DisCrete Versus Real AdaBoost
关于Discrete 和Real AdaBoost 可以参考博客:http://www.cnblogs.com/jcchen1987/p/4581651.html
本例是Sklearn网站上的关于决策树桩、决策树、和分别使用AdaBoost—SAMME和AdaBoost—SAMME.R的AdaBoost算法在分类上的错误率。这个例子基于Sklearn.datasets里面的make_Hastie_10_2数据库。取了12000个数据,其他前2000个作为训练集,后面10000个作为了测试集。
原网站链接:here
代码如下:
#- *- encoding:utf-8 -*-
"""
Sklearn adaBoost @Dylan
2016/9/1
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import zero_one_loss
from sklearn.ensemble import AdaBoostClassifier
import time
a=time.time()
n_estimators=400
learning_rate=1
X,y=datasets.make_hastie_10_2(n_samples=12000,random_state=1)
X_test,y_test=X[2000:],y[2000:]
X_train,y_train=X[:2000],y[:2000]
dt_stump=DecisionTreeClassifier(max_depth=1,min_samples_leaf=1)
dt_stump.fit(X_train,y_train)
dt_stump_err=1.0-dt_stump.score(X_test,y_test)
dt=DecisionTreeClassifier(max_depth=9,min_samples_leaf=1)
dt.fit(X_train,y_train)
dt_err=1.0-dt.score(X_test,y_test)
ada_discrete=AdaBoostClassifier(base_estimator=dt_stump,learning_rate=learning_rate,n_estimators=n_estimators,algorithm='SAMME')
ada_discrete.fit(X_train,y_train)
ada_real=AdaBoostClassifier(base_estimator=dt_stump,learning_rate=learning_rate,n_estimators=n_estimators,algorithm='SAMME.R')
ada_real.fit(X_train,y_train)
fig=plt.figure()
ax=fig.add_subplot(111)
ax.plot([1,n_estimators],[dt_stump_err]*2,'k-',label='Decision Stump Error')
ax.plot([1,n_estimators],[dt_err]*2,'k--',label='Decision Tree Error')
ada_discrete_err=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_discrete.staged_predict(X_test)):
ada_discrete_err[i]=zero_one_loss(y_pred,y_test) ######zero_one_loss
ada_discrete_err_train=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_discrete.staged_predict(X_train)):
ada_discrete_err_train[i]=zero_one_loss(y_pred,y_train)
ada_real_err=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_real.staged_predict(X_test)):
ada_real_err[i]=zero_one_loss(y_pred,y_test)
ada_real_err_train=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_real.staged_predict(X_train)):
ada_discrete_err_train[i]=zero_one_loss(y_pred,y_train)
ax.plot(np.arange(n_estimators)+1,ada_discrete_err,label='Discrete AdaBoost Test Error',color='red')
ax.plot(np.arange(n_estimators)+1,ada_discrete_err_train,label='Discrete AdaBoost Train Error',color='blue')
ax.plot(np.arange(n_estimators)+1,ada_real_err,label='Real AdaBoost Test Error',color='orange')
ax.plot(np.arange(n_estimators)+1,ada_real_err_train,label='Real AdaBoost Train Error',color='green')
ax.set_ylim((0.0,0.5))
ax.set_xlabel('n_estimators')
ax.set_ylabel('error rate')
leg=ax.legend(loc='upper right',fancybox=True)
leg.get_frame().set_alpha(0.7)
b=time.time()
print('total running time of this example is :',b-a)
plt.show()
输出结果
1.运行时间:
total running time of this example is : 6.1493518352508545
2.对比图:
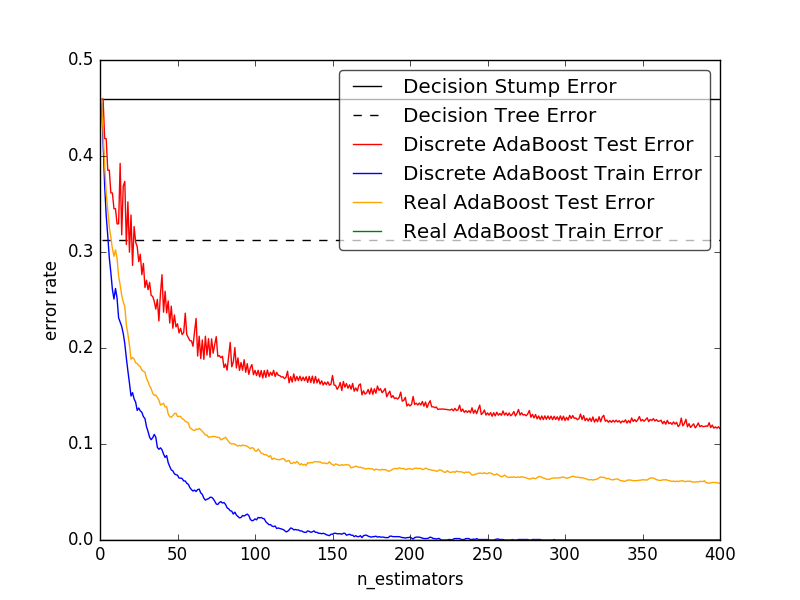
从图中可以看出:弱分类器(Decision Tree Stump)单独分类的效果很差,错误率将近50%,强分类器(Decision Tree)的效果要明显好于他。但是AdaBoost的效果要明显好于这两者。同时在AdaBoost中,Real AdaBoost的分类效果更佳好一点。