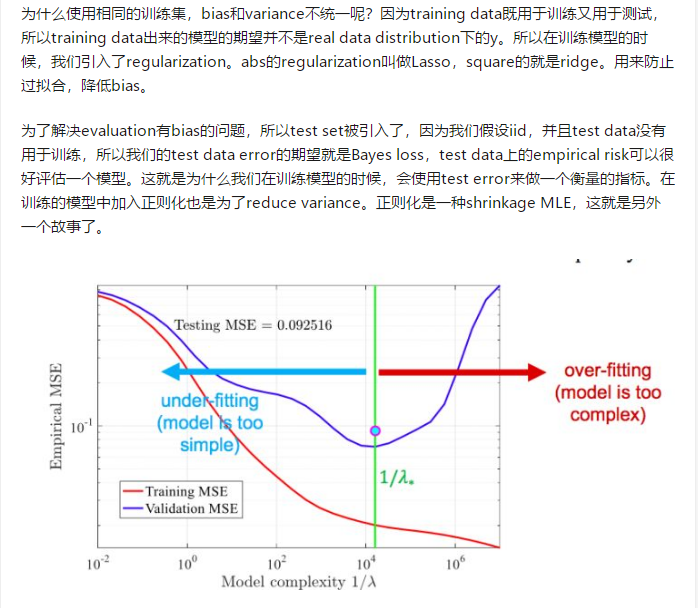
如果怀疑神经网络中出现了高方差,那么一种方法是用更多的数据。另一种方法就是用正则化方法。
在逻辑回归中使用正则化项。

w是一个高维参数矢量,b是一个实数。所以b可以忽略。如果用l1正则化,那么w讲是稀疏的,w中会有很多0。人们越来越倾向于使用l2正则化。
神经网络中的正则化也被称为权重衰减。神经网络中,参数w是一个矩阵,l2正则化其实也是计算平方和。

神经网络最后的那个计算就是让矩阵先乘以一个系数(系数小于1)(被称为权重衰减的原因),再减去那个。
直观的理解就是正则化系数如果设置的过大,那么权重矩阵就会被设置为权重趋于0的值。许多隐藏单元的值为0,其实也就是消除了这些隐藏单元的理解
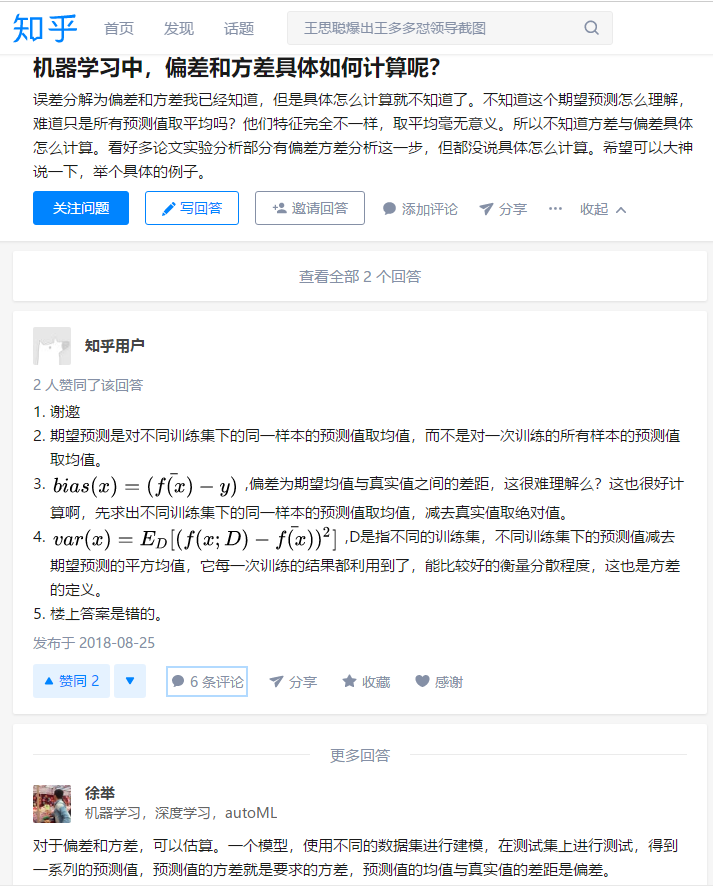
dropout是一种正则化方法,中文名称为随机失活。
假设左边的神经网络存在过拟合,dropout会遍历网络的每一层,设置每一层中消除网络中节点的概率,然后删掉被删除节点进入和射出的线,从而得到一个节点更少,规模更小的网络。作用于训练阶段,在测试阶段不再用,每一次迭代都会从新计算dropout,因此每次的代价函数都不同。
dropout最常用的就是反向随机失活(inverted dropout)

