目录
链式法则
逻辑回归的正、反向传播
逻辑回归的正、反向传播案例
全连接神经网络的正、反向传播
全连接神经网络的正、反向传播案例
参考资料
|
链式法则 |
类型一:
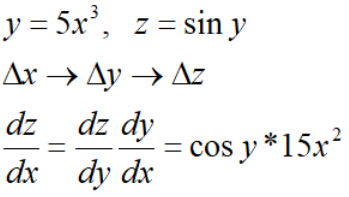
类型二:

类型三:

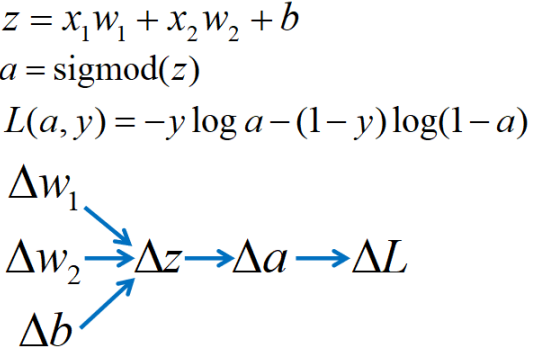
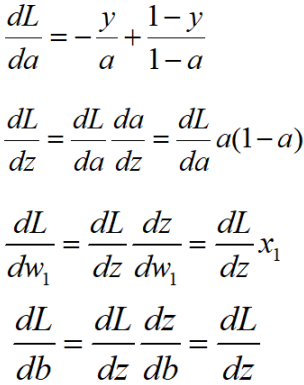
|
逻辑回归的正、反向传播 |
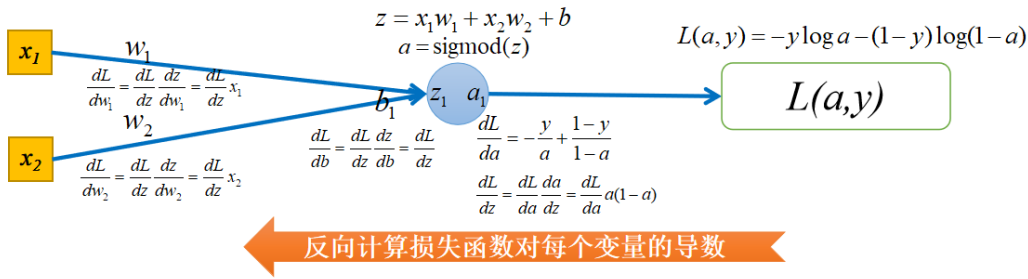
逻辑回归可以看做最简单的神经网络,他只有一个神经元,损失函数选择的是对数损失,他的正向传播过程如下图所示:

逻辑回归可以看做最简单的神经网络,他只有一个神经元,损失函数选择的是对数损失,他的正向传播过程如下图所示:
接下来反向计算损失函数对每个变量的导数。如果你想直接求L对w1的导数是会产生很多重复计算的,回忆下链式求导法则就知道了。因此我们从右向左求导数,这样可以避免重复计算,也就是梯度反向传播的过程,如下图所示:

然后就可以更新w和b,更新模型了,即
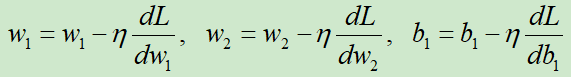
非常简单吧,下面我们通过一个案例演示,看一下如何梯度反向传播(BP算法)是如何降低训练误差的。
|
逻辑回归的正、反向传播案例 |
假设最开始初始化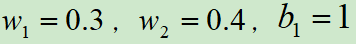 ,本轮训练样本为[(2,3),0],损失函数选用的对数损失,如下图所示:
,本轮训练样本为[(2,3),0],损失函数选用的对数损失,如下图所示:

可以看出在当前模型参数下,正向传播后,损失为2.859
接下来,使用BP算法更新模型参数,如下图所示:

如果再进行正向传播计算损失的话,可以发现,损失从2.859降低到1.682:

|
全连接神经网络的正、反向传播 |
上面举了一个单神经元使用对数损失做分类的例子,这里为了描述全面,阐述一下多神经元做分类的情况,下图是全连接神经网络正向传播的过程:

