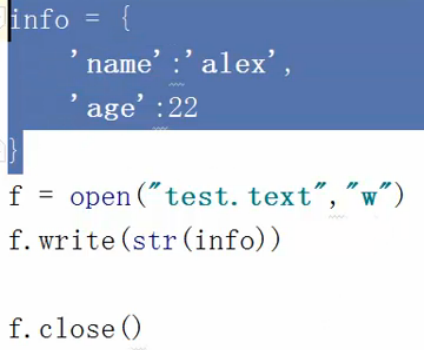
类似vmware虚拟机里的虚拟主机挂起操作,把当前内存拷贝成文件保存。
上面的这种操作就叫内存序列化:如下图:
有序列化就有反序列化,要把文件里的东西再恢复成字典:eval把字符串变成字典。

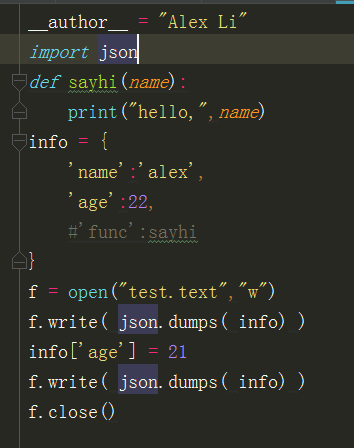
但是上面的这种方法很low,用的方法很复杂,我们要用jason的方法:下面是序列化的方法:json.dumps()

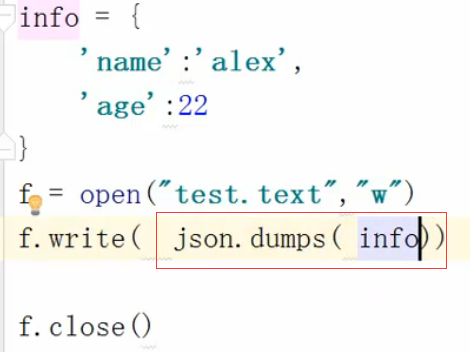
反序列化如下图:json.loads()

json的主要作用是不用语言的数据交互,所以json不支持复杂的数据类型。




但是我们就想处理复杂的数据类型,怎么办呢?我们可以用pickle
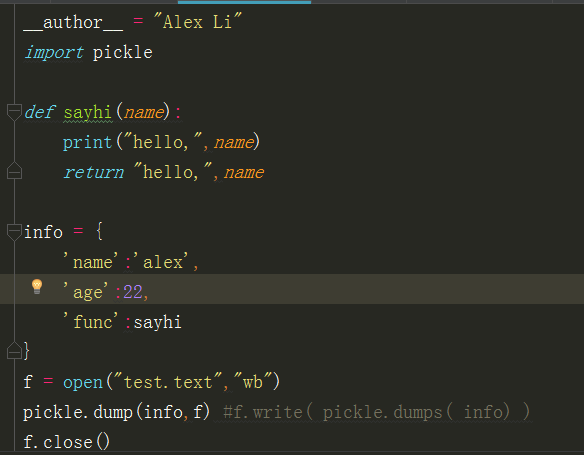
import pickle,但是注意pickle处理的全是bytes数据类型,不能用字符串。其余的写法跟json一模一样。
序列:pickle.dumps()
反序列:pickle.loads()
导入pickle模块
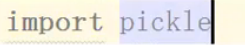