d是随机生成一个向量,a是某一层输出的结果向量。a与b相乘后,a仍需要除以keep-prob
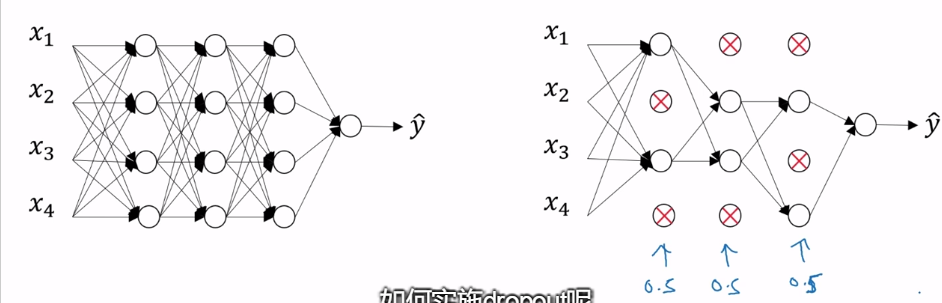
另外一种正则化防止过拟合的方法就是扩大训练集。用翻转,切割,强变形等手段

早停就是在中间点结束训练。
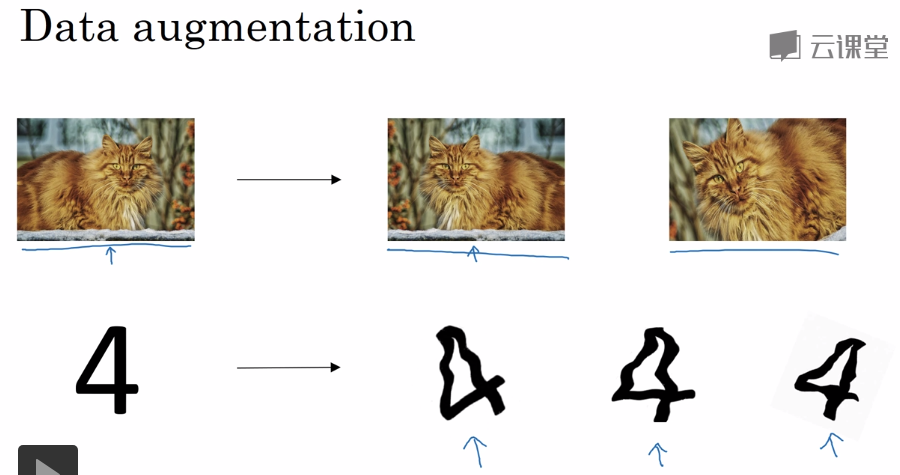
零均值化与方差均值化。训练集用此方法来进行归一化后,测试集也应该用此方法来进行归一化。尤其是数值不能变。
归一化有利于梯度下降。输入数据有的在0-1,有的在0-1000,那么归一化就十分有必要了。如果输入数据在相似的范围,那么归一化就没有那么有必要了。
梯度消失与梯度爆炸详解:https://blog.csdn.net/qq_25737169/article/details/78847691
较大三角形的高宽比更接近于导数,这不是一个单边公差,而是一个双边公差。双边公差更接近于导数。所以用双边公差来估计梯度。

