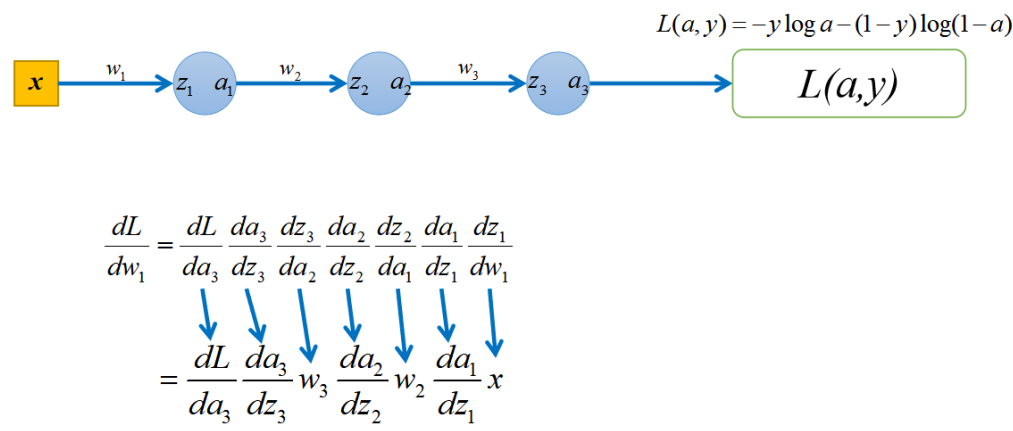
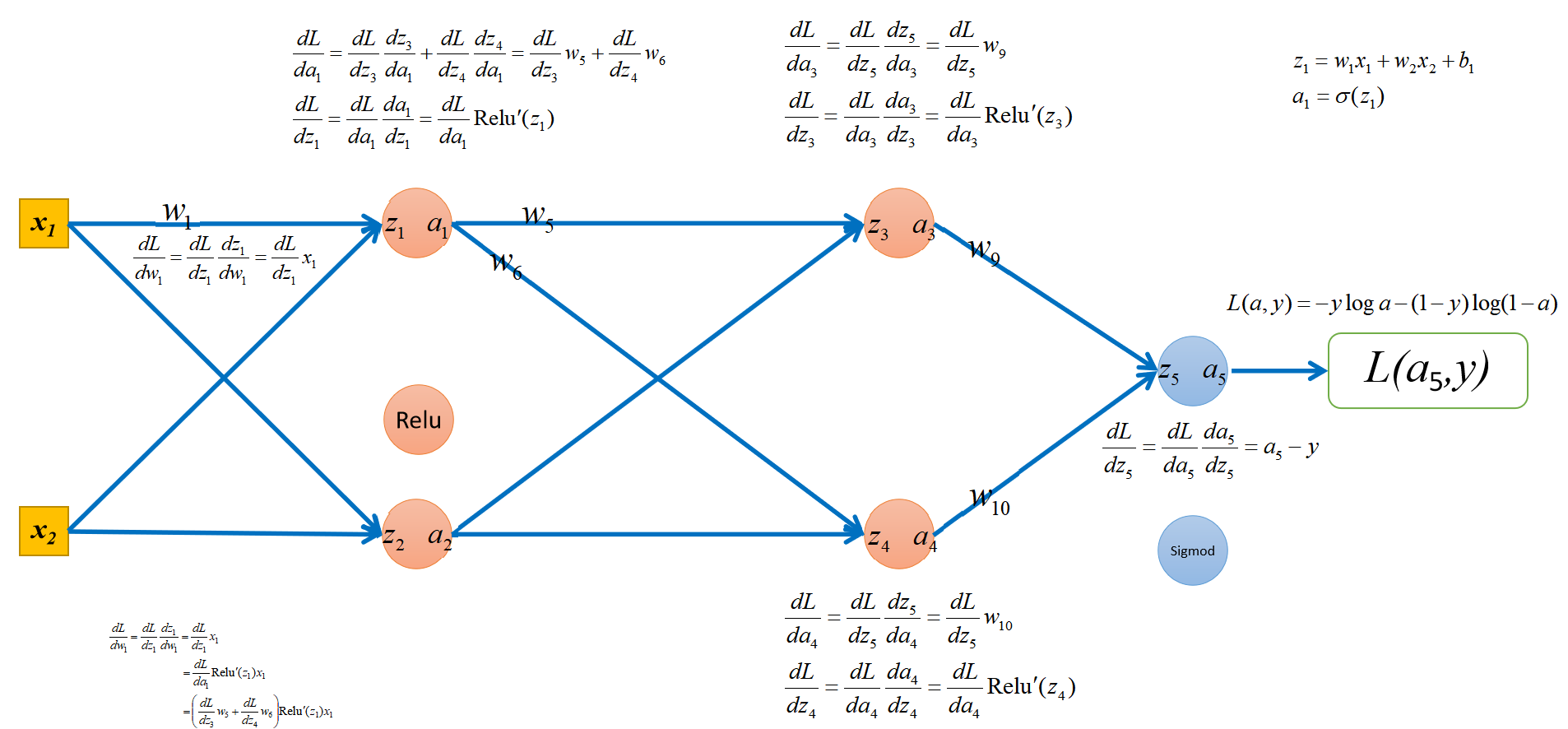
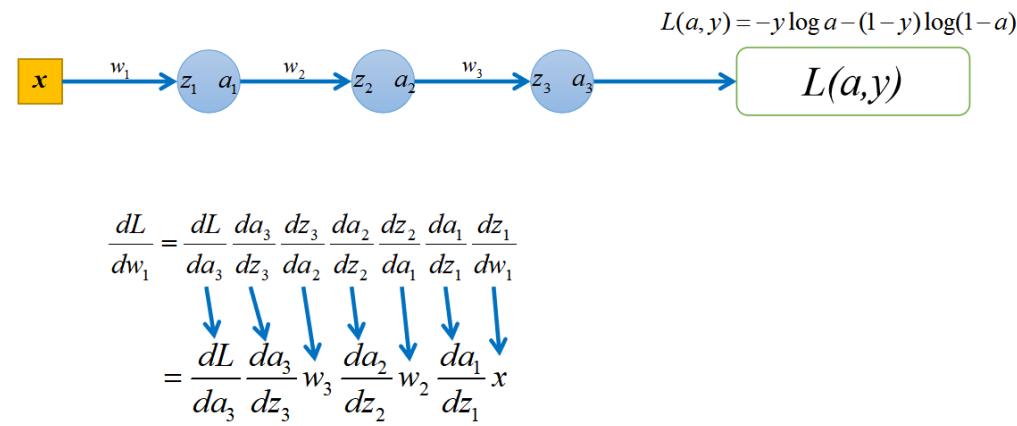
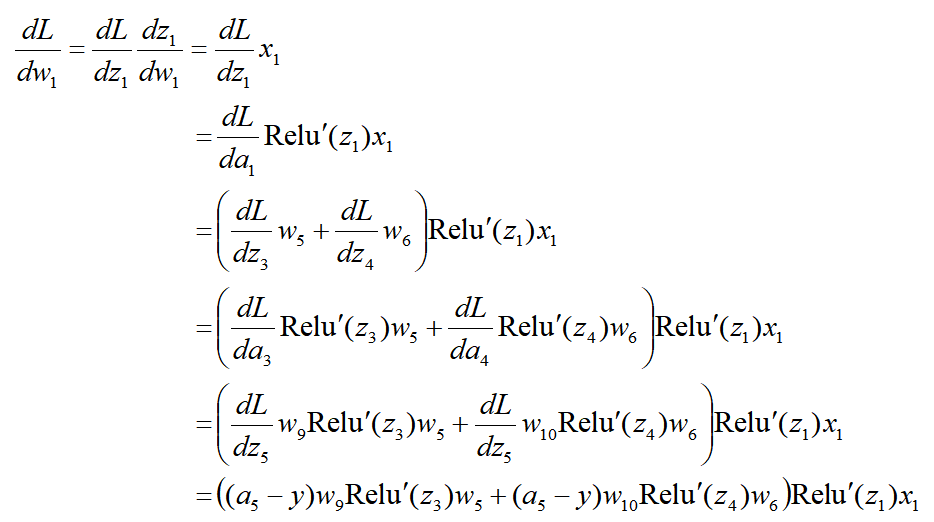import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
torch.manual_seed(5)
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, active_function):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.active_function = active_function
self.i2h0 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h1 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h2 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h3 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h4 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h5 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h6 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h7 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h8 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2h9 = nn.Linear(input_size + hidden_size, hidden_size, bias=False)
self.i2o = nn.Linear(hidden_size, output_size, bias=False)
def forward(self, input, hidden):
combined = torch.cat((hidden, input[0]), 1)
hidden = self.active_function(self.i2h0(combined))
combined = torch.cat((hidden, input[1]), 1)
hidden = self.active_function(self.i2h1(combined))
combined = torch.cat((hidden, input[2]), 1)
hidden = self.active_function(self.i2h2(combined))
combined = torch.cat((hidden, input[3]), 1)
hidden = self.active_function(self.i2h3(combined))
combined = torch.cat((hidden, input[4]), 1)
hidden = self.active_function(self.i2h4(combined))
combined = torch.cat((hidden, input[5]), 1)
hidden = self.active_function(self.i2h5(combined))
combined = torch.cat((hidden, input[6]), 1)