文件test.text变成二进制文件:
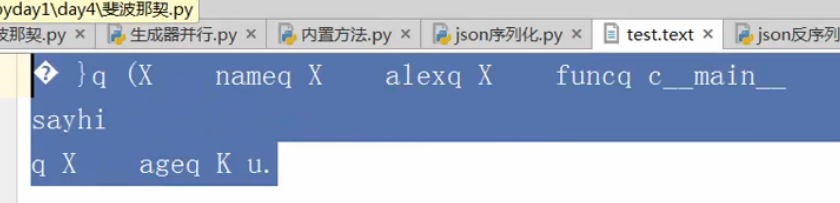
反序列:
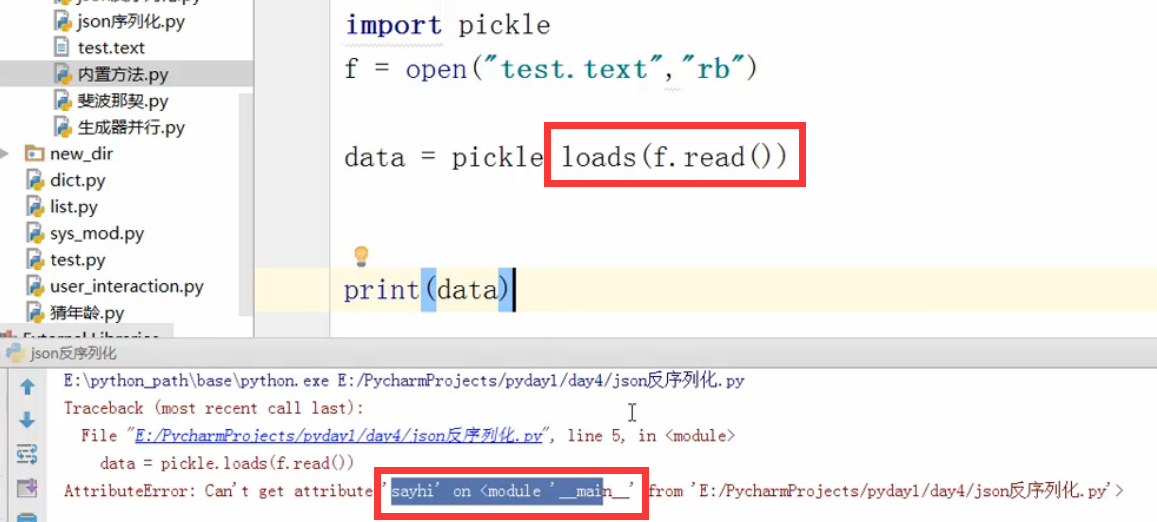
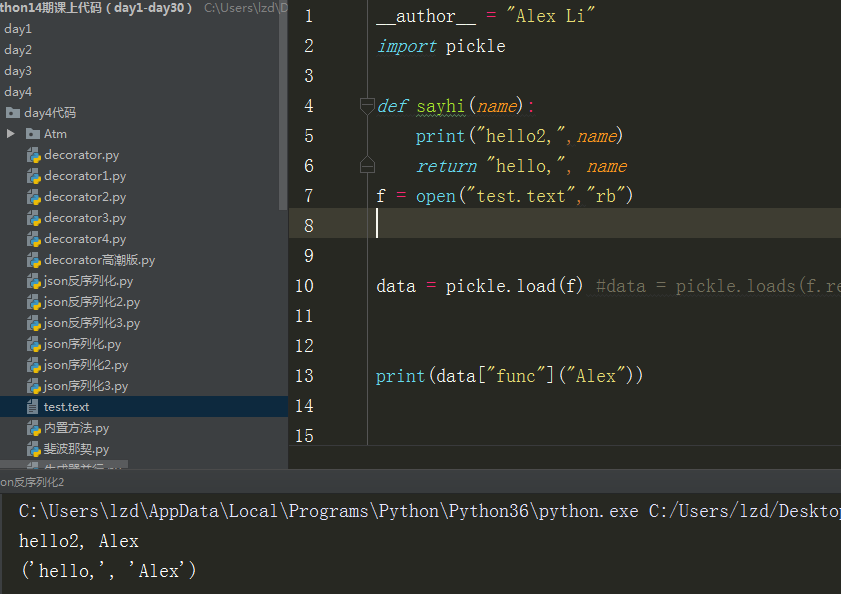
虽然反序列是成功了,但是在新的这个脚本里,并没有sayhi这个函数,所以你打印,肯定报错。我们必须做如下处理:
把序列化里的sayhi()这个函数copy过来:

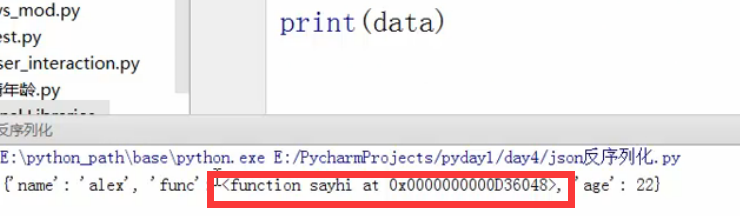
这个时候就不报错了。
我们也可以给字典[func]进行取值。
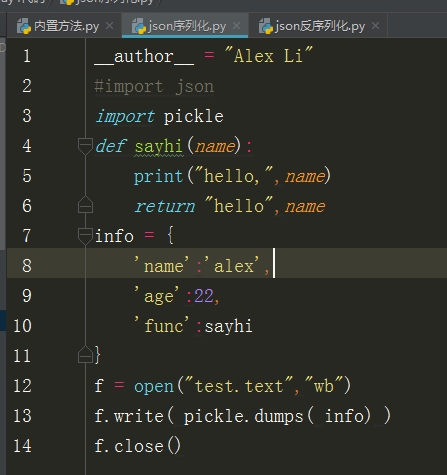
序列化程序如下:
反序列化程序如下:
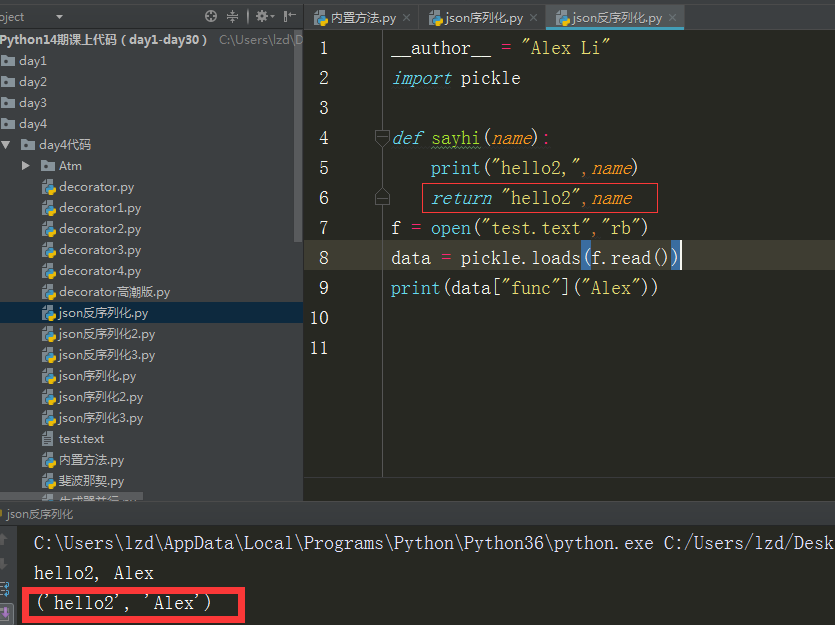
但是要注意,pickle只限于PYTHON里使用,跟java不能通用,但是json是可以在python和java里通用的。
其实pickle也有其他的方法,dump和load,见如下:
下面的写法一模一样
pickle.dump(info,f) ============f.write( pickle.dumps( info) )
data = pickle.load(f) =============data = pickle.loads(f.read())
序列化:
反序列化程序如下:
如果这个时候,我们可能存在dumps两次的情况:

我们来看下反序列化:反复报错!
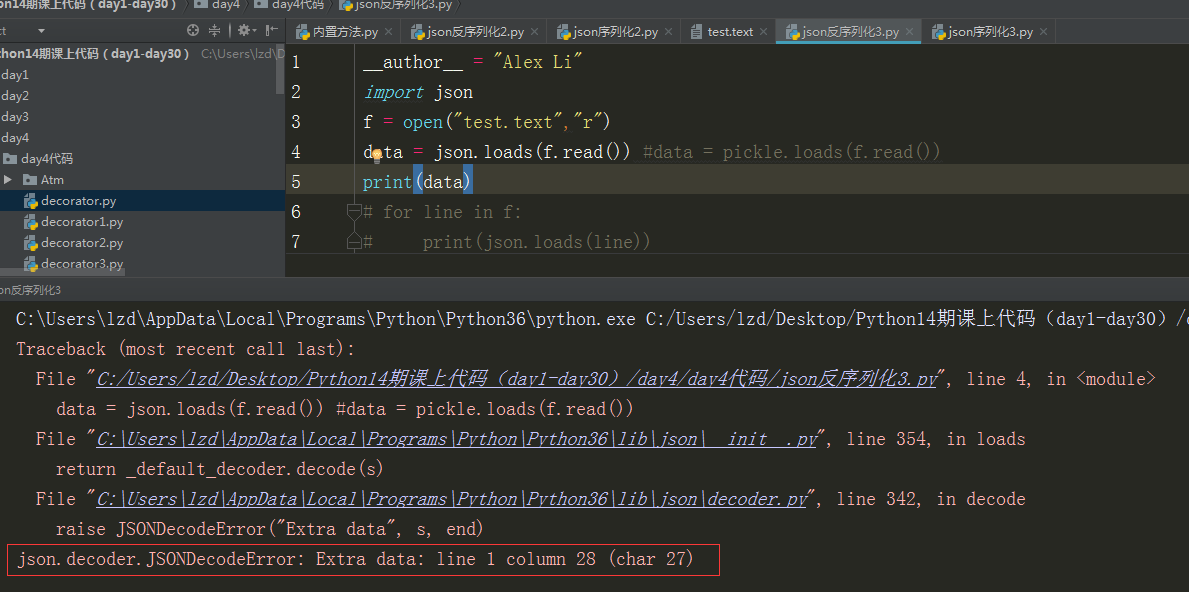
在py2里是可以dump好几次,然后load好几次,(而且先dump进去的,先load出来,不过这样很容易出错),但是在py3里是不允许了。你记住dump一次,load一次。
如果你真想dump好几个,那么就dump成好几个文件!!!