201704171025
01、
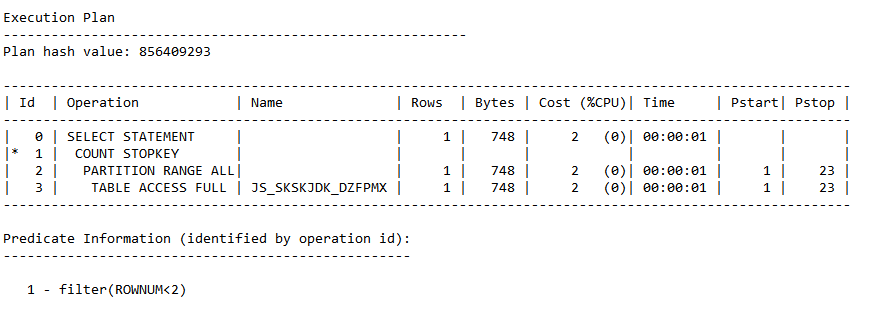
列rows记录的就是执行计划中每一个执行步骤所对应的Cardinality的值
列Cost(%CPU)记录的就是执行计划中的每一个执行步骤对应的成本
02、
Computed Cardinality=Original Cardinality * Selectivity
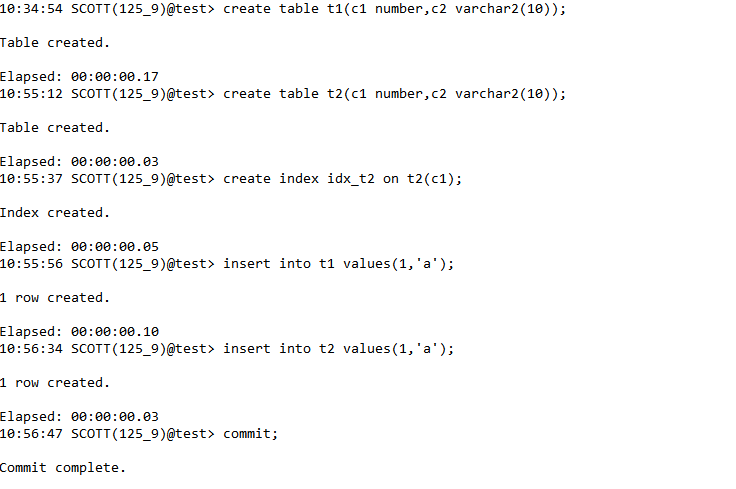
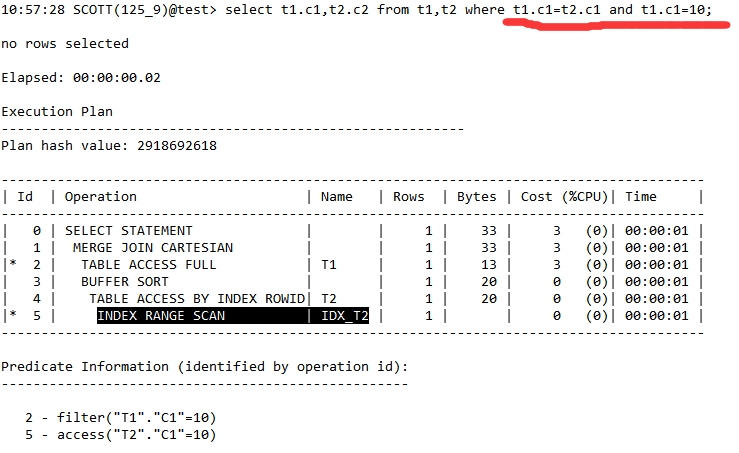
03、简单谓词连接
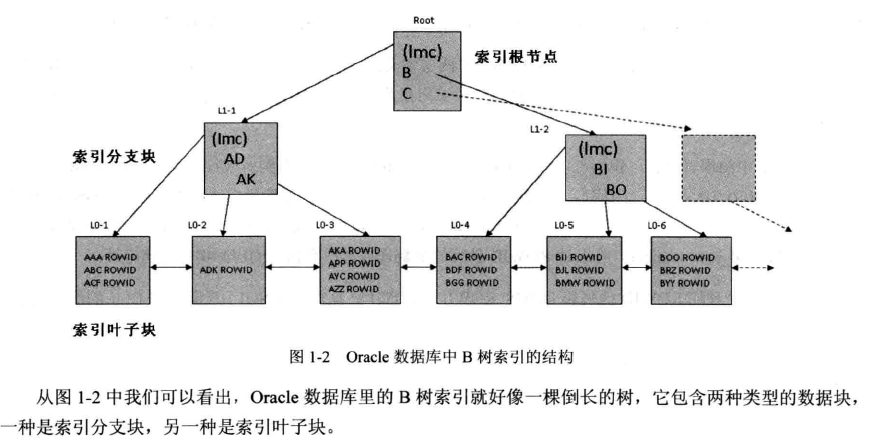
04、B树索引
05、索引连接方式
索引唯一扫描
是针对唯一索引的扫描,它仅仅适用于where条件里是 等值查询的目标sql。因为扫描的对象时唯一性索引,索引索引唯一性扫描的结果之多返回一条记录
索引范围扫描
适用于所有类型的B树索引。
当扫描对象时唯一性索引时,此时目标sql的where条件一定是范围查询(谓词条件为 between 、<、>);
当扫描对象是非唯一性索引时,此时目标sql的where条件没有限制(可以是等值,也可以是范围查询)
索引全扫描
适用于所有类型的B树索引。
要扫描目标索引所有叶子快的所有索引行。索引全扫描需要扫描目标索引的所有叶子快。
oracle在做索引全扫描时只需要访问必要的分支块等位到鱼尾该索引最左边的叶子快的第一行索引行,就可以利用该索引椰子块之间的双向指针链表,从左至右一次扫描叶子块的所有索引行
索引快速全扫描
只适合于CBO
可以单块读可以多快读
结果集不一定是有序的。因为FFS 时 oracle根据索引行在磁盘上的 物理存储位置 扫描,而不是根据索引行的逻辑顺序扫描。因此结果不一定有序
索引跳跃式扫描
仅仅适用于那些目标索引前导列的distinct值数量较少、后续非前导列的可选择性有非常好的情形。因为索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减
06、
hint 强制使用9i版本
/*+optimizer_feature_enable(9.2.0) */
201704172148
--嵌套循环连接的优缺点和应用场景
从上述嵌态循环连接的具体执行过程可以看出:如果驱动表所对应的驱动结果集的记录数较少,同时
在被驱动表的连接列上又存在唯一性索引(或者在被驱动表的连接列上存在选择性很好的非唯一索引),那么此时使用嵌套循环连接的执行效率就会非常高;但如果驱动表所对应的驱动结果集的记录很多,即便在被驱动表的连接列上存在索引,此时使用嵌套循环连接的执行效率也不会高。
只要驱动结果集的记录数较少,那就具备了做嵌套循环连接的前提条件,而驱动结果集是在对驱动表应用了目标sql指定的谓词条件)所得到的结果集,所以大表也可以作为嵌套循环连接的驱动表。关键看目标SQL中指定的谓词条件(如果有的话)能否将结果集降下来。
嵌套循环连接有其他方式所没有的一个优点:嵌套循环连接可以实现快速响应
1021
本质上SQL ID和SQL HASH VALUE是一回事,它们是可以互相转换的,这也是方法
BMS_XPLAN.DISPLAY CURSOR所传入的第一个参数的值可以是SQL ID,也可以是SQL HASH VALUE
SQL> select lower(trim(13yfu3wh150aqt!))sql id, trunc(mod (sum((instr(10123456789abedfghikmnpqrstuvwxyz' niintgsett)),level,1))-1)*power(32,1ength(trin( 3yfuswhis0asth nnntsubstr(lower(trim('3yfu3whis0aqt')),level,1))-1)'pove nint-level)),power(2,32)))hash value
from dual
1045
执行 select * from table(dbms_xplan.display_awr('sql_id')) ,用于查看指定sql的历史执行计划
