伴随着今日阿里云机器学习PAI在云栖大会的重磅发布,快来感受下人工智能的魅力。
一、背景
随着互联网的发展,产生了大量的图片以及语音数据,如何对这部分非结构化数据行之有效的利用起来,一直是困扰数据挖掘工程师的一到难题。首先,解决非结构化数据常常要使用深度学习算法,上手门槛高。其次,对于这部分数据的处理,往往需要依赖GPU计算引擎,计算资源代价大。本文将介绍一种利用深度学习实现的图片识别案例,这种功能可以服用到图片的检黄、人脸识别、物体检测等各个领域。
下面尝试通过阿里云机器学习平台产品,利用深度学习框架Tensorflow,快速的搭架图像识别的预测模型,整个流程只需要半小时,就可以实现对下面这幅图片的识别,系统会返回结果“鸟”:
二、数据集介绍
本案例数据集及相关代码下载地址:https://help.aliyun.com/document_detail/51800.html?spm=5176.doc50654.6.564.mS4bn9
使用CIFAR-10数据集,这份数据是一份对包含6万张像素为32*32的彩色图片,这6万张图片被分成10个类别,分别是飞机、汽车、鸟、毛、鹿、狗、青蛙、马、船、卡车。数据集截图:
数据源在使用过程中被拆分成两个部分,其中5万张用于训练,1万张用于测试。其中5万张训练数据又被拆分成5个data_batch,1万张测试数据组成test_batch。最终数据源如图: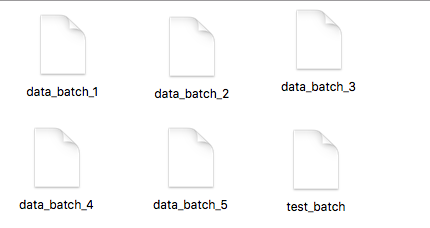
三、数据探索流程
下面我们一步一步讲解下如何将实验在阿里云机器学习平台跑通,首先需要开通阿里云机器学习产品的GPU使用权限,并且开通OSS,用于存储数据。
机器学习:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.112.IOG7OU
OSS:https://www.aliyun.com/product/oss?spm=a2c0j.103967.416540.50.KkZyBu
1.数据源准备
第一步,进入OSS对象存储,将本案例使用的相关数据和代码放到OSS的bucket路径下。首先建立OSS的bucket,然后我建立了aohai_test文件夹,并在这个目录下建立如下4个文件夹目录:
每个文件夹的作用如下:
-
check_point:用来存放实验生成的模型
-
cifar-10-batches-py:用来存放训练数据以及预测集数据,对应的是下载下来的数据源cifar-10-batcher-py文件和预测集bird_mount_bluebird.jpg文件
-
predict_code:用来存放训练数据,也就是cifar_pai.py
-
train_code:用来存放cifar_predict_pai.py
本案例数据集及相关代码下载地址:https://help.aliyun.com/document_detail/51800.html?spm=5176.doc50654.6.564.mS4bn9
2.配置OSS访问授权
现在我们已经把数据和训练需要的代码放入OSS,下面要配置机器学习对OSS的访问,进入阿里云机器学习,在“设置”按钮的弹出页面,配置OSS的访问授权。如图:
3.模型训练
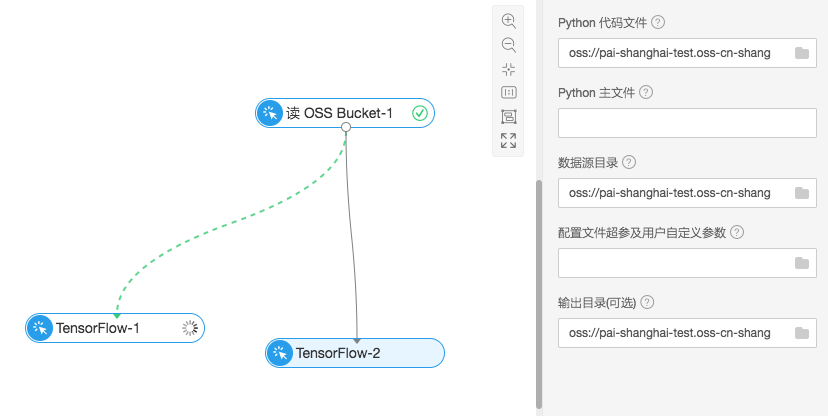
从左边的组件框中拖拽“读OSS Bucket”以及“Tensorflow”组件链接,并且在“Tensorflow”的配置项中进行相关设置。
- Python代码文件:OSS中的cifar_pai.py
- 数据源目录:OSS中的cifar-10-batches-py文件夹
- 输出目录:OSS中的check_point文件夹
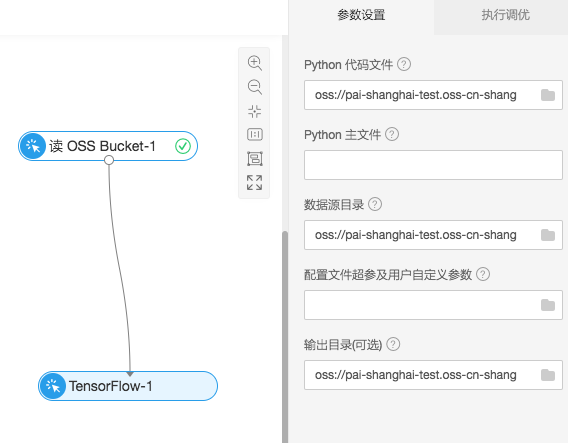
点击运行,实验开始训练,可以针对底层的GPU资源灵活调节,除了界面端的设置,需要在代码中也有相应的支持,代码编写符合Tensorflow的多卡规范。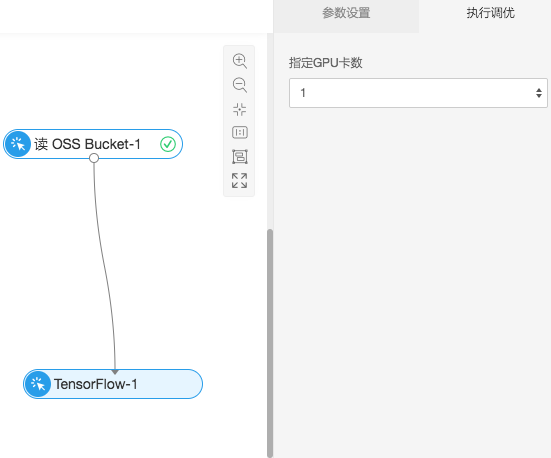
4.模型训练代码解析
