一、产生
Hadoop MapReduce诞生于搜索领域,主要解决搜索引擎面临的海量数据处理扩展性差的问题。
二、MapReduce设计目标:
1. 易于编程:产痛的分布式程序设计非常复杂,用户需要关注的细节非常多,比如数据分片、数据传输、节点间通信等,因而设计分布式程序的门槛非常高。
2. 良好的扩展性:当数据量增加到一定程度时,可以通过添加机器来达到线性扩展集群能力的目的。
3. 高容错性:在分布式环境下,随着集群规模的增加,集群中的故障率会显著增加。
三、 MapReduce编程模型概述:
MapReduce由两个阶段组成:Map和Reduce,用户只需编写map()和Reduce()两个函数,即可完成简单的分布式程序的设计。
- Map函数以key/value对作为输入,产生另外一系列key/value作为中间输出写入本地磁盘。MapReduce框架会自动将这些中间数据按照key值进行聚集,且key值相同(用户可以设定聚集策略,默认情况下是对key值进行哈希驱魔)的数据被统一交给reduce()函数处理。
- Reduce函数以key及对应的value列表作为输入,经合并key相同的value值后,产生另外一系列key/value对作为最终输出写入HDFS。
Hadoop将输入数据切分成若干个输入分片,并将每个split交给一个Map Task处理,Map Task不断地从对应的split中解析出一个个key/value,并调用map()函数处理,处理完之后根据Reduce Task个数将结果分成若干个分片partition写到本地磁盘;同时,每个Reduce Task凑够每个Map Task上读取属于自己的那个partition,然后基于排序的方法将key相同的数据聚集在一起,调用reduce()函数处理,并将结果输出到文件中。

四、Hadoop基本架构
HDFS架构
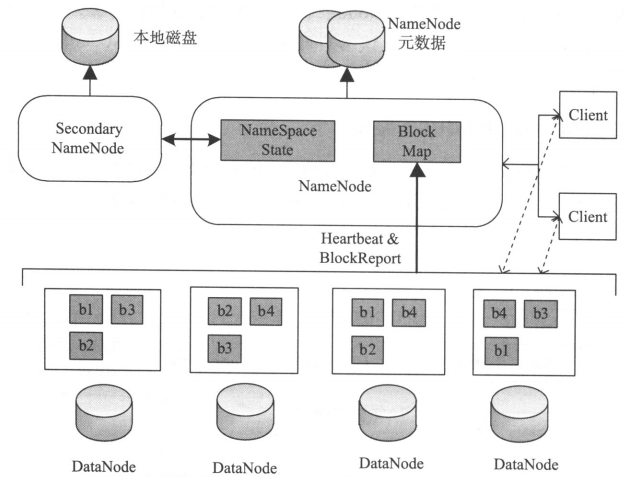
- Client:代表用户通过NameNode和DataNode交互访问HDFS中的文件,Client提供了一个类似POSIX文件系统接口供用户调用。
- NameNode:整个Hadoop集群中只有一个NameNode,它是整个系统的“总管”,负责管理HDFS的目录树和相关的文件元数据信息,这些信息是以“fsimage”(HDFS元数据镜像文件)和“editlog”(HDFS文件改动日志)两 个文件形式存放在本地磁盘,当HDFS重启时重新构造出来的。此外,NameNode还负责监控各个DataNode的健康状态,一旦发现某个DataNode宕掉,则将该DataNode移出HDFS并重新备份其上面的数据。
- Secondary NameNode:Secondary NameNode最重要的任务并不是为NameNode元数据进行热备份,而是定期合并fsimage和edits日志,并传输给NameNode,这里需要注意的是,为了较小NameNode压力,NameNode自己并不会合并fsimage和edits,并将文件存储到磁盘上,而是交由Secondary NameNode完成。
- DataNode:一般每个slave节点上安装一个DataNode,它负责实际的数据局存储,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况是64M。当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode。这种文件切割后存储的过程是对用户透明的。