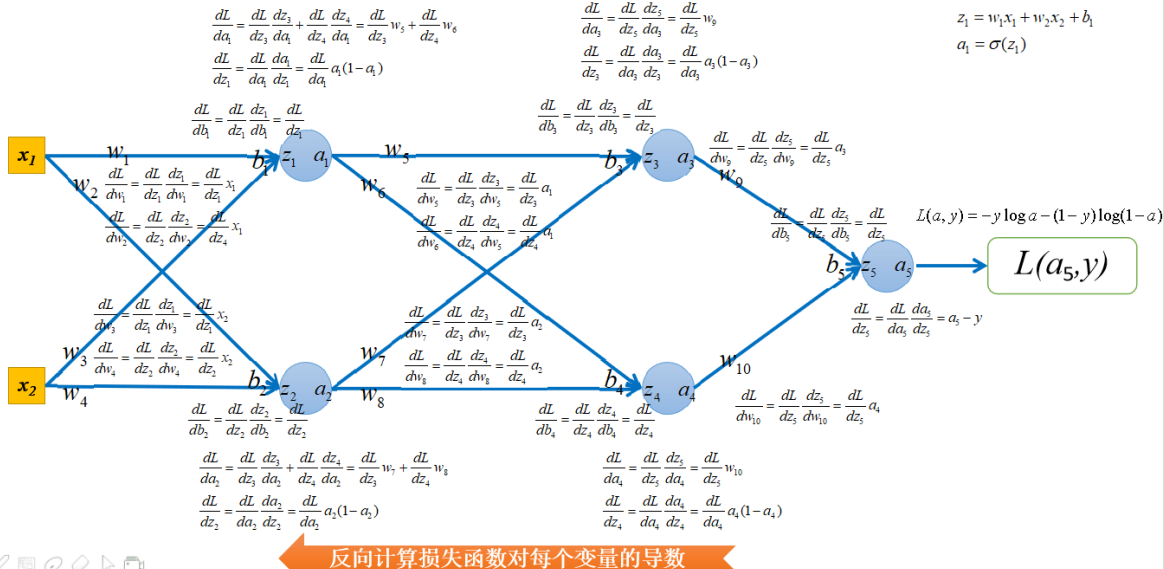
接下来反向计算损失函数对每个变量的导数。也就是梯度反向传播的过程,如下图所示:
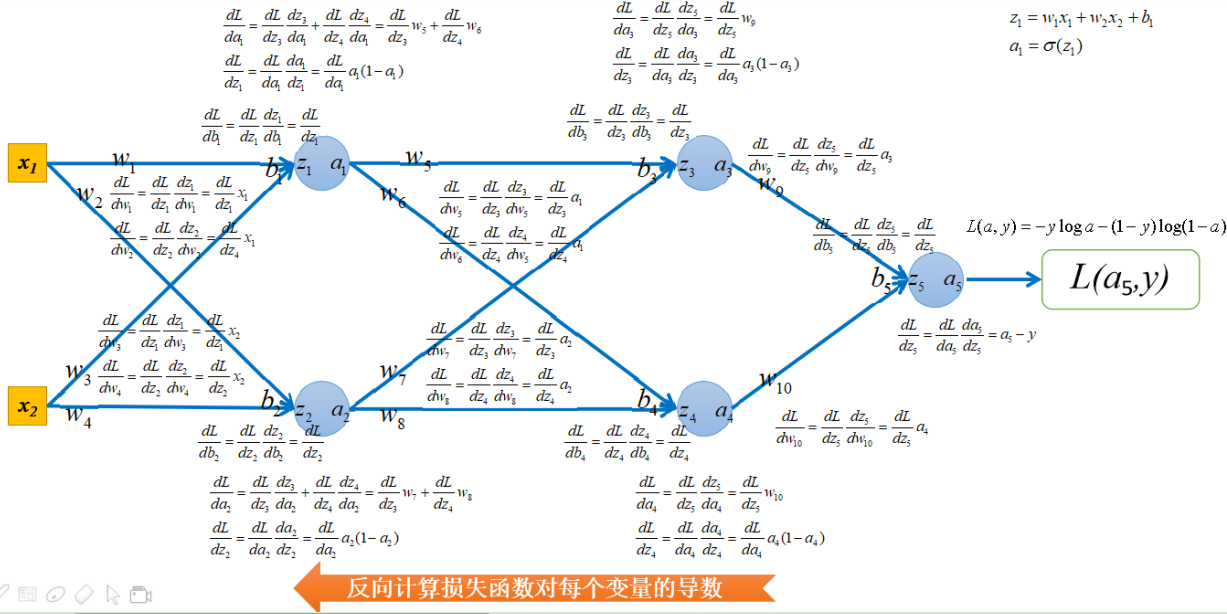
然后就可以更新w和b,更新模型了,即
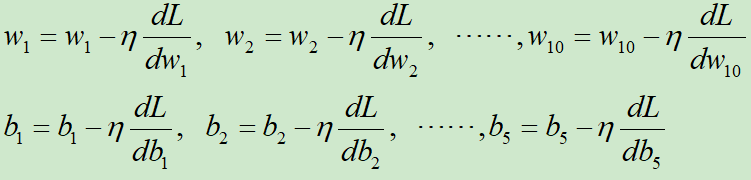
|
全连接神经网络的正、反向传播案例 |
假设最开始初始化所有w都等于0.5,所有的b都等于1,本轮训练样本为[(2,3),0],损失函数选用的对数损失,如下图所示:
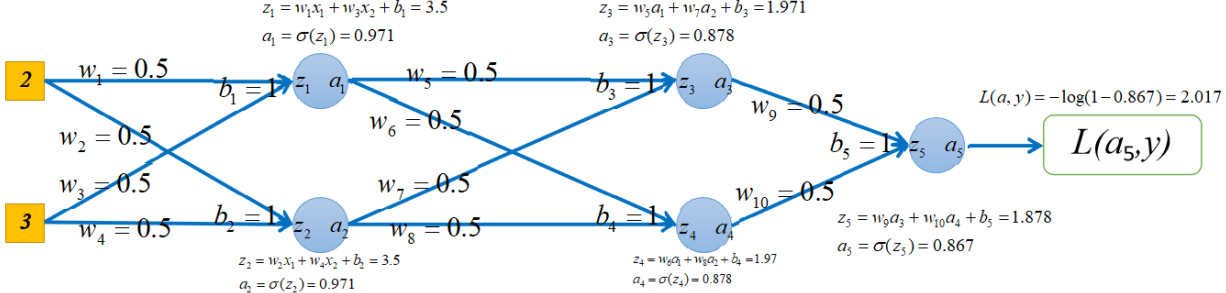
可以看出在当前模型参数下,正向传播后,损失为2.017
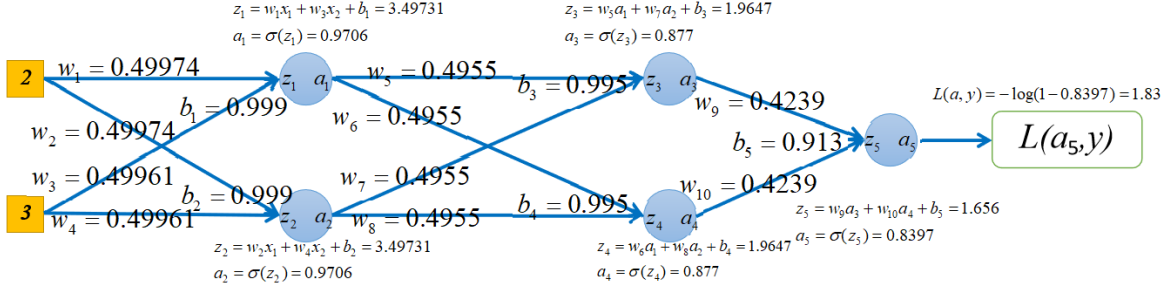
接下来,使用BP算法更新模型参数,如下图所示:

如果再进行正向传播计算损失的话,可以发现,损失从2.017降低到1.83:
对应代码:


import numpy as np
def sigmod(x):
return 1/(1+np.exp(-(x)))
w1_1 = np.array([0.5,0.5])
w1_2 = np.array([0.5,0.5])
w2_1 = np.array([0.5,0.5])
w2_2 = np.array([0.5,0.5])
w3_1 = np.array([0.5,0.5])
b1_1 = 1
b1_2 = 1
b2_1 = 1
b2_2 = 1
b3_1 = 1
x = np.array([2,3])
y = 0
for i in range(200):
a1_1 = sigmod(sum(x*w1_1)+b1_1)
a1_2 = sigmod(sum(x*w1_2)+b1_2)
a1 = np.array([a1_1,a1_2])
a2_1 = sigmod(sum(a1*w2_1)+b2_1)
a2_2 = sigmod(sum(a1*w2_2)+b2_2)
a2 = np.array([a2_1,a2_2])
a3 = sigmod(sum(a2 * w3_1)+b3_1)
loss = -y * np.log(a3) - (1 - y) * np.log(1 - a3)
print(loss)
dz3 = a3 - y
dw3_1 = dz3 * a2
dz2 = dz3 * w3_1 * a2 * (1-a2)
dw2_1 = dz2[0] * a1
dw2_2 = dz2[1] * a1
da1 = dz2[0] *w2_1 + dz2[1]*w2_2
dz1 = da1 * a1 *(1-a1)
dw1_1 = dz1 * x
dw1_2 = dz1 * x
step = 0.1
w1_1 -= step*dw1_1
w1_2 -= step*dw1_2
w2_1 -= step*dw2_1
w2_2 -= step*dw2_2
w3_1 -= step*dw3_1
b1_1 -= step*dz1[0]
b1_2 -= step*dz1[1]
b2_1 -= step*dz2[0]
b2_2 -= step*dz2[1]
b3_1 -= step*dz3
|
参考资料 |
吴恩达机器学习