字符串
特性:有序、不可变
字符串的索引和切片
索引是按照正向递增(从0开始),反向递减从-1开始。s[索引]返回索引的字符串值
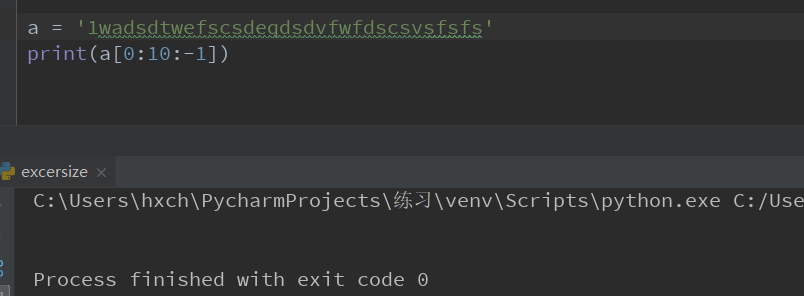
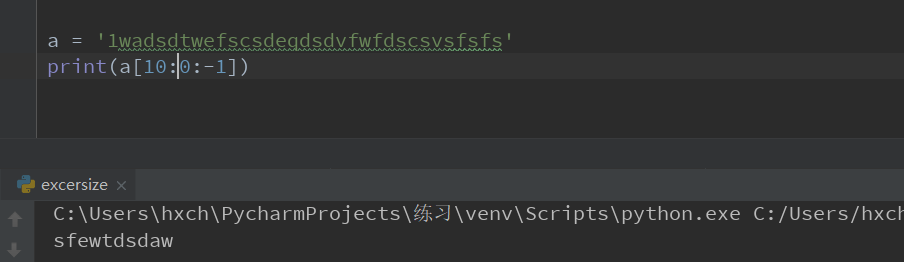
切片s[M:N:K]返回切片的字符串。当K为负值时,M>N
>>> s = 'ABCDEFGHIJK' >>> s[2] 'C'
>>> s = 'ABCDEFGHIJK'
>>> s[1:5:2] # 可以进行切片
'BD'
当K为赋值的时候,M<N什么都不输出,M>N才会输出结果
字符串不可变
>>> s = 'ABCDEFGHIJK' # 不能对字符串的内部子串进行赋值修改
>>> s[2] = 'z'
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
s[2] = 'z'
TypeError: 'str' object does not support item assignment
>>> s = 'ABCDEFGHIJK'
>>> a = s >>> print(id(s),id(a)) # 赋值完成后,连个字符串的内存地址一样,指向的是同一个内存地址 89703232 89703232 >>> s = 'james' # s发生改变后,s和a的内存地址不一样了 >>> print(id(s),id(a)) 104912864 89703232
字符串的循环
>>> for i in a: print(i) A B C D E F G H I J K >>> for index,i in enumerate(a): # 获取索引和对应的字符串子串的值 print(index,i) 0 A 1 B 2 C 3 D 4 E 5 F 6 G 7 H 8 I 9 J 10 K
字符串的方法
大小写转换的方法有以下几种:
s.upper(): 字符串全部字符转换为大写
>>> s = 'AbCdEFghijK'
>>> s.upper()
'ABCDEFGHIJK'
s.lower():字符串全部字符转换为小写
>>> s = 'AbCdEFghijK'
>>> s.lower()
'abcdefghijk'
s.swapcase() :字符串全部字符大小写互换
>>> s = 'AbCdEFghijK'
>>> s.swapcase()
'aBcDefGHIJk'
s.capitalize():字符串首个单词首字母大写
>>> s = 'james hsiao'
>>> s.capitalize()
'James hsiao'
s.title(): 字符串中全部单词首字母大写
>>> s = 'james hsiao'
>>> s.title()
'James Hsiao'
这些用法不需要加参数,不会修改原有的s。
s.replace(old,new,count)将s中的old子串,替换成new,count为替换的次数(如果子串中有相同的就要用到)
>>> s.replace("a", '好') # 把s中的“a”,用‘好’替换
'my n好me is J好mes hsi好o'
>>> s = 'my name is James hsiao'
>>> s.replace("a", '好',2) # 只替换两处
'my n好me is J好mes hsiao'
字符串去除两侧指定内容的方法有三种:
s.strip(chars) :去除字符串两侧的指定内容,并且同时去除多个相同的指定内容;参数chars为指定的一个或多个字符,不填入该参数则去除字符串两侧所有空格。
s.lstrip(chars) :去除字符串左侧的指定内容,并且同时去除多个相同的指定内容;参数chars为指定的一个或多个字符,不填入该参数则去除字符串左侧所有空格。
s.rstrip(chars) :去除字符串右侧的指定内容,并且同时去除多个相同的指定内容;参数chars为指定的一个或多个字符,不填入该参数则去除字符串右侧所有空格。
>>> s = '####my name is James hsiao###'
>>> s.strip("#")
'my name is James hsiao'
>>> s = '####my name is James hsiao###'
>>> s.lstrip('#')
'my name is James hsiao###'
>>> s = '####my name is James hsiao###'
>>> s.rstrip('#')
'####my name is James hsiao'
>>> s # 对原始的s并没有修改后赋值
'####my name is James hsiao###'
s.index(元素,M,N)返回元素的索引 从左往右查找,多个相同值时只查最前面一个 可以指定M和N索引查找,缺失默认至开头和至结尾
>>> s = 'AbCdEFghijKb'
>>> s.index("b")
1
>>> s = 'AbCdEFghijKb'
>>> s.index("b",2) # N缺失代表至结尾,返回‘b’在整个s中的索引
11
>>> s = 'AbCdEFbghijKb'
>>> s.index("b",2,10) # 返回‘b’在整个s中的索引
6
s.rindex(元素,M,N)从右往左查找
>>> s = 'AbCdEFbghEjKb'
>>> s.rindex('E')
9
s.find(元素,M,N)在s中检测元素是否在其中,在的话返回其索引,不在返回-1.