1103 oradebug
oradebug setmypid
oradebug event 10046 trace name context forever,1evel 12;
select statements
oradebug tracefile_name
oradebug event 10046 trace name context off
tkprof ......trc
cr :consistent reads
pr :physical reads
1411
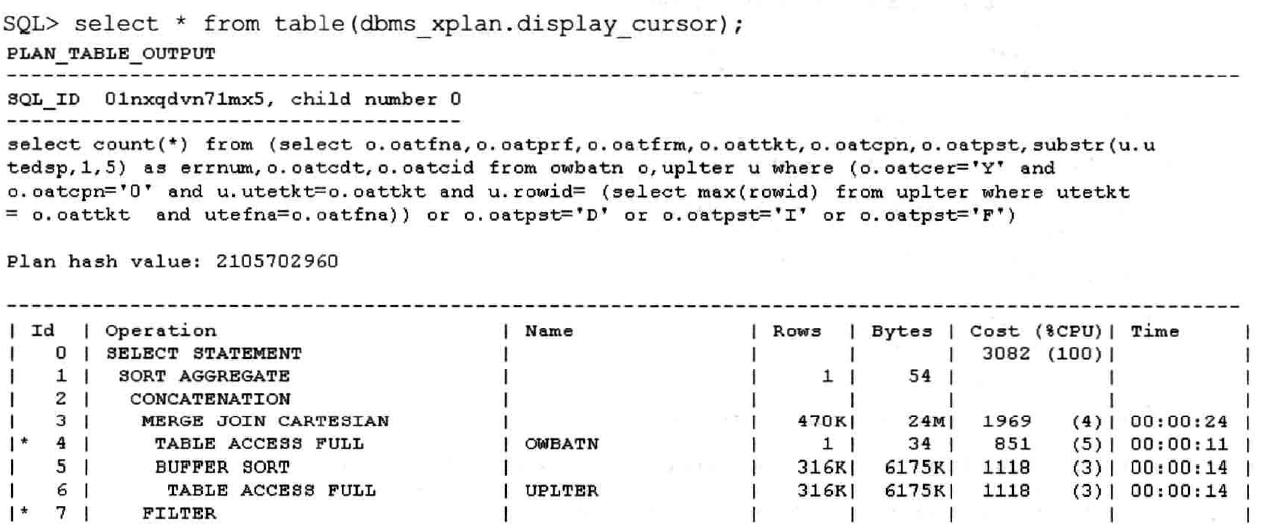

先从最开头一致持续往右看,直到看到最右边的并列的地方;
对于不并列的,靠右的先执行;
如果见到并列的,就从上往下看。对于并列的部分,靠上的先执行
TABLE ACCESS FULL
BUFFER SORT
Plan hash value:2105702960
------------------------------------------------------------------------------------------------------------------
|Id | Operation | Name | Rowa | Bytes | Cost(%CPU) | Time |
| 0 | SELBCT STATEMENT | | | | 3082(100))| |
| 1 | SORT AGGREGATE | | 1 | 54 | | |
| 2 | CONCATENATION | | | | | |
| 3 | MERGE JOIN CARTESIAN | | 470K | 24M | 1969(4) | 00:00:24 |
| 4 | TABLE ACCESS PULL |OWBATN | 1 | 34 | 851(5) | 00:00:11 |
| 5 | BUFFER SORT | | 316K| 6175K| 1118(3) | 00:00:14 |
| 6 | TABLE ACCB88 FULL |UPLTER | 316K| 6175K| 1118(3) | 00:00:14 |
| 7 | FILTER | | | | | |
| 8 | HASH JOIN | | 37522| 1978K| 1109(6) | 00:00:14 |
| 9 | TABLE ACCESS PULL |OWBATN | 20956| 695K| 852(5) | 00:00:11 |
| 10 | INDEX FAST FULL SCAN |IDX_UPLTER_UTETKT | 316K| 6175K| 246(6) | 00:00:03 |
| 11 | SORT AGGRBGATE | | 1 | 38 | | |
| 12 | TABLE ACCES8 BY INDEX ROWID | UPLTER | 1 | 30 | 4(0) | 00:00:01 |
| 13 | INDEX RANGE scAN | IDx_UPLTER_UTETKT | 2 | | 3(0) | 00:00:01 |
·13
eedieate Information (identitied by operetton ttii
otp,on "O"."OATE8m"="F"OR "o","oATPgn"-'I”))
XPLAN包查看执行计划的执行顺序
列的属性为 null,那么该字段可能会存 null类型的数据。因此 如果按照 访问索引的方式访问 可能会漏掉数据。 索引上不会有null数据
dbms_xplan.display_cursor(null,null,'advanced') 弊端多多啊,必须在执行完sql之后 马上执行这个操作。才可以看到执行计划 太被动
比如 表t的索引列为a,然后我执行查询:select a,b from t where a = 'xxx';
这样的话,靠a上的索引提供不了查询所要的数据a+b,所以要去表中找,这个过程叫做回表?
