目录
集成算法
Bagging模型
随机森林优势
Bagging模型集成
|
集成算法 |
目的:让机器学习效果更好,三个凑皮匠顶个诸葛亮的思想。
实现思想有:
Bagging:训练多个分类器取平均

Boosting:从弱学习器开始加强,通过加权来进行训练
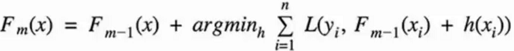
|
Bagging模型 |
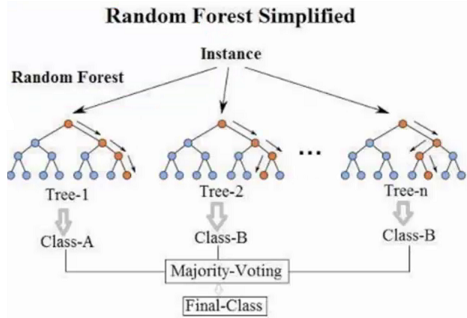
思想:并行训练一堆分类器
最典型的代表就是随机森林(训练多个决策树,过程可参考决策树相关文章)
随机:数据采样随机,特征选择随机
森林:多个决策树并行放在一起
|
随机森林优势 |
能够处理很高维度(feature很多)的数据,并且不用做特征选择
在训练完后,他能够给出哪些feature比较重要
容易做成并行化方法,速度比较快
可以可视化展示,便于分析
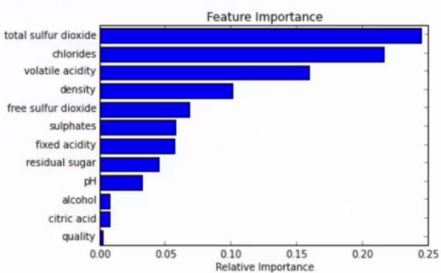
假设训练集样本有9000个,特征有A、B、C、D。随机森林进行50次有放回抽样,最终会有一部分样本没有被抽到,没有本抽到的样本的集合称为out-of-bag,这个集合可以用来评测模型。
如果想测特征A的重要性,可以破坏特征A的取值,比如随机一些数据代替掉A特征里的数据,然后看一下随机森林模型在out-of-bag集合里错误率提升的幅度,错误率提高越大说明特征A越重要。
|
Bagging模型集成 |
理论上越多的树效果越好,但实际上基本超过一定数量差不多上下浮动了。也要根据具体业务,不同数据可能会不同,可以通过交叉验证法来决定。
