目录
1、合理的批次处理时间
2、合理的kafka拉取数据
3、缓存反复使用的Dstream(RDD)
4、其他一些优化策略
5、结果
1、合理的批次处理时间
关于Spark Streaming的批处理时间设置是非常重要的,Spark Streaming在不断接收数据的同时,需要处理数据的时间,所以如果设置过段的批处理时间,会造成数据堆积,即未完成的batch数据越来越多,从而发生阻塞。
另外值得注意的是,batchDuration本身也不能设置为小于500ms,这会导致Spark Streaming进行频繁地提交作业,造成额外的开销,减少整个系统的吞吐量;相反如果将batchDuration时间设置得过长,又会影响整个系统的吞吐量。
如何设置一个合理的批处理时间,需要根据应用本身、集群资源情况,以及关注和监控Spark Streaming系统的运行情况来调整,重点关注监控界面中的Total Delay,如图1所示。
2、合理的kafka拉取数据
对于数据源是Kafka的Spark Streaming应用,在Kafka数据频率过高的情况下,调整这个参数是非常必要的。我们可以改变spark.streaming.kafka.maxRatePerPartition参数的值来进行上限调整,默认是无上限的,即Kafka有多少数据,Spark Streaming就会一次性全拉出,但是上节提到的批处理时间是一定的,不可能动态变化,如果持续数据频率过高,同样会造成数据堆积、阻塞的现象。
所以需要结合batchDuration设置的值,调整spark.streaming.kafka.maxRatePerPatition参数,注意该参数配置的是Kafka每个partition拉取的上限,数据总量还需乘以所有的partition数量,调整两个参数maxRatePerPartition和batchDuration使得数据的拉取和处理能够平衡,尽可能地增加整个系统的吞吐量,可以观察监控界面中的Input Rate和Processing Time,如图2所示。
3、缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream如果被反复使用,最好利用cache()函数将该数据流缓存起来,防止过度地调度资源造成的网络开销。可以参考并观察Scheduling Delay参数,如图3所示。
4、其他一些优化策略
除了以上针对Spark Streaming和Kafka这个特殊场景方面的优化外,对于前面提到的一些常规优化,也可以通过下面几点来完成。
设置合理的GC方式:使用–conf "spark.executor.extraJavaOptions=-XX:+UseConc MarkSweepGC"来配置垃圾回收机制。