这里针对cifar_pai.py文件中的关键代码讲解:
(1)构建CNN图片训练模型
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
(2)训练生成模型model.tfl
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=100, shuffle=True, validation_set=(X_test, Y_test),
show_metric=True, batch_size=96, run_id='cifar10_cnn')
model_path = os.path.join(FLAGS.checkpointDir, "model.tfl")
print(model_path)
model.save(model_path)
5.查看训练过程中的日志
训练过程中,右键“Tensorflow”组件,点击查看日志。
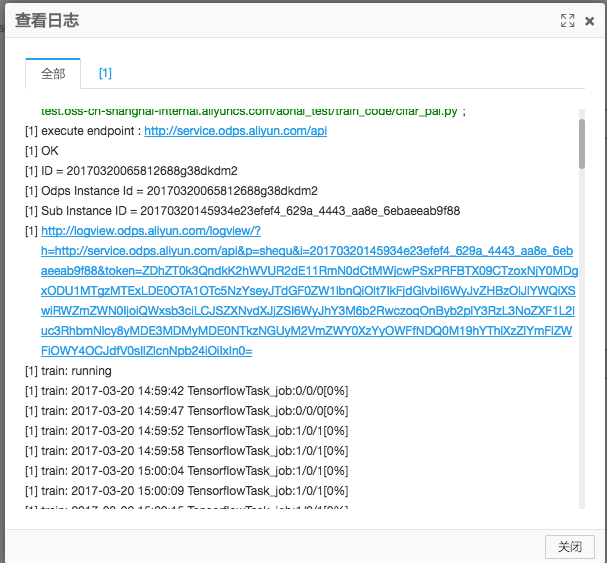
点击打开logview连接,按照如下链路操作,打开ODPS Tasks下面的Algo Task,双击Tensorflow Task,点击StdOut,可以看到模型训练的日志被实时的打印出来: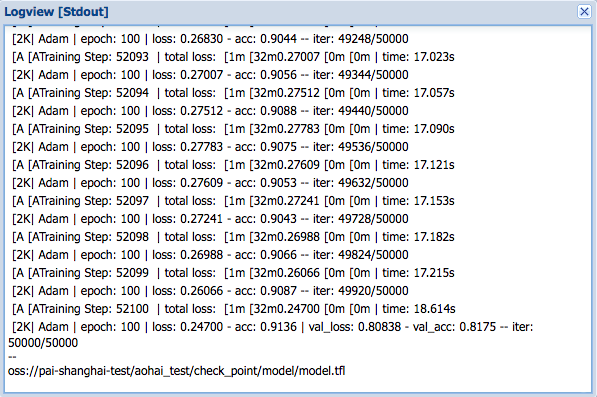
随着实验的进行,会不断打出日志出来,对于关键的信息也可以利用print函数在代码中打印,结果会显示在这里。在本案例中,可以通过acc查看模型训练的准确度。
5.结果预测
再拖拽一个“Tensorflow”组件用于预测,
- Python代码文件:OSS中的cifar_predict_pai.py
- 数据源目录:OSS中的cifar-10-batches-py文件夹,用来读取bird_mount_bluebird.jpg文件
- 输出目录:读取OSS中的check_point文件夹下模型训练生成的model.tfl模型文件
预测的图片是存储在checkpoint文件夹下的图:
结果见日志: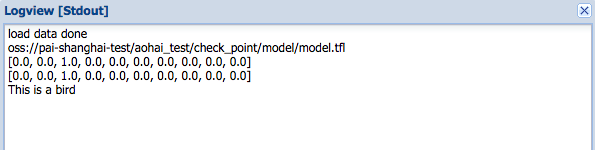
6.预测代码数据
部分预测代码解析:
predict_pic = os.path.join(FLAGS.buckets, "bird_bullocks_oriole.jpg")
img_obj = file_io.read_file_to_string(predict_pic)
file_io.write_string_to_file("bird_bullocks_oriole.jpg", img_obj)
img = scipy.ndimage.imread("bird_bullocks_oriole.jpg", mode="RGB")
# Scale it to 32x32
img = scipy.misc.imresize(img, (32, 32), interp="bicubic").astype(np.float32, casting='unsafe')
# Predict
prediction = model.predict([img])
print (prediction[0])
print (prediction[0])
#print (prediction[0].index(max(prediction[0])))
num=['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
print ("This is a %s"%(num[prediction[0].index(max(prediction[0]))]))
首先读入图片“bird_bullocks_oriole.jpg”,将图片调整为像素32*32的大小,然后带入model.predict预测函数评分,最终会返回这张图片对应的十种分类['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']的权重,选择权重最高的一项作为预测结果返回。