hidden = self.active_function(self.i2h6(combined))
combined = torch.cat((hidden, input[7]), 1)
hidden = self.active_function(self.i2h7(combined))
combined = torch.cat((hidden, input[8]), 1)
hidden = self.active_function(self.i2h8(combined))
combined = torch.cat((hidden, input[9]), 1)
hidden = self.active_function(self.i2h9(combined))
output = self.active_function(self.i2o(hidden))
return output, hidden
def initHidden(self):
# return torch.zeros(1, self.hidden_size)
w = torch.empty(1, self.hidden_size)
nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
return w
def train(category_tensor, input_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
output, hidden = rnn(input_tensor, hidden)
loss = criterion(output, category_tensor)
loss.backward()
# Add parameters' gradients to their values, multiplied by learning rate
lst_params = list(rnn.parameters())[:10] # 只获取i2h的参数
lst_x = []
lst_y = []
for i, p in enumerate(lst_params):
# print("梯度值", p.grad.data)
grad_abs = np.abs(np.array(p.grad.data))
# np_greater_than_0 = grad_abs.reshape(-1)
np_greater_than_0 = grad_abs
# np_greater_than_0 = np_greater_than_0[np_greater_than_0 > 0]
print(np.max(np_greater_than_0))
grad_abs_mean_log = np.log10(np_greater_than_0.mean())
grad_abs_var_log = np.log10(np_greater_than_0.var())
# print("倒数第{}层的梯度张量绝对值的均值取对数为{},方差取对数为{}".format(i + 1, grad_abs_mean_log, grad_abs_var_log))
lst_x.append(i + 1)
lst_y.append(grad_abs_mean_log)
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item(), lst_x, lst_y
if __name__ == '__main__':
input_tensor = torch.randn(10, 1, 100)
input_size = input_tensor.shape[-1]
hidden_size = 200
output_size = 2