设置合理的parallelism:在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前面讲过Spark中的partition和Kafka中的Partition是一一对应的,一般默认设置为Kafka中Partition的数量。
设置合理的CPU资源数:CPU的core数量,每个Executor可以占用一个或多个core,观察CPU使用率(Linux命令top)来了解计算资源的使用情况。例如,很常见的一种浪费是一个Executor占用了多个core,但是总的CPU使用率却不高(因为一个Executor并不会一直充分利用多核的能力),这个时候可以考虑让单个Executor占用更少的core,同时Worker下面增加更多的Executor;或者从另一个角度,增加单个节点的worker数量,当然这需要修改Spark集群的配置,从而增加CPU利用率。值得注意是,这里的优化有一个平衡,Executor的数量需要考虑其他计算资源的配置,Executor的数量和每个Executor分到的内存大小成反比,如果每个Executor的内存过小,容易产生内存溢出(out of memory)的问题。
高性能的算子:所谓高性能算子也要看具体的场景,通常建议使用reduceByKey/aggregateByKey来代替groupByKey。而存在数据库连接、资源加载创建等需求时,我们可以使用带partition的操作,这样在每一个分区进行一次操作即可,因为分区是物理同机器的,并不存在这些资源序列化的问题,从而大大减少了这部分操作的开销。例如,可以用mapPartitions、foreachPartitions操作来代替map、foreach操作。另外在进行coalesce操作时,因为会进行重组分区操作,所以最好进行必要的数据过滤filter操作。
Kryo优化序列化性能:我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等)。
5、结果
通过以上种种调整和优化,最终我们想要达到的目的便是,整个流式处理系统保持稳定,即Spark Streaming消费Kafka数据的速率赶上爬虫向Kafka生产数据的速率,使得Kafka中的数据尽可能快地被处理掉,减少积压,才能保证实时性,如图4所示。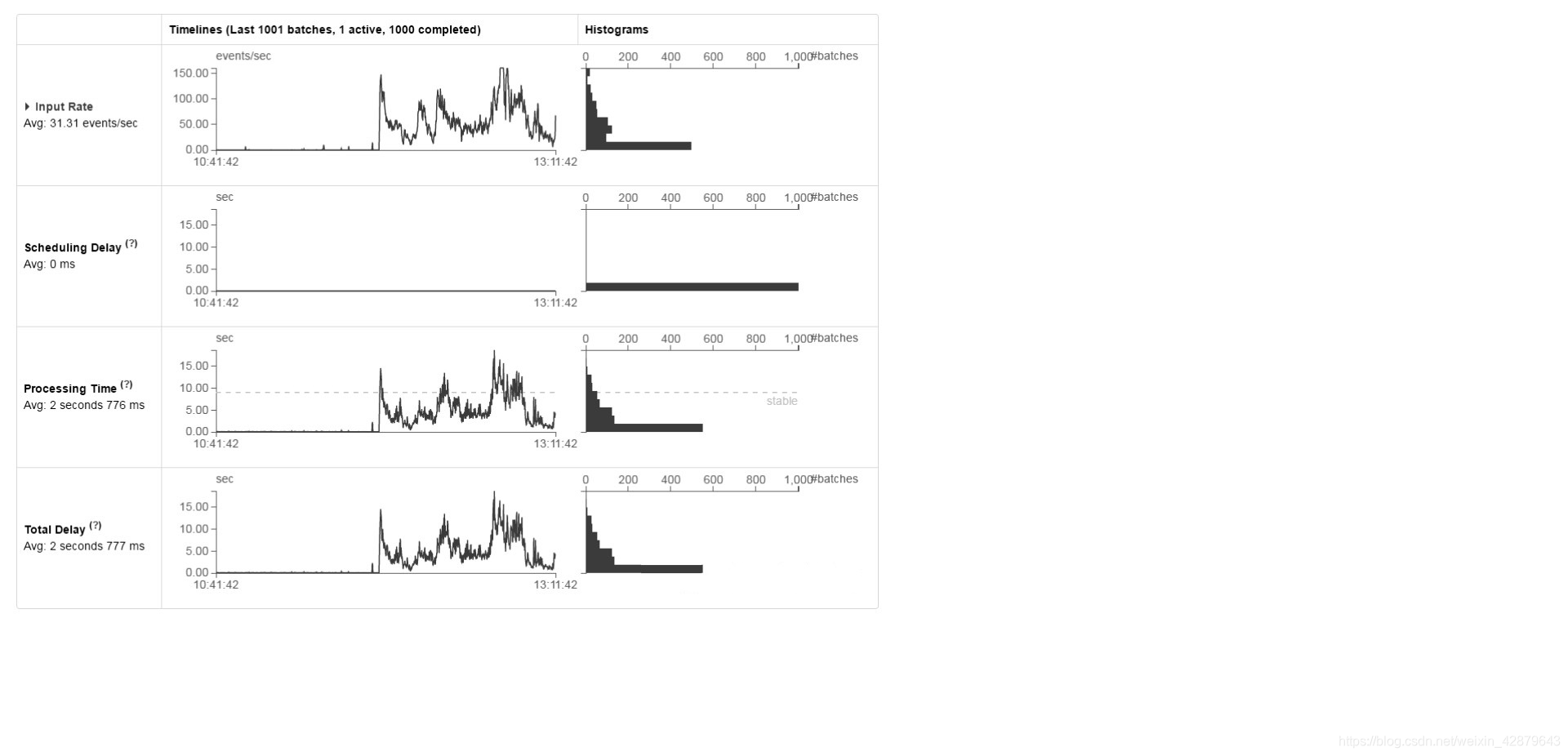
转载于:https://blog.csdn.net/weixin_42879643/article/details/103593232?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
END