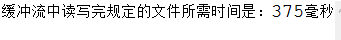---恢复内容开始---
字节流VS缓冲流
java.io包中的类大致可以分为:InputStream、OutputStream、Reader、Writer。InputStream/Reader可以理解为input from数据源,OutputStream/Writer可以理解为output to数据目的地。他们的前者处理的是字节,后者处理的是字符。而数据源则可能是来自硬盘上的文件、内存中的变量、网络的数据等等。
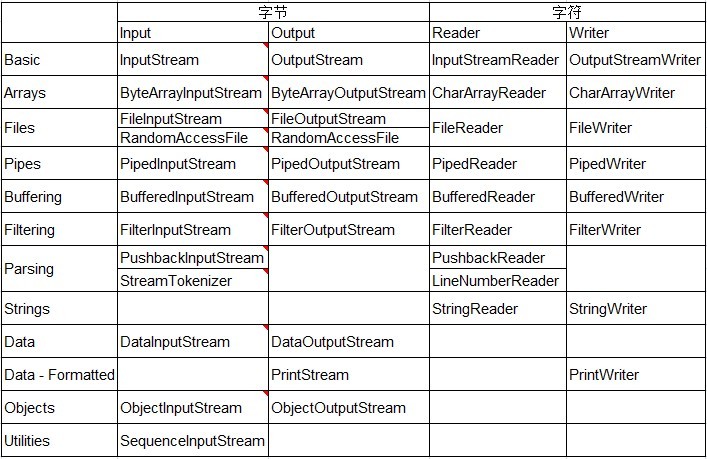
字节流:数据是以字节为单位进行读写操作
缓冲流:将一个一个的字节先存入到缓冲区中
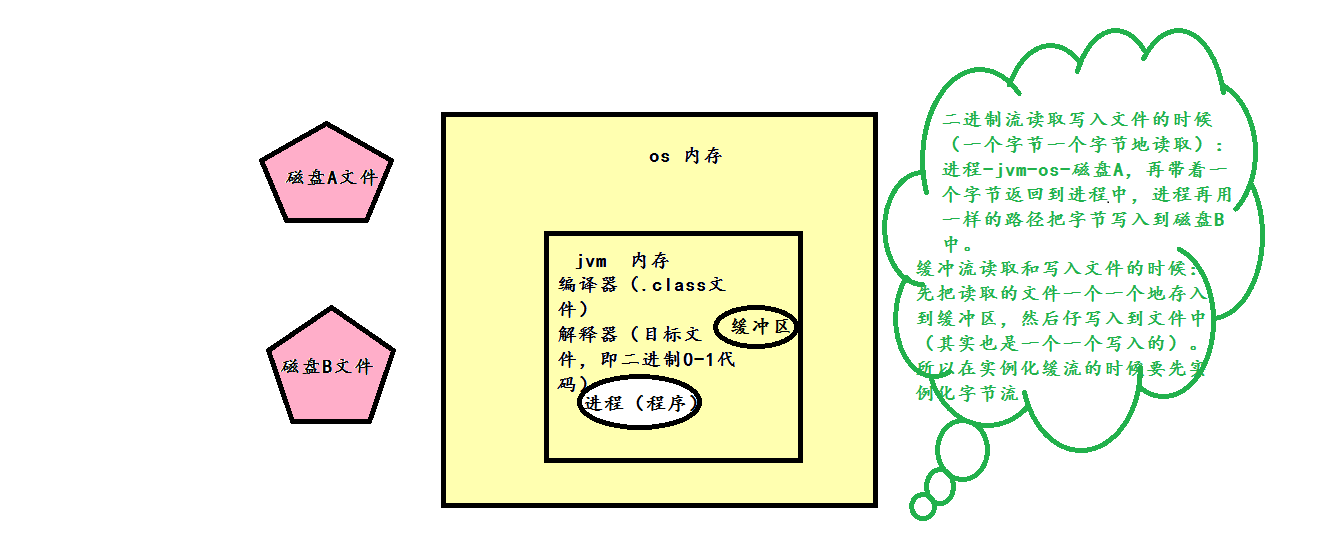
在JVM中会开辟一块缓冲区的内存空间,然后将文件中的数据读取到缓冲区中,直到读满这个缓冲,才会将缓冲区中的数据获取到程序中。
在JVM中会开辟一块缓冲区的内存空间,然后将程序中的数据写入到缓冲区中,直到写满这个缓冲,才会将缓冲区中的数据写入到文件中。
缓冲流的原理:
缓冲流作用是把数据先写入缓冲区,等缓冲区满了,再把数据写到文件里。这样效率就大大提高了。
思考的问题:在一个只有一个人用网,网速稳定(10m)的完美情况下,怎样才能使下载速度达到5m/s的速度呢?或者是思考一下迅雷下载的原理。
原理是这样的:你的电影是在服务器上下载的,迅雷会在他的服务器和你的客户端之间建立一个高速缓存器,并且实现一个进程多个线程的高速并发下载,即把你的电影二进制文件分段多线程下载,这样下载速度就上去了!