梯度检验可以帮我们很好的发现反向传播中的bug



第二周:优化算法
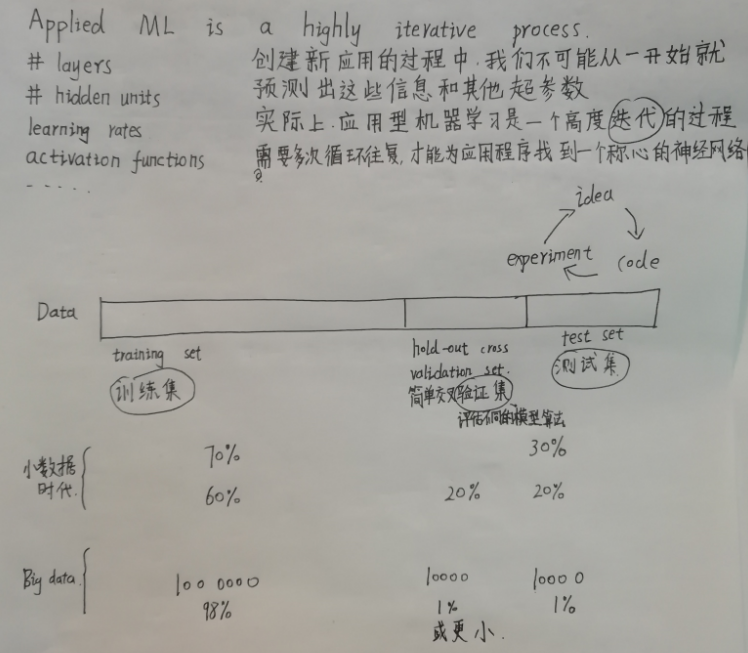
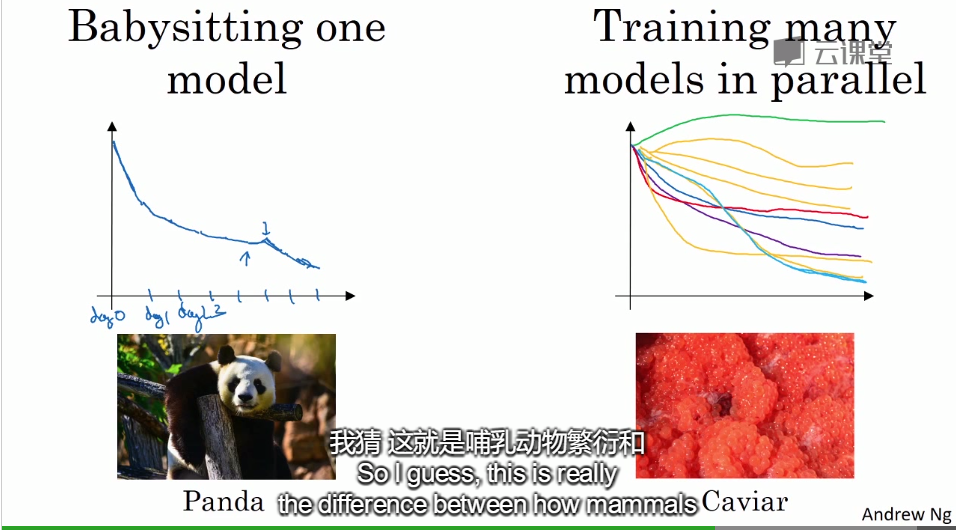
深度学习是一个高度依赖经验的过程,并且伴随着大量的迭代过程。需要训练大量的模型,才能找到适合的那一个。
首先来谈mini-batch gradient descent算法。
吧训练集分割为一些小的集和,这些集和称为mini-batch

右上角的小括号代表第几个训练样本,中括号代表神经网络的第几层输出,大括号代表第几个mini-batch

原来的训练集被划分为许多个小的mini-batch,在每个小的mini-batch上进行一次梯度下降。

现在我们要决定的就是mini-batch的大小

优点:有效的利用了向量化,每一次的迭代时间变少。另一方面,你不需要等到整个训练集被训练完,就可以开始后续的工作。
如果训练集较小,那么就直接使用batch算法。这里说的少一半是说少于2000个样本。
划分mini-batch时,一般大小为64-512,2的幂,主要是考虑到了电脑内存。

