· 法向量
1.怎么去找点云里面每一个点的法向量呢?
什么是法向量呢?
如果能用一个曲面去拟合数据
应用:
目标检测
分割
怎么找法向量呢(其实是PCA的一个应用,找的是最没用的向量)
所谓最没用的点,言外之意就是数据投影在这些向量上面数据为0
具体操作步骤:
1.先选取一个点,我们想要找他的法向量
2.然后找这个点的邻域,因为只有确定了邻域我们才能知道这个点的法向量嘛
3.选出邻域以后在邻域里面的这些点做PCA
4.然后选取的法向量其实是最不显著的向量,也就是特征值最小的特征向量
5.曲率:
找到一个平面,使得能与这个平面拟合的点投影到平面的法向量上的投影和最小
一个向量跟一个向量的乘积其实就是一个向量在另一个向量上的投影
怎么选邻域?
如果邻域半径非常大,估算出来的法向量会相对比较平滑,如果是非常精细的结构,那所求的法向量不太准确。
如果邻域非常小,可以比较精确地描述小范围,也会收到zhaosheng的影响
如果点云带颜色的,或者反射率,但选颜色一样的作为邻域
有一个第四节课会说到的RANSAC
深度学习
带加权的法向量运算
凡是不知道怎么做的事情,就凡事丢给神经网络

Scale 就是做了三层
小的特征感知域比较小
大的特征感知域比较大
感知域一个特征点或一个结果,一个scale越大,能看到的东西越多
点云里的法向量估计也可以用deep learning去做
· 滤波
应用广泛
·噪声去除

使场景变得更为干净
·降采样

例如一开始有一千个点描述一个场景,但实际上我用一百个点就可以描述了,将一千个点变为一百个点的过程就是降采样。
保存对象特征的同时减少点的运算
·上采样
没有的东西我们把它创造出来
就是估算,比较少用

好处是能把车的轮廓较好的保存
MED:中值滤波
AVE:平均值滤波
##点云上的噪声去除
第一个方法:Radius Outlier Removal
有很多点云,对某一个点,都划定一个邻域,就是一个半径为d的圆。如果是三维,就可以是球
然后我们数一下每一个点在半径为d的邻域里有几个点,如果这个点的数量少于一定数值,就把他去掉
这个数量由你规定。
实用的算法,实现简单

第二个方法:Statistical Outlier Removal
统计版的removal,就是升级版的Radius Outlier Removal
1.找每个点的邻域,还是画圆,但是这时候不熟点的数量,而是算邻居离我自己的距离dij
i是我自己这个点,j是邻居
然后算距离的平均值和方差
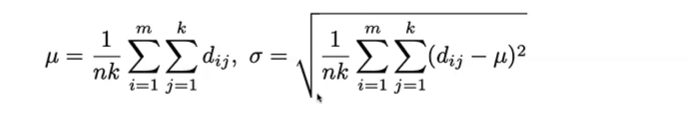
就可以得到平均下来这些dij应该是怎样的,还是同样找,如果邻居的距离大于平均值3∑的就去掉。
阈值是动态的。
##voxel grid降采样
功能效果:降低点的数量,使在后面的算力更少。
操作步骤:
举例子,一个框框里有很多个点,你可以先在原本的框框里划分,然后找一个点出来。
这个特别的点要怎么找呢?是随便找吗?
要么随便找,要么平均值
如何使降采样过程更高效?
如果有很多点都落在一个框框里,那就取框框里的平均值作为降采样的结果。
每个点都有一个标签,比如这个点是一个人的点或一个是车的点,这种是无法求平均值的。
此时会进行投票
随意选点容易错误

下面是一个类似于一个伪代码的做降采样的过程
首先给一堆n维的点
然后怎么画框框呢?要先观察,看这些点能不能用一个巨大的框框表现
只有先得到大框才能继续划分小框
求max,每个坐标都要求
求voxel grid 的分辨率
也就是小格子要多大
算每个点会落在哪个格子上面去
flow操作?选取离他最近的整数

最后做一个排序,得到的结果的意思是有四个点落在h=0这个格子里,有三个点落在h=3这个格子里。
在实现降采样的过程中,要注意一些问题:
①假如我把小格子的分辨率设的特别小,然而我们需要处理的点又很大。防止溢出问题
②排序问题,要用小于,不要用小于等于
排序算法需要N*logN 但是这个N是很大的。对十几万个点进行降采样是需要好几毫秒的,那我们能不能加速这个过程呢?其实是可以的。
利用一个特性:空间中大部分的空间是没有点的。
如果我们有一万个点,假设说我们最后得到95个点,如果我们有个神奇的函数,投射到一百个容器里面去,那就取非空的容器。
那这个神奇的函数是什么呢?
hash表
那具体来说怎么操作呢?
前面四步准确来说跟voxel grid 是一样的。
①算最大值、最小值,取出一个最大的框框
②找到分辨率
③算一下voxel grid 的每个方向上面的格子的数量
算每个点在voxel grid 的位置,也就是h
定义一个hash函数,将三个方向上的h(hx,hy,hz)映射成一个数字
这个数字代表了这个容器的位置。

hash函数有可能将两个隔得很远的点放到一个容器里面去。
两个点经过hash函数后是一样的,但他们其实距离是很远的,这就是冲突。
所以如何解决冲突的hash函数呢?
就把被冲突的容器的点先释放出去,把新来的点占到容器里。
检测冲突:值一样,但是那个不一样