前一段时间阿里云ET在阿里园区举办过一个活动,就是在春节之前为阿里巴巴的员工写春联。之前春节之前都是邀请书法专家为阿里员工写春联,而这次就借助了阿里云人工智能将写春联活动自动化实现了。
接下来分享一下阿里云人工智能ET到底是什么样的东西,一起来看一看阿里云ET究竟有哪些能力。
ET能力一:学马总说话&唱歌

ET可以学会马总说话,当然也可以学会胡晓明说话。其实这后面存在很多云语音库,就像高德地图有郭德纲版和林志玲版一样,而且ET除了说话之外还能够唱歌。
ET能力二:双十一天猫晚会表演魔术

在去年的天猫双11晚会中,ET在主持人华少的帮助下表演了魔术,这个魔术的效果大概是:华少请现场的五位女性观众参与,并为她们每人手中发一张牌,她们手中的牌也是由自己随机挑选的,最后ET通过人脸识别的分析以及拿到黑色牌的女观众转身等一系列的交互猜出每个人手中拿的究竟是哪一张牌。
ET能力三:为阿里巴巴员工写春联

ET还能够写春联,图中就是春节前ET为阿里巴巴员工写春联的活动。可以看到春联是由机械臂完成书写的,但是这背后却是利用阿里云ET去分析每位同学的特征,包括表情、人脸特征、性别以及年龄等,再去通过人脸识别所分析出来的结果以及同学的口述表达去了解该同学的新年愿望,然后根据这些特征匹配出一副相对应的春联,并将信息传递给机械手臂,让机械手臂去完成春联的书写。
上面就介绍了阿里云ET目前已经有的三个能力,而这些能力其实都是由前端发起的交互,那么隐藏在这些能力背后的究竟是哪些技术呢?
其实隐藏在阿里云ET背后的技术能力可以分为以下两个大部分:

- 基础技术能力。智能语音交互,包括自然语言理解和人机对话,ET需要理解用户对它说了些什么,并且分析出这里面蕴含了哪些意思,再根据用户的意思分析出应该如何回答。还有就是人脸识别,其实这在天猫双11的交互里面可以看到,ET需要通过对于每一个女性观众的脸分析出她们各自所抽取的牌。
- 机器学习能力。这部分属于比较高阶的功能,ET在不同的交互场景中就会拥有不同的能力,像在魔术表演中,ET就学会了根据排列的结果去推算观众手上牌的能力。还有就是在写春联活动中学会与机械手臂进行交互。
那么在ET交互效果的背后是哪些技术能力的支撑呢?接下来首先看一下通过天猫双11会场ET所表现出来的交互效果背后的技术架构。
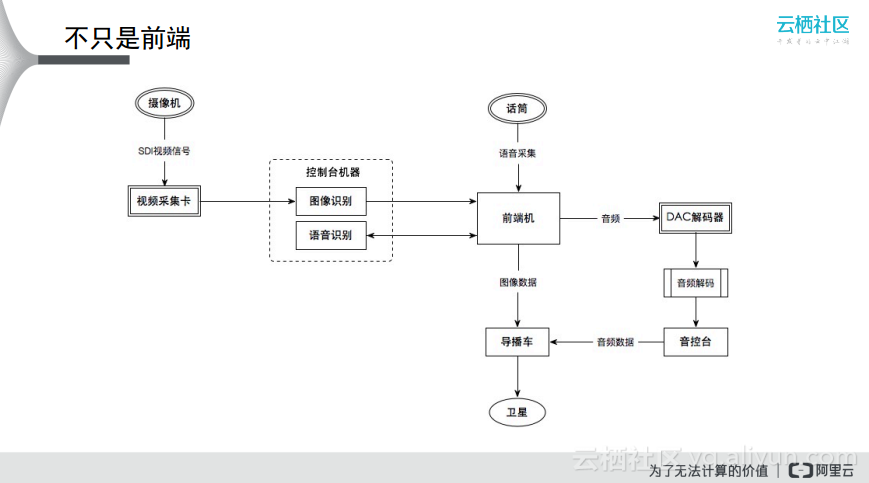
首先由于天猫双11晚会是现场直播的,所以会有很多机位可以从不同的角度进行拍摄,而摄像机直接使用的是电视台的摄像机,摄像机首先采集图像信息然后上传到视频采集卡上,最终到达控制台机器上,这就是视频信号的输入。另外对于音频信号而言,需要对于音频进行压缩,因为直接通过话筒说话与后端的采样是不匹配的,所以音频可以在前端机中做一定的处理,再将音频传输到控制台机器。控制台机器分别对于图像和语音进行识别,再将这两个结果返回给前端机,之后将结果通过不同的方式传导到导播车上,最终通过卫星传送到电视机上,这就是天猫双11晚会的架构,如果要想保证天猫双11晚会的交互流畅性和稳定性,避免在前端机和控制机之间出现卡顿,就需要进行特殊的处理,那么怎么去保证数据传输的稳定性呢?
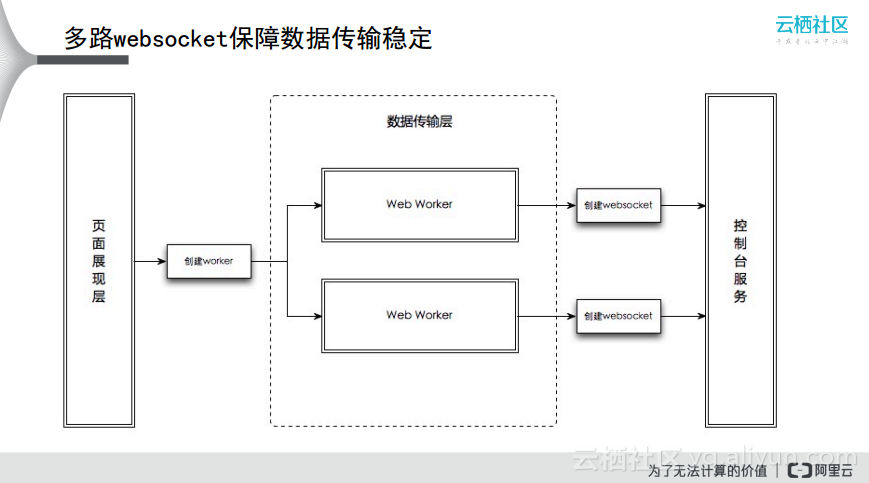
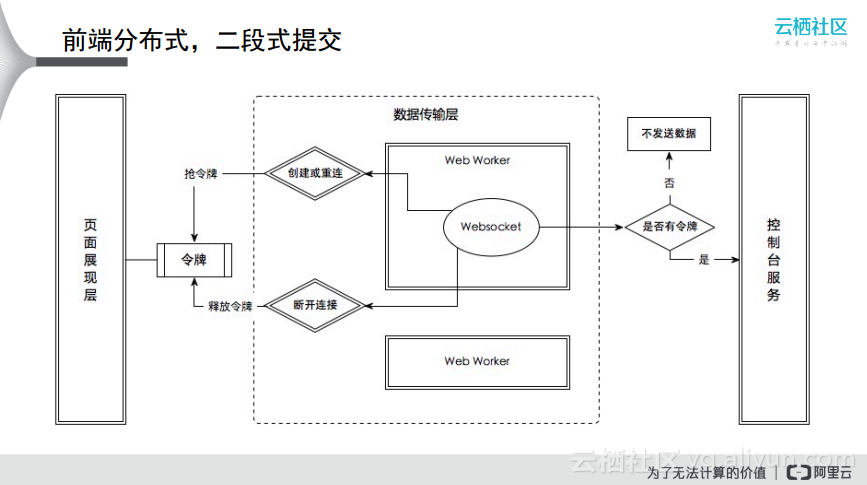
为了保证数据传输的稳定性,阿里云做了很多事情。第一个就是通过多路WebSocket来保证数据传输稳定,在页面展现层和控制台服务中间增加了数据传输层,将数据传输委托给了两个Web Worker,两个Web Worker所做的事情是相同的,只不过为了保证单个节点挂掉时的高可用性,而两个Web Worker同时向控制台获取服务时可能会出现冗余情况,而阿里云在这方面也做了相应的处理。其实就是在这部分加上了抢令牌的过程,每一个Web Worker都会在前端页面展现层这部分去抢令牌,当抢到令牌的时候才有能力去向后端控制台服务获取数据,如下图所示就是通过前端的分布式二段式提交。
而在语音处理部分,前端所做的工作会比较多一些。首先对于语音输入的过程中,用了Media Stream Recorder方案来兼容很多浏览器,之后将语音采集到之后可能需要对于采集到的语音进行降噪处理,这部分主要在对于一些硬件设备进行优化,效果还是比较明显的,现场的语音识别率从70%提升到了90%。因为天猫双11晚会的现场会有很多噪音,并且主持人华少的语速也比较快,所以如果没有降噪的处理,语音识别率就会比较低。
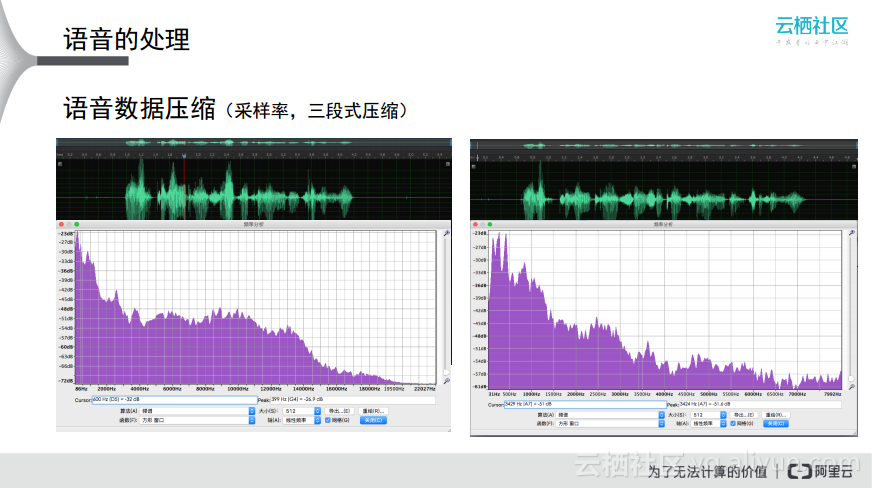
在语音这部分还会涉及到采样率的问题,简单理解就是采样率越高,音频质量就会越高,同时产生的文件也就会越大,需要传输的数据量也会更大。那么阿里云ET在这方面做了哪些处理呢?首先浏览器默认的语音采样率是44千赫兹,而后端的接口所能接收的采样率是16千赫兹,这里就将采集到的数据做了三段式处理,简单而言就是每隔三段取一个小段然后串联起来。
ET机器学习的能力
在基础的能力之外,ET还学习了一些更高级的能力,下面通过案例解析一下器其背后的实现原理。