>>> s = 'AbCdEFbghEjKb'
>>> s.find('b')
1
>>> s = 'AbCdEFbghEjKb'
>>> s.find("1")
-1
s.rfind(元素,M,N)从右往左查找
s.count(x,M,N)返回x在s中出现的次数,M和N为指定的索引
s.center(width,fillchar)width为总共的长度 fillchar为填充的字符,缺失默认为空格
>>> s = 'AbCdEFbghEjKb'
>>> s.center(30,"@")
'@@@@@@@@AbCdEFbghEjKb@@@@@@@@@'
s.isdigit()判断字符串中是不是只包含数字,是返回True,不是返回False
>>> s = 'AbCdEFbghEjKb'
>>> s.isdigit()
False
s.startswith(元素,M,N) 判断是否以...开头,M和N为指定的索引位置,是返回True, 不是返回False
s.endswith(元素,M,N)判断是否以...结尾,M和N为指定的索引位置是返回True, 不是返回False
s.split(char)把s按照指定的char进行分割,返回分割后的列表,如果char不在s中,直接返回由s作为元素的列表
>>> s = 'AbCdEFbghEjKb' # 字符串转换成列表
>>> s.split('b')
['A', 'CdEF', 'ghEjK', '']
>>> s = 'AbCdEFbghEjKb'
>>> s.split('z')
['AbCdEFbghEjKb']
字符串直接转换成列表:list(str)
>>> a = 'jameshsiao'
>>> a = list(a) # 迭代的拆开组成列表的元素
>>> a
['j', 'a', 'm', 'e', 's', 'h', 's', 'i', 'a', 'o']
char.join(s)把字符串s每单个字符用char连接,返回的是字符串(s必须是可迭代的,不能是数字和布尔值)
>>> s = 'AbCdEFbghEjKb'
>>> '_'.join(s)
'A_b_C_d_E_F_b_g_h_E_j_K_b'
>>> L = ['james', 'tony', 'alex', 'emily']
>>> '##'.join(L) # 列表转换成字符串
'james##tony##alex##emily'
#####is系列
name='jinxin123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isdigit()) #字符串只由数字组成
isdecimal() # 如果字符串只包含十进制数字则返回True,否则返回False。
isspace() # 如果字符串中只包含空格,则返回True,否则返回False。
splitlines(([keepends])) # 按照‘
’分隔,返回一个包含各行作为元素的列表,如果keepends参数指定,则返回前keepends行。
partition(sub) # 找到子字符串sub,把字符串分成一个3元组(pre_sub,sub,fol_sub),如果字符串中不包含sub则返回(‘原字符串’, ’’, ’’)
zfill(width) # 返回长度为width的字符串,原字符串右对齐,前边用0填充。
translate(table) # 根据table的规则(可以由str.maketrans(‘a’,‘b’)定制)转换字符串中的字符。
casefold() # 把整个字符串的所有字符改为小写
字符串格式化之format,{}
通过位置参数 In [1]: '{0},{1}'.format('kzc',18) Out[1]: 'kzc,18' In [2]: '{},{}'.format('kzc',18) Out[2]: 'kzc,18' In [3]: '{1},{0},{1}'.format('kzc',18) Out[3]: '18,kzc,18' 关键字参数 In [5]: '{name},{age}'.format(age=18,name='kzc') Out[5]: 'kzc,18'
range(M:N:K)K为负数时,M>N
for i in range(1,10): print(i) for i in range(1,10,2): # 步长 print(i) for i in range(10,1,-2): # 反向步长 print(i)