1. 前言
熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。
在信息论里则叫信息量,即熵是对不确定性的度量。从控制论的角度来看,应叫不确定性。信息论的创始人香农在其著作《通信的数学理论》中提出了建立在概率统计模型上的信息度量。他把信息定义为“用来消除不确定性的东西”。在信息世界,熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少。
当我们不知道某事物具体状态,却知道它有几种可能性时,显然,可能性种类愈多,不确定性愈大。不确定性愈大的事物,我们最后确定了、知道了,这就是说我们从中得到了愈多的信息,也就是信息量大。所以,熵、不确定性、信息量,这三者是同一个数值。
两种可能性:最简单的是只有两种可能性,非此即彼,我们就以这种事物的信息量为单位,叫1比特(bit)。
4种可能性:用二分法,分为2组,我们要非此即彼地确定2次,才能确定其状态,所以含有2比特信息量。
如果可能性数目有2的n次方(N=2^n):那就是n比特,即信息量等于可能性数目N的‘以2为底的对数’:H=㏒2(N)=㏒(N)/㏒(2)。后一个等号说明,以2为底的对数㏒2可用普通对数㏒(以10为底)来计算,即用N的普通对数除2的普通对数。N=3种可能性时,信息量H=㏒(3)/㏒(2)=1.585。只要有函数型计算器,我们就可以进行以下简单实例的验算。
我们现在不是讨论事物本身的信息量,而是讨论描述事物的文字符号包含的信息量。先讨论比较简单的数字符号。
二进制数:二进制数只有2个符号:0和1。一位二进制数有2种可能性,其信息量是1比特。n位二进制数可记N=2^n个不相等的数,含有n比特信息,所以每位数字的信息量还是1。
十进制数:十进制数字有10个,每位数字的信息量是㏒(10)/ ㏒(2)=1/0.301=3.32。不难验证所有十进制数,每位数字的信息量都是3.32,例如3位数共1000个,信息量是㏒(1000)/ ㏒(2)=3*3.32。而十六进制的每位数字的信息量是4。
事情好像很简单,其实不然。试考虑还没有发明数字的远古人,他用刻画来记数,用刻n画的方法记数目n。10以内的数平均每个数要刻(1+10)/2=5.5画,每画的平均信息量是3.32/5.5=0.604,而100以内的数平均每个数(1+100)/2=50.5画,每画的平均信息量只有6.64/50. 5=0.132。因为古人刻的每一画是没有次序或位置的区别的,所以每一画的信息量变化很大,数值则很小。次序或位置非常重要,罗马字和我国古代的数码,也是短画,但要讲究位置组合,每画所含的信息量就大大提高了。注意,我们以后讨论的文字信号,都是有次序的。
这样,文字信号的信息量H是信号个数n的以2为底的对数: H=㏒(n)/ ㏒(2)。英文有 26个字母,每个字母的信息量H=㏒(26)/ ㏒(2)=4.700。汉字个数不定,算1000个时等于3*3.32=9.96,算作一万、十万时则分别为13.28、16.60。我们能随意增加大量一辈子也用不到的汉字,来无限地增加每个汉字的信息量?这当然不合理。原来信息量不能无条件地按符号的个数来计算,只有各符号的可能性一样,都等于1/n时才行。数字符号就满足这样的条件。事实上信息量应按符号的可能性(数学上叫概率大小)来计算,它是概率的负对数。对于二进制数,每个符号的概率都等于1/2,按负对数计算:-㏒(1/n)=-(㏒(1)- ㏒(n))=-(0-㏒(n))=㏒(n)。这就是我们前面使用的公式的来源。如果符号i的概率pi不等于1/n,则Hi=-㏒(pi)。因为各个符号的概率pi不相等,对于总体来说,平均信息量就是它们的加权平均H=-∑pi㏒(pi),这里累加符号∑表示对所有 i 进行累计。(以上式子除以㏒(2),就可化为以比特为单位了)。
2. 熵的定义
如果有一枚理想的硬币,其出现正面和反面的机会相等,则抛硬币事件的熵等于其能够达到的最大值。我们无法知道下一个硬币抛掷的结果是什么,因此每一次抛硬币都是不可预测的。因此,使用一枚正常硬币进行若干次抛掷,这个事件的熵是一比特,因为结果不外乎两个——正面或者反面,可以表示为0,
1编码,而且两个结果彼此之间相互独立。若进行n次独立实验,则熵为n,因为可以用长度为n的比特流表示。[1]但是如果一枚硬币的两面完全相同,那个这个系列抛硬币事件的熵等于零,因为结果能被准确预测。现实世界里,我们收集到的数据的熵介于上面两种情况之间。
另一个稍微复杂的例子是假设一个随机变量X,取三种可能值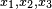 ,概率分别为
,概率分别为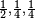 ,那么编码平均比特长度是:
,那么编码平均比特长度是: 。其熵为3/2。
。其熵为3/2。
因此熵实际是对随机变量的比特量和顺次发生概率相乘再总和的数学期望。
熵在信息论中的定义推导过程如下:
信源的不确定性:信源发出的消息不肯定性越大,收信者获取的信息量就越大。如果信源发送的消息是确切的,则对收信者来说没有任何价值(没有信息量)。衡量不确定性的方法就是考察信源X的概率空间。X包含的状态越多,状态Xi的概率pi越小,则不确定性越大,所含有的信息量越大。
不确定程度用H(X)表示,简称不确定度, 用概率的倒数的对数来度量不肯定程度。一般写成H(X) = log(1/p) = -log(p).
自信息量:一个事件(消息)本身所包含的信息量,由事件的不确定性决定的。
即随机事件Xi发生概率为P(xi),则随机事件的自信息量定义为:

表示事件Xi发生后能提供的信息量。事件不同,则他的信息量也不同,所以自信息量是一个随机变量。不能用来表征整个信源的不肯定性。可以用平均自信息量来表征整个信源的不肯定性。
定义信息量为概率的负对数,是很合理的。试考虑一个两种可能性的事物,仅当可能性相等时,不确定性最大,最后我们知道了某一可能性确实发生了,也得到最大的信息量。如果其中某一个可能性很大(另一个必然很小),不确定性就很小。如果可能性大到1,也就是必然要发生的,因为1的对数为0,我们从知道它的发生这件事得到的信息也为0。
(1)非负性
(2)随机性 是随机变量
(3)单调性 概率大自信息量小
(4)随机事件的不确定性在数量上等于它的自信息量。
(5)单位
以2为底,记作lb,单位比特(bit);
以e为底,记作ln,单位奈特(nat);
以10为底,记作lg,单位哈脱来(hat)。
信息熵:随机变量自信息量I(xi)的数学期望(平均自信息量),用H(X)表示,即为熵的定义:

即一个值域为{x1, ..., xn}的随机变量 X 的熵值 H 定义为:
-
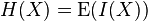 ,
,
其中,E 代表了期望函数,而 I(X) 是 X 的信息量(又称为信息本体)。I(X) 本身是个随机变量。如果 p 代表了 X 的机率质量函数(probability mass function),则熵的公式可以表示为:
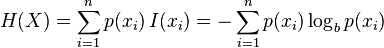
在这里 b 是对数所使用的底,通常是 2, 自然常数 e,或是10。当b = 2,熵的单位是bit;当b = e,熵的单位是 nat;而当 b = 10,熵的单位是 dit。
pi = 0时,对于一些i值,对应的被加数0 logb 0的值将会是0,这与极限一致。
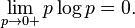
3. 范例
如果有一个系统S内存在多个事件S = {E1,...,En},每个事件的机率分布 P = {p1, ..., pn},则每个事件本身的信息量为:
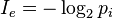 (对数以2为底,单位是比特(bit))
(对数以2为底,单位是比特(bit))
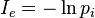 (对数以
(对数以 为底,单位是纳特/nats)
为底,单位是纳特/nats)
如英语有26个字母,假如每个字母在文章中出现次数平均的话,每个字母的讯息量为:
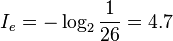
而汉字常用的有2500个,假如每个汉字在文章中出现次数平均的话,每个汉字的信息量为:
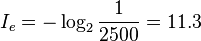
实际上每个字母和每个汉字在文章中出现的次数并不平均,比方说较少见字母(如z)和罕用汉字就具有相对高的信息量。但上述计算提供了以下概念:使用书写单元越多的文字,每个单元所包含的讯息量越大。
熵是整个系统的平均消息量,即:

英语文本数据流的熵比较低,因为英语很容易读懂,也就是说很容易被预测。即便我们不知道下一段英语文字是什么内容,但是我们能很容易地预测,比如,字母e总是比字母z多,或者qu字母组合的可能性总是超过q与任何其它字母的组合。如果未经压缩,一段英文文本的每个字母需要8个比特来编码,但是实际上英文文本的熵大概只有4.7比特。如果压缩是无损的,即通过解压缩可以百分之百地恢复初始的消息内容,那么压缩后的消息携带的信息和未压缩的原始消息是一样的多。而压缩后的消息可以通过较少的比特传递,因此压缩消息的每个比特能携带更多的信息,也就是说压缩信息的熵更加高。熵更高意味着比较难于预测压缩消息携带的信息,原因在于压缩消息里面没有冗余,即每个比特的消息携带了一个比特的信息。香农的信息理论揭示了,任何无损压缩技术不可能让一比特的消息携带超过一比特的信息。消息的熵乘以消息的长度决定了消息可以携带多少信息。
4. 信息增益
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准。这个标准被称为“信息增益(information gain)”。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低(或者说,样本按照某属性划分时造成熵减少的期望)。在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量
更精确地讲,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:
5. 熵的特性
1、熵均大于等于零,即,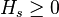 。
。
2、设N是系统S内的事件总数,则熵 。当且仅当p1=p2=...=pn时,等号成立,此时系统S的熵最大。
。当且仅当p1=p2=...=pn时,等号成立,此时系统S的熵最大。
3、联合熵: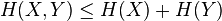 ,当且仅当X,Y在统计学上相互独立时等号成立。
,当且仅当X,Y在统计学上相互独立时等号成立。
4、条件熵: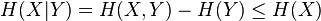 ,当且仅当X,Y在统计学上相互独立时等号成立。
,当且仅当X,Y在统计学上相互独立时等号成立。
5. 抛硬币的熵

抛硬币的熵H(X)(即期望自信息),以比特度量,与之相对的是硬币的公正度
Pr(X=1).
注意图的最大值取决于分布;在这里,要传达一个公正的抛硬币结果至多需要1比特,但要传达一个公正的抛骰子结果至多需要log2(6)比特。