0903
whenever sqlerror exit sql.sqlcode;
dbms_sqltune.import_sql_profile
索引聚簇因子
更新聚簇因子 exec dbms_stats.set_index_stats(ownname=>'user_name',indname=>'index_name',clstfct=>24000000,no_invalidate=>false)
查询聚簇因子 select idx1.index_name,idx1.clustering_factor from dba_indexes idx1
1045
cursor
oracle数据库中的shared cursor 又可细分为 parent cursor 和child cursor 这两种类型。通过查询视图 v$sqlarea 可查看 parent cursor,v$sql 可查看child cursor
Parent Cursor 和 Child Cursor的结构是一样的(它们都是以库缓存对象句柄的方式缓存在库级存中,
Namespace属性的值均为CRSR),它们的区别在于目标SQL的SOL文本会存储在其Parent Curser所对应的缓存对象句柄的属性Name中(Child Cursor对应的库缓存对象句柄的Name属性值为空,这意味着只有通过
Parent Cursor才能找到相应的Child Cursor),而该SQL的解析树和执行计划则会存储在其Child Cursor所对应的库缓存对象句柄的Heap6中,同时Oracle会在该SQL所对应的Parent Cursor的Heap 0的的Child table中,
存储从属于该Parent Cursor的所有Child Cursor的库缓存对象句柄地址(这意味着Oracle可以通过访问 Paren cursor
中的Child table而依次顺序访问从属于该Parent Cursor的所有Child Cursor)。
parent cursor 会存储该sql的sql文本,child cursor 会存储 该sql对应的解析数和执行计划
1415 errorstack
alter session set events'immediate trace name errorstack level 3'
隐式游标
sql%FOUND true/false
sql%NOTFOUND true/false sql语句被执行成功后受影响的行数是否是0
sql%isopen 隐式游标是否处于open状态 恒为 false
sql%rowcount 一条sql语句成功执行后受影响而改变的记录的数量
1524
参考游标的定义方式以下四种
第一种方式:
type typ_cur_emp is ref cursor return emp%rowtype;
cur_emp typ_cur_emp;
第二种方式:
type typ_result is record(ename emp,ename%type,sal emp.salstype;
type typ_cur strong is ref cursor return typ_result;
cur emp typ cur_stong;
第三种方式:
tvpe typ_cur weak is ref cursor;
cur_emp typ_cur_weak;
第四种方式:
cur emp SYS_REFCURSOR;
上述范例HL/SQL代码用四种不同的方式分别定义了同一个参考游标ctr.emm
1559
PL/SQL中select语句的绑定变量典型用法
execute immediate 'select ename from emp where empno=:1' using 7369;
1608
PL/SQL代码中批量fetch对应的语法:
fetch cursor_name bluk collect into [自定义的数组] <limit 数字[建议值通常 1000]>
forall i in 1..[自定义数组的长度] --forall 表示一次执行一批sql
execute immediate [带绑定变量的目标sql] using [对应绑定变量的输入值]
PLSQL中使用批量绑定的范例代码为如下所示,
declare
cur_emp sys refcursor;
ve_sql varchar2(4000);
expe namelist ie table of varchar2(10);
enames namelist;
CN_BATCH_SIZE constant pls_integer :=1000;
begin
vc_sql :='select ename from emp where empno>:1';
open cur_emp for vc_sql using 7900;
loop
feteh cur_emp bulk collect into enames linit CN_BATCH_SIZE;
for i in 1..enames.count loop
dbms_output.put_line(enames(i));
end loop;
exit when enames.count< CN_RATCH_SIZE;
end loop;
close cur_emp;
end;
/
1709
index fast full scan 会扫描所有的索引叶子块
1723
对于目标soL(即即 seleet count(*) fom tl where object_id between :x and :y)而言,其where条件的selectivity
和Cardinality的计算公式为如下所示示
Cardinality=NUM_Rows*Selectivity
selectivity=((y-x)/(HIGH_VALUE-LOW_VALUE)+2/NUM_DISTINCT)*Nu11_Adjust
Nu11_Adjust=(NUM ROWS-NUM_NULLS)/NUM_ROWS
NUM_Rows表示目标列所在表的记录总数
LOW_VALUE 目标列的最小值
HIGH_VALUE 目标列的最大值
NUM_DISTINCT 目标列的 distinct值的数量
NUM_NULLS 目标列的NULL列的数量
从如下查询结果可以看到,对应于上述计算公式的LOW_VALUE的值为C103,
HIGH_VALUE的值为C309395E,NUM_DISTINCT的值为72,387,NUM_NULLS的值为2;
select 1ow_value,high_value,num_distinct,num_nulls from dba_tab_col_statistics
where owner='SCOTT' and table_name='T1' and column_name='OBJECT_ID';
LOW_VALUE HTCH_VATUE NUM_DTSTINCT NUM_NULLS
----------------------------------------------
c103 C309395e 72387 2
从如下查询结果可以看到,HIGH_VALUE的值C309395E实际上就等于85,093;
SQL> select max(object_id),dump(min(object_id),16) from ti ;
MAX(OBJECT_ID) MAX (OBJECT ID) DUMP(MAx(OBJECT_ID),16)
85693 Typ=2 Len=4: c3,9,39,5e
从如下查询结果可以看到,LOW_VALUE的值C103实际上就等于2
SQL> select min(object_id),dump(min(object_id),16) from ti ;
MIN(OBJECT_ID) MIN (OBJECT ID) DUMP(MAx(OBJECT_ID),16)
