下载针对Ubuntu 的安装文件pig-0.10.0.tar.gz ,0.10.0 可以运行在Hadoop 0.20.x 的版本之上,
下载安装pig 的版本要和自己在安装的hadoop版本匹配。
把 pig-0.10.0 文件 放到Linux 系统的当前用户下,
解压 pig-0.10.0 文件 tar -vxf pig-0.10.0.tar.gz
配置环境变量 /etc/profile 可以使用vi 也可以使用 sudo gedit
命令: sudo gedit /etc/profile
#set pig
export PIG_HOME=/home/liucheng/pig-0.10.0
同时,要配置到path路径下
使配置文件生效 source /etc/profile
进入pig 的bin 目录下 启动pig
命令 :./pig 或是 ./pig -x mapreduce
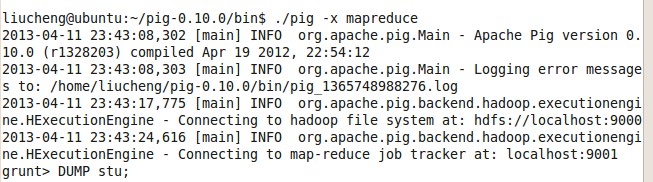
这个时间,就可以使用jps 查看已经启动的线程,有两个 grunt 线程
在grunt> 下打出Help 就可以查看 pig 可以使用的命令
在pig 命令下可以直接操作HDFS
以后的pig 命令 就会转成 mapreduce 运行。
grunt> stu = LOAD '/user/liucheng/pig/student.txt' AS (name,age);

把HDFS pig 目录下的student.txt 转存为关系stu,默认每行数据是以"\t" 分割。
当调用DUMP stu; 可以查看存储到stu 关系中的数据。
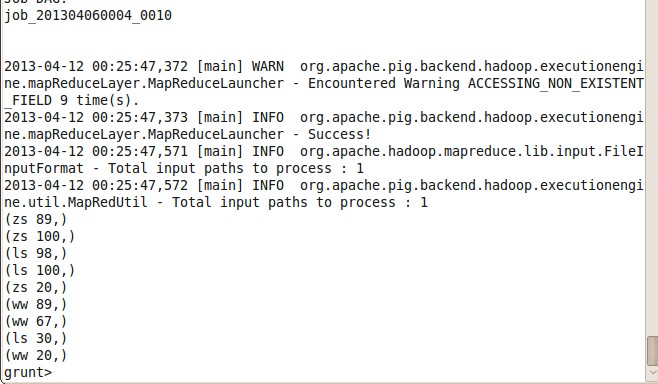
注:当使用quit 退出此次会话时,那么这个关系stu 也会丢失的。
pig 调用 脚本文件。
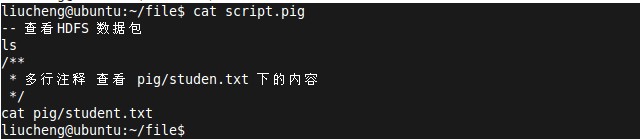
第一步:我们在当前用户的file 目录下创建一个script.pig 文件。内容为
ls
cat pig/student.txt
第二步:查看一下HDFS 上有哪些文件,且pig/student.txt 文件的内容
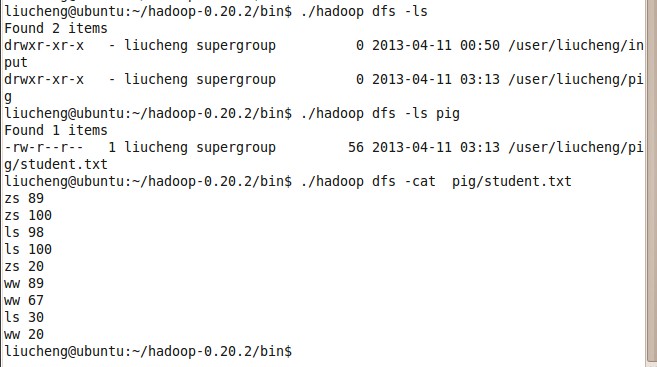
第三步:调用我们创建的 ~/file/script.pig 角本。pig ~/file/script.pig
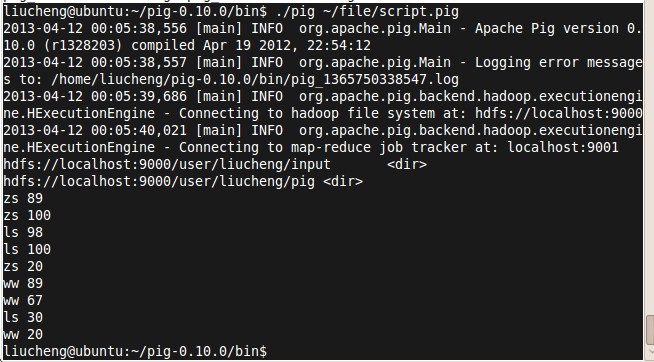
分析:系统调用mapreduce 分析处理角本内容,第一个列表所有HDFS 文件,且,把pig/student.txt 内容读出来。
接下来的学习参考:http://www.cnblogs.com/uttu/archive/2013/02/19/2917438.html