指数加权平均法
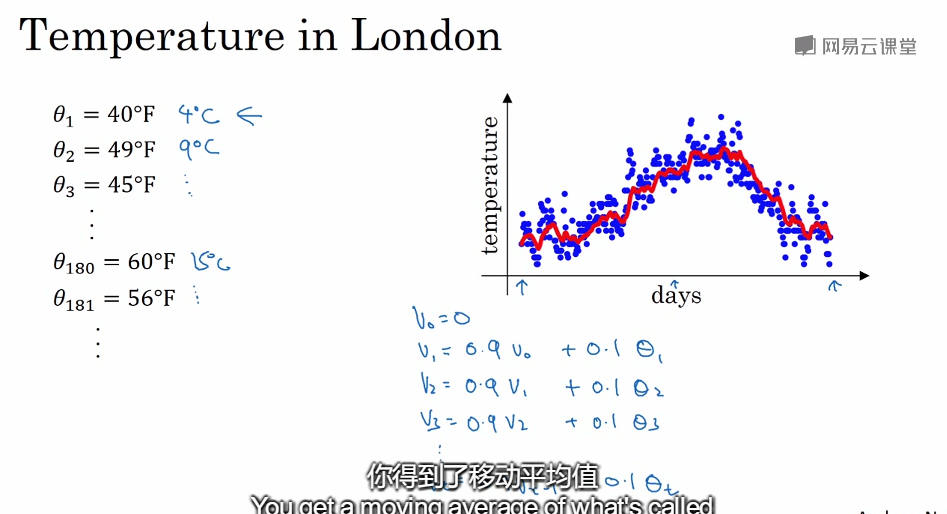

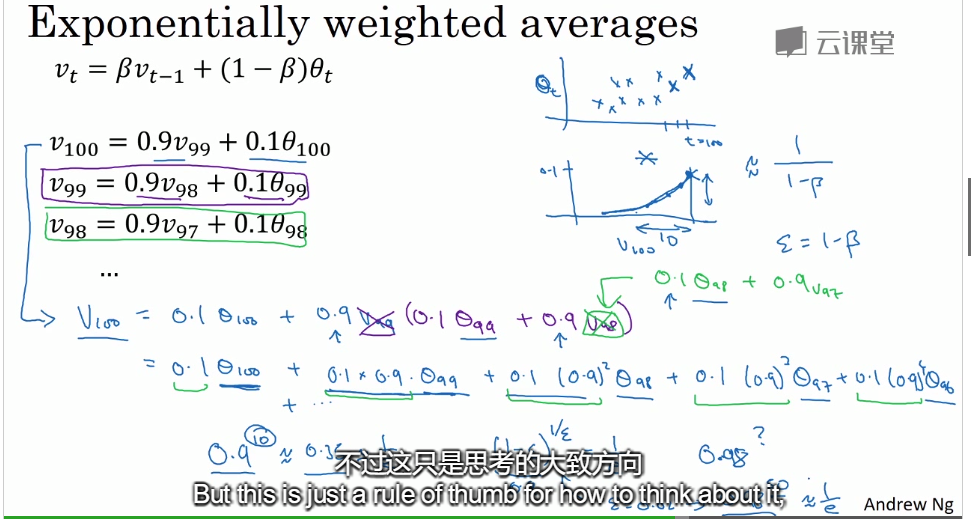
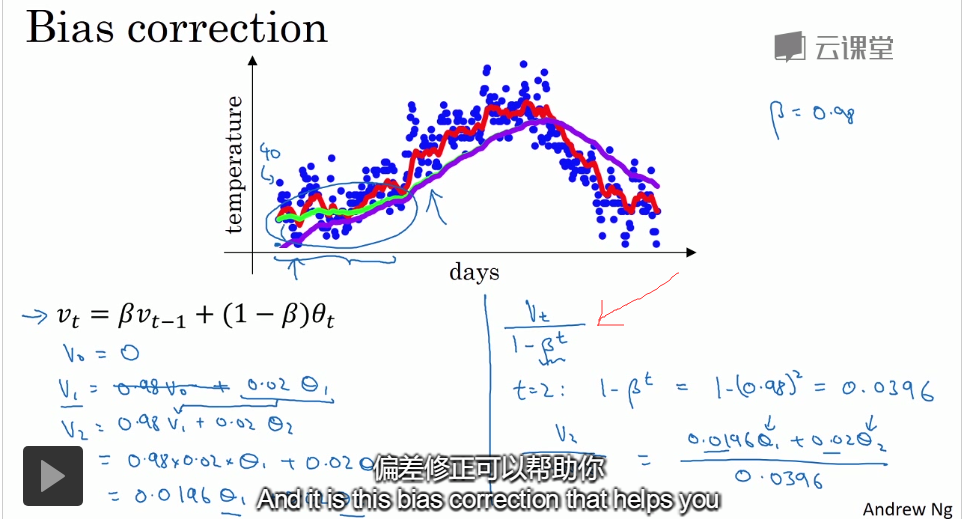
在进行指数加权平均时,初期值会比较低,所以要用到偏差修正:但传统中人们一般不会考虑偏差修正。
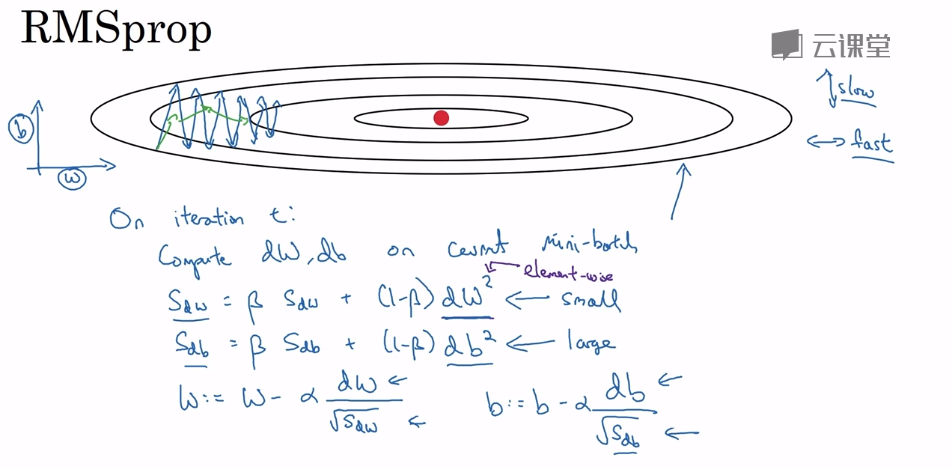
接下来是动量梯度下降,传统的梯度下降,只计算当前的梯度,而动量梯度下降,不仅考虑到了当前的梯度,也考虑到了之前的梯度。方法就是指数加权平均。