2 Typ=2 Len=2: c1,3
查询到的 NUM_ROWS、LOW_VALUE、HIGH_VALUE、NUM_DISTINCT、NUM_NULLS 和 x、y的值代入计算公式。
2111 删除sql的 shared cursor
exec sys.dbms_shared_pool.purge([address],[hash_value],'c');
2215
select tab.ADDRESS,tab.BIND_NAME,tab.POSITION,tab.DATATYPE,tab.MAX_LENGTH from v$sql_bind_metadata tab
2217 批量绑定时如何处理错误
bulk_errors exception;
paragma exception_init(bulk_errors,-24381);
type typ_errorindex is table of number index by binary_integer;
errorindexs typ_errorindex;
type typ_errorcode is table of varchar2(50) index by binary_integer;
errorcodes typ_errorcode;
exception
when bulk_errors then
for i in 1..sql%bulk_exceptions.count() loop
errorindexs(j):=sql%bulk_exceptions(j).error_index;
errorindexs(j):=-sql%bulk_exceptions(j).error_index;
0934
Oracle10g及后续的版本中,Oracle会自动收集直方图统计信息。直方图统计信息 是对于单个列的
0946
v$sql_cs_statistics 用于显示指定 child cursor中存储的runtime统计信息
v$sql_cs_selectifity 用于显示指定的、已经被标记为 Bind Aware的 Child Cursor中存储的含绑定变量的谓词条件对应的可选择率的范围
0956
收集直方图统计信息
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=>'T1',estimate_percent=>100,cascade=>true,method_opt=>'for all columns size auto',no_invalidate=> false);
dbs_tab_col_statistics
1009
再次以目标SQL对应的SQL_ID去查询视图VSSQL:
soL> select child_number,executions,buffer_gets,is bind_sensitive bs,is bind_aware ba,
is shareable SH,plan_hash_value from v$seql where sql id=179g1p919t7x4u”)
BUFFER GETS BS BA SH BLAN_HASH_VALUE
EXECUTIONS
CHILD NUMBER
1029
在目标列有Frequency类型直方图的前提条件下,如果对目标列等值查询条件,且在查询条件的输入值等于该类的实际值时,谓词条件的可选择率计算公式如下所示:
selectivity=Bucketsize /NUM_ROMS
上述计算公式启用了绑定变量就探,目标列有Frequency类型的直方图,对日标列添加等值查询条件,且
查询条件的输入值等于该列的某个实际值时的计算。
NUM_ROWS 表示目标列所在表的记录数。
BucketSize表示目标列的某个实际值所对应的记录致。
1051 -一定得搞清楚 child_number 可以根据sql_id 找到该sql所有的 child_number
child curor的可选择率范围
select child_number,predicate,range_id,low_high from v$sql_cs_selectivity where sql_id='xxxx';
v$sqlarea
1647
子查询展开,执行效率
in 外部结果集条数 有 N,其实执行效率会把外部查询全部执行,然后根据内部查询的结果 去外部结果中 遍历
/* no_merge(view_name) */ 不合并视图
2124
参数star_transformation_enabled 用于控制是否启用星型转换
0939
在Oracle11gR2之前,把某个据不分区索引的状态设为unusable后,会导致所有原本可以使用该局部分区索引的查询语句都无法正常使用该局部分区索引
alter index index_name modify parartition p12 unusable; 索引的单个分区索引 失效
alter index index_name rebuild partition p12; 重建该分区索引,恢复可用状态
1005
表移除
select ename from emp,dept where emp.deptno=dept.deptno;
表empde 列deptno 属性为 not null,而在列deptno 和主表dept的主键列存在一个名为pk_deptno的外键。对于该外键而言,表emp是子表,表dept是主表。即 对于子表emp的列deptno而言,主表dept中一定存在与之对应的匹配记录。因此
以上sql相当于 select ename from emp
博大精深的 cbo啊
1013
emp.deptno=dept.deptno(+) 外连接哦
1024
select * from emp where deptno in (10)
union all
select * from emp where mgr in (7782) and lnnvl(deptno in (10))
函数LNNVL 作用:排除 mgr in (7782) and deptno in (10)这种情形
1122
awr sql report
stat_name statement_total per_exection
elapsed_time(ms) 637922
exections 66(次)
buffer gets 222222(个)
1439
一定要记住哦,对系统内部表使用dbms_stats包收集统计信息哦。如下
exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'X$BH');
从Oracle10g开始,创建索引之后Oracle会自动收集目标索引的统计信息
删除索引的统计信息
analyze index index_name delete statistics;
对表t2收集统计信息,并且是 以 估算模式,采样比例是 15%
analyze table t2 estimate statistics sample 15 percent for table;
对表t2收集统计信息,并且以 计算模式
analyze table t2 compute statistics for table;
对表t2 的列 col1,col2 收集统计信息,以 计算模式
analyze table t2 compute statistics for column col1,col2;
记住哦,对同一个对象 新的analyze命令会擦除 之前的analyze的结果
同时对表t2和 列 col1、col2 收集统计信息
analyze table t2 compute statistics for table for columns col1,col2;
以计算模式对索引 idx02 收集统计信息
analyze index idx02 compute statistics;