# rnn0 = RNN(input_size, hidden_size, output_size, torch.relu)
# init_weight = rnn0.i2h0._parameters["weight"].data
init_weight = torch.randn(200, 300)/15
active_function = torch.relu
active_function = torch.tanh
active_function = torch.sigmoid
rnn = RNN(input_size, hidden_size, output_size, active_function)
# init_weight = rnn.i2h0._parameters["weight"].data
rnn.i2h1._parameters["weight"].data = init_weight
rnn.i2h2._parameters["weight"].data = init_weight
rnn.i2h3._parameters["weight"].data = init_weight
rnn.i2h4._parameters["weight"].data = init_weight
rnn.i2h5._parameters["weight"].data = init_weight
rnn.i2h6._parameters["weight"].data = init_weight
rnn.i2h7._parameters["weight"].data = init_weight
rnn.i2h8._parameters["weight"].data = init_weight
rnn.i2h9._parameters["weight"].data = init_weight
criterion = nn.CrossEntropyLoss()
learning_rate = 1
n_iters = 1
all_losses = []
lst_x = []
lst_y = []
for iter in range(1, n_iters + 1):
category_tensor = torch.tensor([0]) # 第0类,哑编码:[1, 0]
output, loss, lst_x, lst_y = train(category_tensor, input_tensor)
print("迭代次数", iter, output, loss)
print(lst_y)
lst_sigmod = [-9.315002, -8.481065, -7.7988734, -7.133273, -6.412653, -5.703941, -5.020198, -4.441074, -3.7632055, -3.1263535]
lst_tanh = [-3.5717661, -3.4407198, -3.1482387, -2.968598, -2.7806234, -2.58508, -2.4179213, -2.3331132, -2.164275, -2.0336704]
lst_relu = [-4.169364, -4.0102725, -3.6641762, -3.505077, -3.2865758, -3.089403, -2.8985455, -2.762998, -2.503199, -2.368149]
plt.plot(lst_x, lst_sigmod, label="sigmod")
plt.plot(lst_x, lst_tanh, label="tanh")
plt.plot(lst_x, lst_relu, label="relu")
plt.xlabel("第i个时间步")
plt.ylabel("梯度张量绝对值的均值取对数")
plt.title("调研:不同激活函数下梯度消失的程度")
plt.legend(loc="lower left")
plt.show()