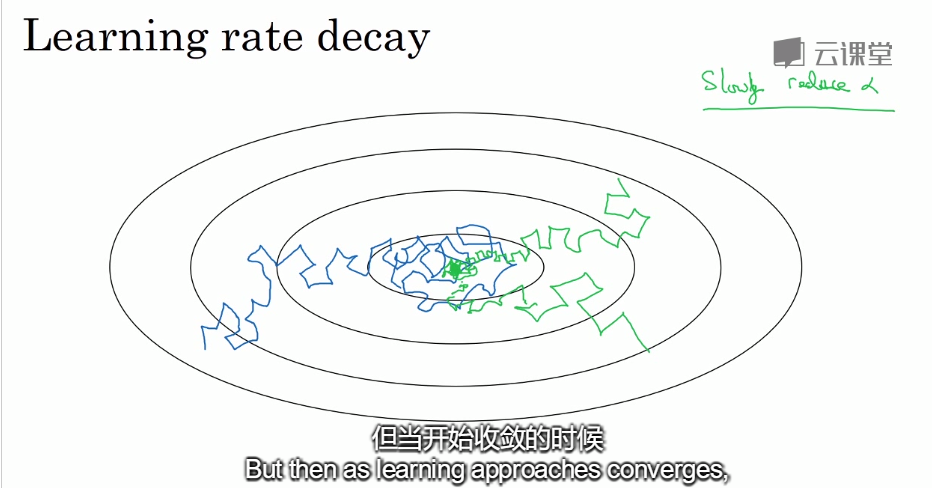
学习率衰减
超参数的重要程度:红橙紫

如果超参数过多,不适宜用排列组合,而是用随机选取点的方法。
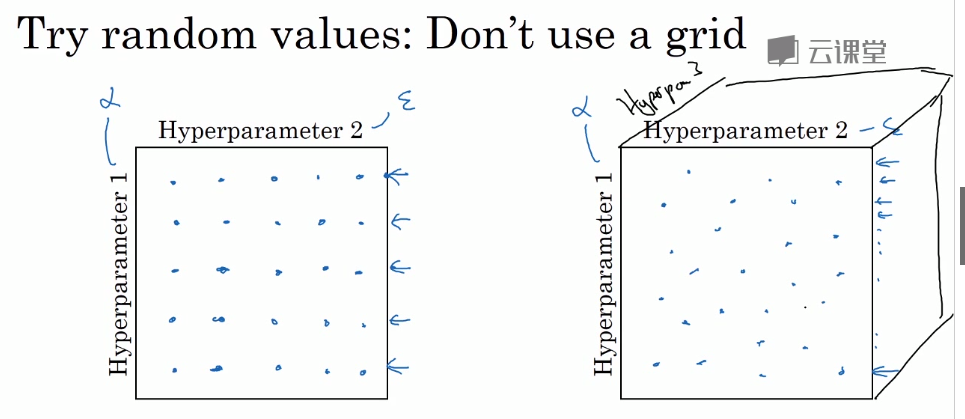
再由粗略到精细:

一些事随机均匀选取的:







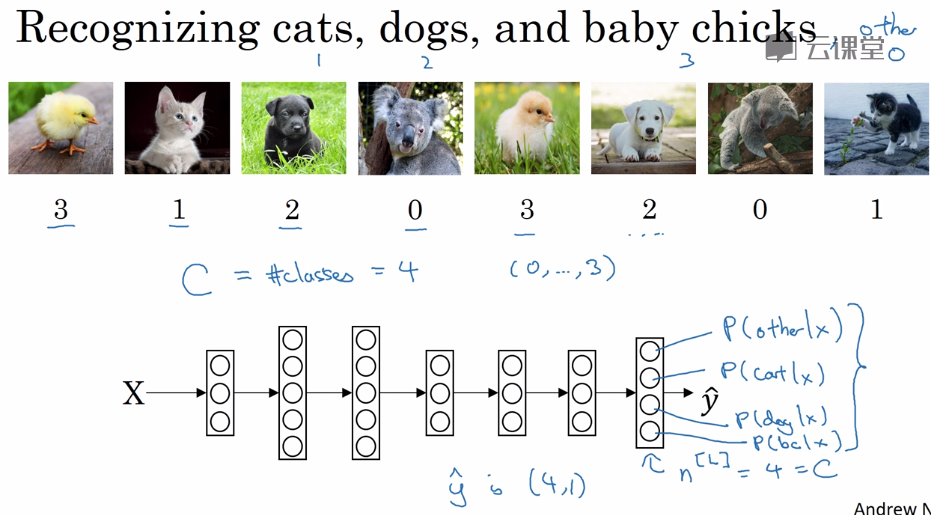
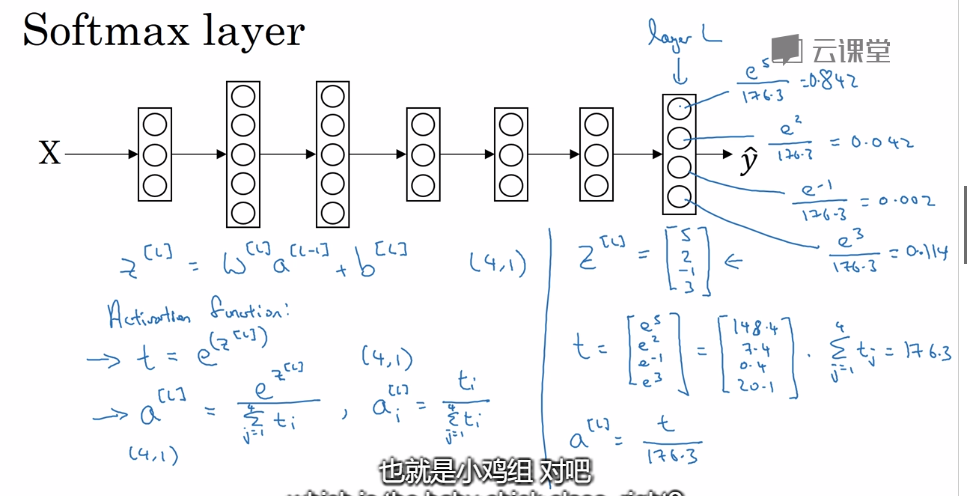
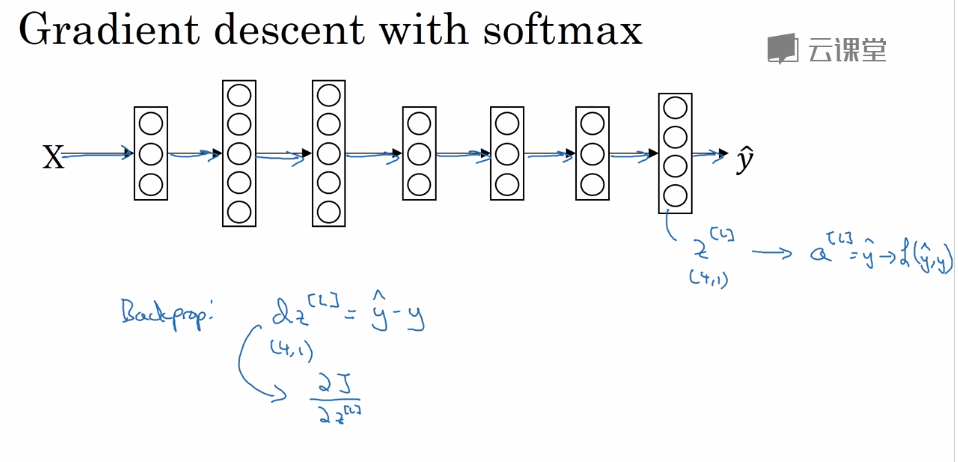
softmax回归,最后一层输出的是概率,和为1