一次性的以 计算模式 收集表t2、表t2的所有列和表t2上的所有索引的统计信息,如下:
analyze table t2 compute statistics;
以估算模式对条t2收集统计信息,采样比例是15%
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=>'T2',estimate_percent=>15,method_opt=>'FOR TABLE',cascade=>false);
删除表t2、所有列、所有索引的统计信息
exec dbms_stats.delete_table_stats(ownname=>'SCOTT',tabname=>'T2')
一次性以计算模式收集表t2、所有列、所有索引的统计信息
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=>'T2',ESTIMATE_PERCENT=>100,CASCADE=TRUE);
1542
analyze 命令不能正确收集分区表的统计信息,而DBMS_STATS包
1548
dbms_stats包可以 并行收集表的统计信息哦 degree
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=>'T2',cascade=>true,estimate_percent=>100,degree=4);
dbms_stats只能收集与cbo相关的统计信息,而与cbo无关的额外信息无法收集。比如 行迁移/行链接。analyze 可以哦
比如:analyze table table_name list chained rows into xxx;
analyze index index_name validate structure;
1621
数据典中的字段NUM ROWS存储的就是目标表的记录数,目标表的记录数是计算结果集的基础,而结果集的Cardinality则往往直接决定了CBO计算的成本值。
数据字典中的字段BLOCKS存储的就是目标表表块的数量,即目标表的数据所占用数据块的数量,目标表表块的数量会直接决定CBO计算出来的对目标表做全表扫描的成本,目标表表块的数量越大,则对目标表走全表扫描的成本值就会越大。
数据字典中的字段AVG_ROW_LEN存储的就是目标表的平均行长度。平均行长度的计算方法是用目标表的所有行记录所占用的字节数(不算行头)除以目标表的总行数,它可能会被Oraele,用来计算目标表对应的结果集所占用内存的大小
1650
--2.查找表的历史统计信息
select obj.object_name, oth.savtime, oth.rowcnt, oth.analyzetime,oth.blkcnt,oth.avguln
from sys.WRI$_OPTSTAT_TAB_HISTORY oth, dba_objects obj
where oth.obj# = obj.object_id and obj.object_name='EMP' --请修改表名字
order by oth.analyzetime desc nulls last;
1507
上述数据字典中的字段CLUSTERNG FACTOR.存储的就是目标索引的聚簇因子,聚族因子是指按照然索引键值排序和存储于对应表中的数据行的存储顺序的相似程度。
上述数据字典中的字段DiSTRNCT KEYS存储的就是目标索引的索引键值的disinct值的数量。对于唯一性索引而言,在没有NULL值的情况下,DISTINCT.KEYS的值就等手对应表的记录数。
上述数据字典中的字段AVG_LEAF_BLOCKS_PER_KEY存储的就是目标索引的每个distinct索引键值所占用的叶子块数量的平均值,对于唯一性索引而言,AVG_LEAF_BLOCKS_PER_KEY显然只会是1。
上述数据字典中的字段AVG_DATA BLOCKS_PER_KEY存储的就是目标索引的每个distnet索引键值所对应表中的数据行所在数据块数量的平均值。
上述数据字典中的字段NUM_ROWS存储的就是目标索引的索引行的数量。
修改索引的聚簇因子 clstfct
exec dbms_stats.set_index_stats(ownname=>'owner_name',indname=>'index_name',clstfct=>1000,no_invalidate=>false);
hist_head$
2125
执行计划中Rows列的值表示CBO评估出来的对应执行步骤所返回结果集的行数
cardinality=NUM_ROWS*selectivity
Nul1_Adjust=(NUM——ROWS-NUM_NULLS)/NUM_ROWS
selectivity=((HTGH_VALUE-VAL)/(HTCH_VALUE-Lo_VALUE))*Null——Adjust
2140
dba_hist_sqlstat
2154
检查目标表中 列的统计信息
select t1.low_value,t1.high_value from dba_tab_col_statistics t1 where t1.table_name='EMP' and column_name='EMPNO'
取出 low_value
SQL> var temp date;
SQL> exec dbms_stats.convert_raw_value('low_value',:temp);
2208
直方图 Histgrm是一种特殊的列统计信息,详细描述了目标列的数据分布情况。存储在数据字典基表 histgrm$;专门为了准确评估分布不均匀的目标列的可选择率、结果集的cardianlity。详细描述了目标列的数据分布情况,并将分布情况记录在数据字典里。
2228 对 列收集直方图
exec dbms_stats.gather_table_stats(ownname=>'owner_name',tabname=>'table_name',method_opt=>'for columns size auto column_name',cascade=>true);
'for columns size auto column_name' 表示对目标表的列 column_name 收集直方图统计信息,auto 的含义是指让Oracle自行决定到底是否对列column_name收集的直方图是哪种类型的直方图
oracle会关注目标表的某个列的使用情况,记录在 col_usage$
select * from col_usage$;
20170424
0933
dba_tab_col_statistics
dba_tab_histograms 表的直方图相关信息
0935
文本型 ‘1’ 转换为 浮点数
select dump(1,16) from dual;
typ=96 len=1:31
0x31右边补0一直补到15个字节的长度,再转换为十进制数
select to_number('31000000000000000','XXXXXXXXXXXXXXXXX') from dual;
0948
删除列id上的直方图统计信息
exec dbms_stats.gather_table_stats(ownname=>'owner_name',tabname=>'table_name',method_opt=>'for columns size 1 id',cascade=>true);
注意此处的 1 表示对列 id收集直方图时使用的bucket的数量为1
1010
DBMS_STATS包中上述存储过程的输入参数METHOD_OPT可以接受如下的输入值:
FOR ALL [INDEXED | HIDDEN] COLUMNs (size_clause]
FOR CoLUMNS [size clause] column|attribute [size clause] [,columnlattzibute
[size clause]..