注意的点:
1.读文件的时候,也是一个字节地去读的,但是要直到读满这个这个缓冲才会将缓冲区的数据获取到程序中;
2.写文件的时候,是将程序中的数据写入到缓冲区,直到写满这个缓冲区才会把缓冲区中的数据一次性写入到文件中。
下面来比较一下字符流与缓冲流的运行速度:
这是字符流:
public class ByteDemo { public static void main(String[] args) { ByteDemo bd=new ByteDemo(); bd.copyFile("D:/Java/J2SE6.0 中文版API.chm", "D:/Java/J2SE6.0 中文版APIty.chm"); } public void copyFile(String path,String newpath){ InputStream is = null ; OutputStream os; String str; try { long startTime = System.currentTimeMillis();// 获取开始的时间 //实例化一个输入流对象 is = new FileInputStream(path); int size; try { size = is.available();// 获取流中还能读取的字节数 // 创建数组 byte[] array = new byte[size]; // 开始读取文件中的数据 is.read(array); str = new String(array);// 将字节数组转换为字符串 //System.out.println(str); //实例化一个输出对象 os=new FileOutputStream(newpath); os.write(array); long endTime = System.currentTimeMillis();// 结束时间 System.out.println("查找玩所有的文件所需的时间是:" + (endTime - startTime) + "毫秒"); } catch (IOException e) { e.printStackTrace(); } } catch (FileNotFoundException e) { e.printStackTrace(); } } }
这是缓冲流:
public class BufferedDemo { public static void main(String[] args) { BufferedDemo bd = new BufferedDemo(); bd.copyFile("D:/Java/J2SE6.0 中文版API.chm", "D:/Java/J2SE6.0 中文版APIty.chm"); } /** * 拷贝文件的方法 * * @param path要拷贝的文件路径以及文件全名 * @param newPath要存储的新文件路径以及完全全名 */ public void copyFile(String path, String newPath) { InputStream is = null; BufferedInputStream bis = null; OutputStream os = null; BufferedOutputStream bos = null; try { long startTime = System.currentTimeMillis();// 获取开始的时间 // 实例化一个输入流的对象 is = new FileInputStream(path); // 实例化一个缓冲输入流对象 bis = new BufferedInputStream(is); int size = bis.available();// 获取流中还能读取的字节数 // 创建数组 byte[] array = new byte[size]; // 开始读取文件中的数据 bis.read(array); // System.out.println(new String(array)); // 实例化一个输出流的对象 os = new FileOutputStream(newPath); // 实例化一个缓冲输出流对象 bos = new BufferedOutputStream(os); bos.write(array); int in; while ((in = bis.read()) != -1) { bos.write(in); } bos.flush();// 强制写入 long endTime = System.currentTimeMillis();// 结束时间 System.out.println("查找玩所有的文件所需的时间是:" + (endTime - startTime) + "毫秒"); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }
/*
这一段代码的作用是:因为BufferedInputStream为别的输入流添加缓冲功能,在创建BufferedInputStream时会创建一个内部缓冲数组,
用于缓冲数据,提高性能。默认的缓冲大小是8192个字节,如果你要读取的文件大于这个默认的大小时,缓冲区没有读满是不会被写入文件的。
所以要关闭输入流,释放这个流的资源。或者用flush()这个命令强制写入。
*/
finally { try { if (bos != null) bos.close(); if (os != null) os.close(); if (bis != null) bis.close(); if (is != null) is.close(); } catch (Exception e) { e.printStackTrace(); } } } }
运行速度的对比:(578 字节大小的文件)