其中的size clause必须符合如下的格式:
SIZE{integer | REPEAT | AUTo | SKEWONLY}
size clause子句中各选项的含义如下所述。
* interer.直方图的Bucket的数量,必须是在1~254的范围内,1表示删除该目标列上的直方图统计信息
*REPEAT;只对已经有直方图统计信息的列收集宜方图统计信息,
*auto Oracle 自行决定是否对目标列收集直方图统计信息,以及使用哪种类型的直方图统计信息
*SKEWONLY:只对数据分布不均衡的列收集直方图统计信息。
1027
select /*+cursor_sharing_exact_demo */ count(*) from t;
v$sqlarea version_count
1034
直方图统计信息实际上可以影响shared cursor是否能被共享
1041
null_adjust=(num_rows - num_nulls)/num_rows
density(密度、基数)=1 / (2* num_rows * null_adjust)
dba_tab_histograms
1101
select power(3296,2) from dual;
POWER(3296,2)
-------------
10863616
1122
以下三忌:
如果目标列的数据时均匀分布的,比如 主键列、唯一索引的列,根本不需要对这些列收集直方图统计信息
对于那些从没有在sql语句的where条件中出现的列,不管数据分布是否均匀,都无需对其收集直方图统计信息
直方图统计信息可能会影响shared_cursor的共享
在配置oracle10g引入的自动统计信息收集作业的时候,需要特别注意对直方图统计信息的收集策略
1238
全局统计信息对CBO来说是非常重要的,针对分区表的sql,除非查询条件先定了带访问的数据只在部分分区上,飞则大部分情况下都需要全局统计信息才能得到正确的执行计划
只能由 dbms_stats来收集
1246
analyze命令对表t2以计算模式收集统计信息(计算模式会扫描目标对象的所有数据)
analyze table t2 compute statistics;
1249 查找某参数的默认值
select dbms_stats.get_param('granularity') from dual;
1252 删除表的统计信息
exec dbms_stats.delete_table_stats(ownname=>'user_name',tabname=>'table_name')
1255
使用dbms_stats.gather_table_stats重新收集统计信息,参数granularity的值为 all,表示在t2的表级别、分区级别、子分区级别都收集全局统计信息
exec dbms_stats.gather_table_stats(ownname=>'owner_name',tabname=>'table_name',estimate_percent=>100,granularity=>'ALL');
1304
analyze table table_name delete statistics; 只会删除子分区的统计信息
1307
analyze ... delete statistics.只级联删除子分区和分区的统计信息
1310
可以看到,ANALYZE…..DELETE STATISTICS命令只级联删除了子分区和分区上的统计信息
综合上述测试结果我们可以发现,ANALYZE….DELETE STATISTiCS命令总是会删除子分区的统计信
息,但是否能够级联删除分区级/表级的统计信息则取决于相应级别的GLOBAL_STATS的值。
如分区表级/表级 的GLOBAL_STATS的值为YES,则不能级联删除;反之就可以级联删除。
但要注意的是,ANALYZE DELETE STATisTice命令不能跨级删除统计信息,比如分区的GLOBAL STATIS的值为YER,而表级的
GLOBAL STATIS 的值为NO,则在使用ANALYZE…….DELETE STATISTiCS命令后表级的统计信息并不会被删除。
另外,DBMS_STATS.DELETE_TABLE_STATISTICS 总是可以副除分区表上所有的三个级测的统计传。
1316
最后我们来总结一下在Oradke数据库中使用全局统计信息的注意事项。
(1)应使用DBMS_STATS包来对分区表收集全局统计信息。
(2)应使用DBMS_STATS包中的相关存储过程(如DBMS_STATS.DELETE_TABLE_STATS)来删除分区表的统计信息,尽量避免用ANALYZE命令,因为ANALYZE命令不一定能把分区表的统计信息删除干净
(ANALYZE命令可能会导致部分统计信息并没有被删除)。
(3)收集分区表的统计信息时应使用一致的GRANULARITY参数。如果不使用一致的GRANULARITY
参数,比如开始用ALL,过一段时间用GLOBAL或PARTTTION,这样可能会导致在某些级别上的统计信息
是过时的、不准确的。
(4)由于ANALYZE命令只在最低一级收集统计信息,而高一级的统计信息则是由下级统计信息汇总和
推导而来的,因此尽量不要使用ANALYZE命令来对分区表收集统计信息,特别是不要将ANALYZE命令与
DBMS_STATS包联合使用在同一张分区表上,否则可能会导致该表在某些级别上的统计信息是过时的、不准确的。
1325
动态采样有如下两个方面的作用。
(1)Oracle称如果使用了动态采样,则不管SQL语句中各列有什么样的关联关系,在大多数情况下,CBO
都可以相对准确地估算出整个where条件的组合可选择率,进而能相对准确地估算出返回结果集的Cardinality
(2)有一些应用在执行的过程中会创建一些临时表,然后会往这些临时表里插入一些中间结果,接着将这
些临时表用于查询等操作,在执行完毕后会把这些临时表Drop掉或者Truncate其中的数据。这里的问题是
当这些临时表参与查询等操作的时候,它们是没有统计信息的,这种情况下采用的执行计划有可能是低效的
其至是错误的。而动态采样就可以在一定程度上解决这种因临时表没有统计信息而导致CBO选错执行计划的
问题。
1331
参数OPTIMIZER_DYNAMIC_SAMPLING的值及含义
level值及含义
1338
在“5.4.2聚族因子的含义及重要性”中提到索引范围扫描的成本计算公式为:
IRS Cost=I/O Cost +CFU Cost
I/O cost =Index Access I/o cost +Table Access I/o cost
Index Access I/O Cost =BLEVEL+CEIL(#LEAF_BLocKS *IX_SEL)
Table Access I/0 Cost=CEIL(CLUSTERING_FACTOR*IX_SEL_WTTH_FTLTERS)
1400
位表t2中有关联关系的列 n1 和 n2 创建一个组合咧
declare
cg_name varchar2(30);
begin
cg_name:=sys.dbms_stats.create_extended_stats('SCOTT','T2','(n1,n2)');
dbms_ouptput.put_line(cg_name);
end;
/
1413
select col#,intcol#,distcnt,minimum,maximum,density from sys.hist_head$;
1416
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=>'T2',method_opt=>'for columns(n1,n2) size auto',estimate_percent=>100);
1436
dbms_stats.gather_system_stats 收集数据库服务器的统计信息
dbms_stats.delete_system_stats 删除数据库服务器的统计信息
1. dbms_stats.gather_system_stats('start');开始收集系统统计信息
2. 正常使用系统
3. dbms_stats.gather_system_stats('stop'); 停止收集系统统计信息
1452
系统统计信息会存储在表AUX_STATSS里。执行DBMS_STATS.GATHER_SYSTEM_STATS收集系统统计
信息的时候,Oracle会在AUX STATSS里记录如下四个方面的信息。
·CPU的主频,单位是MHz(兆赫兹)。
·单块读的平均耗费时间,单位是ms(毫秒)。
·多块读的平均耗费时间,单位是ms(毫秒)。
·单次多块读所能读取的数据块的平均值。
Orace 会记录目标数据库所在的数据库服务器上的单次多块读所能读取的数据块的平均值,这对计算
全表扫描的成本带来了重大影响,因为在这种情况下MBDMSor 实际上就和
DB_FILE_MULTIBLOCK_READ_COUNT的值没有关系了。
1457
sys.all_parameters
1504
oracle 11.2.0.1
12:51:37 idle> show parameter multiblock;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 128
1522
全表扫描 多快读(168)
index range scan 单块读(1)
1524
修改单块读的平均耗费时间为 10ms
exec dbms_skats.set_system_stats('sreadtim',10);
修改多块读的平均耗费时间为 20ms
exec dbms_skats.set_system_stats('mreadtim',20);
1540
dbms_stats包里的存储过程dbms_stats.gather_dictionary_stats、bms_stats.delete_dictionary_stats 分别用于一次性收集、删除所有数据字典统计信息
1554
DBMS_STATS包里的存储过程GATHER_FIXED_OBJECTS STATS和DELETE_FIXED_OBJECTS_STATS
专用于一次性收集和删除所有的内部对象统计信息。
上述两个存储过程的用法为如下所示。
一次性地收集所有XS表的内部对象统计信息:
sqL> exec dbms_stats.gather_fixed_objects_stats();
PL/SoL procedure successfully completed
一次性地删除所有X$表的内部对象统计信息:
sql> exec dbms_stats.delete_fixed_objects_stats();
BL/SoL procedure successfui1y compieted nnnnnniint
收集单个x$(x$kccrsr) 表的对象统计信息
exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'X$KCCRSR',estimate_percent=>100,cascade=>true);
删除单个x$(x$kccrsr) 表的对象统计信息
exec dbms_stats.delete_table_stats(ownname=>'SYS',tabname=>'X$KCCRSR');
1656
查看自动收集统计信息的job运行状态
16:50:01 idle> select actual_start_date,job_name,status from (select * from dba_scheduler_job_run_details where job_name='GATHER_STATS_JOB' ORDER BY LOG_DATE DESC) where rownum <4;
no rows selected
1725
sys.mon_mods_all$
如果想马上看到目标表的insert 、update、delete,需要执行以下 dbms_stats包中的存储过程flush_database_monitoring_info;
exec dbms_stats.flush_database_monitoring_info();
select obj#,inserts,updates,deletes ,flags from sys.mon_mods_all$ where obj#=object_id;
1733
禁掉自动统计信息收集作业
exec dbms_scheduler.disable('GATHER_STATS_JOB');
只对存在直方图统计信息的列才收集直方图统计信息
exec dbms_stats.set_param('METHOD_OPT','FOR ALL COLUMNS SIZE REPEAT');
2135
尽管如此,我们还是推荐一个统计信息收集作业采样比例的初始值;
对于orede 11g及其以上的版本,收集统计信息的采样比例建议采用DBMS_STATS.AUTO_SAMPLE_SIZE.
Oracle 110中的AUTO_SAMPLE_SIZE采用了全新的哈希算法,它既能保证在较短的时间内执行完又能保证收集到的统计信息
接近采样比例为100%时的质量)。
如果是Oracle 10g,继续采用DBMS_STATS.AUTO_SAMPLE_SIZE就不太合适了,因为这个自动采样比例在Oracle 10g里是非常小的一个
Oracle 10g中将采样比例的初始值设为30%,然后根据目标SQL的实际执行情况再做调整
如果是Oracle9i,我们建议将采样比例的初始值也设为30%,然后根据目标SQL的实际执行情况再做调整
(5)建议使用DBMS_STATS包来对分区表收集全局统计信息,并且收集分区表的统计信息时应使用一致致
的GRANULARITY参数,全局统计信息的收集方法和注意事项请见“5.6全局统计信息”。
(6)建议要额外收集系统统计信息,但系统统计信息收集一次就够了,除非系统的硬件环境发生了变化,
系统统计信息的收集方法请见“5.9系统统计信息”
(7)建议要额外收集X$表的内部对象统计信息,但仅仅是在明确诊断出系统已有的性能问题是因为x$
表的内部对象统计信息不准的情形下,对于其他情形就不要收集了。X$表的内部对象统计信息的收集方法和
注意事项请见“5.1l内部对象统计信息”。
2141
适用于Oracle 11g及其以上的版本
EXEC DBMS_STATS.GATHER_TABLE_STATS(
OWNNAME=>'SCHEMA_NAME',
TABNAME=>'TABLE NAME',
ESTIMATE PERCENT=>DBMS STATS,AUTO_SAMPLE_SIZE,
CASCADE=>TRUE,
METROD_OPT=>'FOR ALL COLUMNS SIZE REPEAT'):
2144
锁住表的统计信息
dbms_stats.lock_table_stats
2148
聚簇因子的大小对CBO判断是否走相关的索引至关重要
20170426
0951
dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')
0959
只要在sql中启用 hint,那么默认启用的cbo
1012 hint格式
hint 中第一个星号 (*)和加号(+)之间不能有空格
hint zhong jiahao (+)和具体的hint内容之间可以有空格,也可以没有空格,通常都有
hint中的具体内容可以使单个hint,也可以是多个hint的组合。如果是后者,则各个hint见至少需要一个空格来彼此分隔
hint 必须紧跟 select、update、delete、insert、merge
hint 中不能跟schema哦
hint 如果后面 表指定了别名,全表扫描时 必须在hint中指定 别名
1104
_optimzer_ignore_hints 忽略sql中的 hint提示
触发器执行该操作
create or replace trigger ignore_hints_on_logon
after logon on database
begin
execute immediate 'alter session set "_optimzer_ignore_hints"=true';
end;
/
1120
对于非分区索引而言,索引范围扫描或者索引全扫描都不可能并行执行
1126
/*+ use_hash(emp) */ hash连接的hint
hash连接的被驱动表应该是数据量最多的那个表
hash连接只使用于 等值连接查询
1210
cardinality(dept 100) 表示扫描表dept得到的结果集的 cardinality设为100
1221
hint no_merge 禁用查询转换
1227
组合hint中各个hint间不要使用逗号“ ,” 来彼此分割(应该使用空格来彼此分隔)
1235 all_rows
让优化器启用cbo,而且在得到目标sql的执行计划时会选择那些吞吐量最佳的执行路径。吞吐量最佳 值资源消耗量最小(比如 i/o cpu等硬件资源)
1320
INDEX_FFS 前提条件:select语句中所有的查询列都在目标索引中,即通过扫描目标索引就可以得到所有的查询咧而不用回表
INDEX_JOIN 前提条件:select语句中所有的查询列都在目标表的多个目标索引中,即通过扫描这些索引就可以得到所有的查询列而不需要回表
1327
INDEX_FFS 执行计划
INDEX_JOIN 执行计划
1359
sou> select /*+ rule */count(*)from tii ;
Plan hash value:3110199320
rd I operation
0 I SBLECT STATEMENT
SORT AGGREGATB
I PX COORDINATOR
SORT AGGREGATE
PX BLOCR ITBRATOR I
TABLE ACCESS FULLI T1
一省略显示部分内容
可以看出,上述SQL的执行计划已经从之前的串行全表扫摘表T1变为并行全表扫描花型,8
新2ea”这表示上述SQL在解析时使用的是CBO,这也验证了之前的观点:如果日行
为用于并行执行,就意味着其中的RULE Fmnt会失效,此此时Once会自动启用cBo
1431
PARALLEL hint的格式有如下4中:
/*+ PARALLEL */
/*+ PARALLEL(AUTO) */ 此处指定 auto,那么并行度 可能为1.因此不一定会用到 parallel
/*+ PARALLEL(MANUAL) */
/*+ PARALLEL(指定的并行度) */
v$pq_slave
1451
NO_PARALLEL HINT
1521
driving_site(目标表)【强制操作在目标表执行】 原则 尽可能的减少本地节点和远程节点之间网络传输的数据量
select /*+ driving_site(t)*/ col1,col2 from remote_tab@dblink_name
1533
直接路径加载数据一定要记得启用 parallel dml
1536
/*+ APPEND_VALUES */
0937
检查绑定变量的传入值
SQL> select
snap_id,
dbms_sqltune.extract_bind(bind_data,1).value_string bindi,
dbms_sqltune.extract_bind(bind_data,2).value_string bind2,
dbms_eqltune,extract_bind(bind_data,3).value_string bind3
from dbs_hist_sqlstat
where sql_id='&sql id
order by snap_id;
Enter value for sql_id:ay29xy01d36yb
old 7:where sql_id='&sql_id'
new 7:where sgl_id='ay29xy01d36yb'
0945
执行计划中 的
Rows
30M 此处30M 也就是 30*1000*1000 =3000万 哦
0955
取样默认 5%
1108
parallel hint /*+ parallel_execution_demo_1 */
serial hint /*+ serial_execution_demo_1 */
1114
强制启用dml操作的并行
alter session force/enable parallel dml;
仅仅修改表的并行度和仅仅使用并行hint,不能真正并行执行dml。 记住!!!
1127
exec dbms_stats.gather_table_stats(ownname(用户名)=>'user_name',tabname(表名)=>'table_name',cascade=>true,estimate_percent=>100,degree(并行度)=>4 )
1255
kxfqcdty 就是列类型
kxfqcplen 就是列的最大长度
1324
dba_tab_partitions 分区以 object的形式存在
1355
granule 粒度
1403
db file scattered read 数据文件散列读
1409
v$bh.dirty (y 脏块;n 非脏块)
1412
parallel 会产生一个 parallel query checkpoing
“DBWR parallel query checkpoint buffers written”
1423
bbed
1516
要想使用并行 dml ,要么使用 alter session force parallel dml 要么使用 alter session enable parallel dml 和加了hint 的dml语句
1922
alter table table_name parallel n;
alter index index_name parallel n;
procedure 中 执行 ddl 语句,例如:
execute immediate 'alter session force parallel dml';
commit/rollback;
execute immediate 'alter session disable parallel dml';
连接池中的连接 会被重复使用哦
0915
v$tracsaction的 列 used_ublk 表示用到的 undo_block的总数
used_urec 表示用到的 undo record的总数
cr_get 表示消耗的逻辑读(consistent gets)的总数
只需监控v$tracsaction的used_urec的值的递增情况就可以知道 sql的并行执行进度
1018
单键值索引:
where col1 is not null; null 值 不会使用索引的 切记
复合键值索引:
where col1 is not null; null 值 会使用索引的 切记
1031
where col like '%aaa%' 这种情况不走索引
1049
在本书的“第2章Oracle里的执行计划”中我们已经提到,如果目标SQL的执行计划还在Shared Pool
中,那就可以使用脚本display_cursor_9i.sql和存储过程printsql来得到其真实的执行计划和资源消耗,如果目
标SOL的执行计划已经被age out出 Shared Pool了,那么我们可以执行DBMS_XPLAN.DISPLAY_AWR或者使用AWR SQL报告(获得AVR SQL报告的途径通常是手工执行脚本
SORACLE_HOME/rdbms/admin/awrsqrpt.sql,适用于Oracle 10g及其以上的版本)和Statspack SQL报告(获得
Statspack SQL报告的途径通常是手工执行脚本SORACLE_HOME/dbms/admin/sprepsql,适用于Oracle9i及其
以上的版本)来得到其历史执行计划和资源消耗(DBMS_XPLAN DISPLAY_AWR仅能查看目标SQL的历史
执行计划)。当我们得到了Top SQL的执行计划和资源消耗后,通常还会执行脚本sosibxt来获得上述Top SooL
中相关对象的统计信息来辅助诊断,甚至还可能会对上述Top SL.使用10046/10053等事件,综合上述内容后
你可以分析出此Top SOL的执行计划是否合理,是否存在性能问题了。display_cursor_9i.sql、printql和
sosi.txt 都可以通过我网站上的Books专栏下载,网址为http /www dbsnake.net/books
1106
计算牟表的数据量
sum(bytes)/1024/1024 dba_segments
计算某个字段的 可选择率
select count(col_name),count(distinct col_name) from table_name
--进程在等待什么
select t.EVENT#,t.PROGRAM,t.SECONDS_IN_WAIT,t.STATE from v$session t where t.USERNAME='' and t.status='ACTIVE';
--1129
select t.TABLE_NAME,t.NUM_ROWS,t.BLOCKS,t.AVG_ROW_LEN,t.PARTITIONED,t.NUM_ROWS*t.AVG_ROW_LEN/1024/1024/0.9 est_M from dba_tables t