大数据介绍
大数据本质也是数据,但是又有了新的特征,包括数据来源广、数据格式多样化(结构化数据、非结构化数据、Excel文件、文本文件等)、数据量大(最少也是TB级别的、甚至可能是PB级别)、数据增长速度快等。
针对以上主要的4个特征我们需要考虑以下问题:
-
数据来源广,该如何采集汇总?,对应出现了Sqoop,Cammel,Datax等工具。
-
数据采集之后,该如何存储?,对应出现了GFS,HDFS,TFS等分布式文件存储系统。
-
由于数据增长速度快,数据存储就必须可以水平扩展。
-
数据存储之后,该如何通过运算快速转化成一致的格式,该如何快速运算出自己想要的结果?
对应的MapReduce这样的分布式运算框架解决了这个问题;但是写MapReduce需要Java代码量很大,所以出现了Hive,Pig等将SQL转化成MapReduce的解析引擎;
普通的MapReduce处理数据只能一批一批地处理,时间延迟太长,为了实现每输入一条数据就能得到结果,于是出现了Storm/JStorm这样的低时延的流式计算框架;
但是如果同时需要批处理和流处理,按照如上就得搭两个集群,Hadoop集群(包括HDFS+MapReduce+Yarn)和Storm集群,不易于管理,所以出现了Spark这样的一站式的计算框架,既可以进行批处理,又可以进行流处理(实质上是微批处理)。
-
而后Lambda架构,Kappa架构的出现,又提供了一种业务处理的通用架构。
-
为了提高工作效率,加快运速度,出现了一些辅助工具:
- Ozzie,azkaban:定时任务调度的工具。
- Hue,Zepplin:图形化任务执行管理,结果查看工具。
- Scala语言:编写Spark程序的最佳语言,当然也可以选择用Python。
- Python语言:编写一些脚本时会用到。
- Allluxio,Kylin等:通过对存储的数据进行预处理,加快运算速度的工具。
大数据方向的工作目前主要分为三个主要方向:
- 大数据工程师
- 数据分析师
- 大数据科学家
- 其他(数据挖掘等)
技能要求
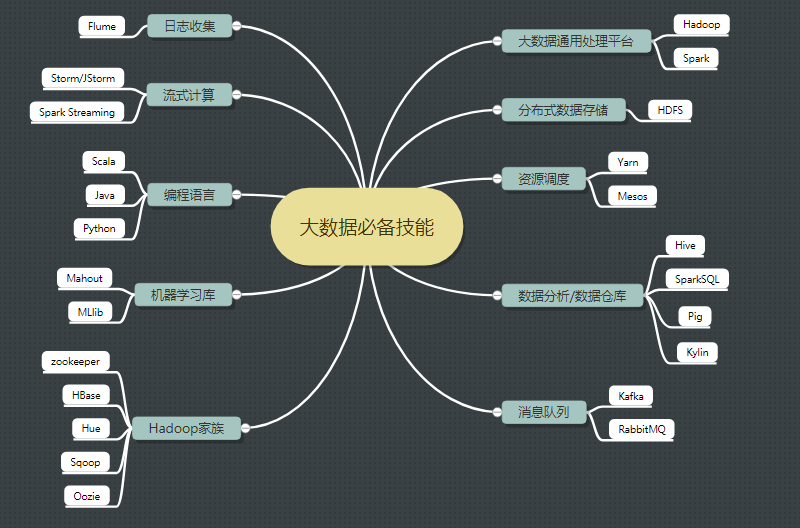
必须掌握的技能11条
- Java高级(虚拟机、并发)
- Linux 基本操作
- Hadoop(HDFS+MapReduce+Yarn )
- HBase(JavaAPI操作+Phoenix )
- Hive(Hql基本操作和原理理解)
- Kafka
- Storm/JStorm
- Scala
- Python
- Spark (Core+sparksql+Spark streaming )
- 辅助小工具(Sqoop/Flume/Oozie/Hue等)
高阶技能6条
- 机器学习算法以及mahout库加MLlib
- R语言
- Lambda 架构
- Kappa架构
- Kylin
- Alluxio
第一阶段(基础阶段)
1)Linux学习(跟鸟哥学就ok了)—–20小时
- Linux操作系统介绍与安装。
- Linux常用命令。
- Linux常用软件安装。
- Linux网络。
- 防火墙。
- Shell编程等。
官网:https://www.centos.org/download/
中文社区:http://www.linuxidc.com/Linux/2017-09/146919.htm
2)Java 高级学习(《深入理解Java虚拟机》、《Java高并发实战》)—30小时
- 掌握多线程。
- 掌握并发包下的队列。
- 了解JMS。
- 掌握JVM技术。
- 掌握反射和动态代理。
官网:https://www.java.com/zh_CN/
中文社区:http://www.java-cn.com/index.html
3)Zookeeper学习(可以参照这篇博客进行学习:http://www.cnblogs.com/wuxl360/p/5817471.html)
- Zookeeper分布式协调服务介绍。
- Zookeeper集群的安装部署。
- Zookeeper数据结构、命令。
- Zookeeper的原理以及选举机制。
官网:http://zookeeper.apache.org/
中文社区:http://www.aboutyun.com/forum-149-1.html
第二阶段(攻坚阶段)
4)Hadoop (《Hadoop 权威指南》)—80小时
-
HDFS
- HDFS的概念和特性。
- HDFS的shell操作。
- HDFS的工作机制。
- HDFS的Java应用开发。
-
MapReduce
- 运行WordCount示例程序。
- 了解MapReduce内部的运行机制。
- MapReduce程序运行流程解析。
- MapTask并发数的决定机制。
- MapReduce中的combiner组件应用。
- MapReduce中的序列化框架及应用。
- MapReduce中的排序。
- MapReduce中的自定义分区实现。
- MapReduce的shuffle机制。
- MapReduce利用数据压缩进行优化。
- MapReduce程序与YARN之间的关系。
- MapReduce参数优化。
-
MapReduce的Java应用开发
官网:http://hadoop.apache.org/
中文文档:http://hadoop.apache.org/docs/r1.0.4/cn/
中文社区:http://www.aboutyun.com/forum-143-1.html
5)Hive(《Hive开发指南》)–20小时
-
Hive 基本概念
- Hive 应用场景。
- Hive 与hadoop的关系。
- Hive 与传统数据库对比。
- Hive 的数据存储机制。
-
Hive 基本操作
- Hive 中的DDL操作。
- 在Hive 中如何实现高效的JOIN查询。
- Hive 的内置函数应用。
- Hive shell的高级使用方式。
- Hive 常用参数配置。
- Hive 自定义函数和Transform的使用技巧。
- Hive UDF/UDAF开发实例。
-
Hive 执行过程分析及优化策略
官网:https://hive.apache.org/
中文入门文档:http://www.aboutyun.com/thread-11873-1-1.html
中文社区:http://www.aboutyun.com/thread-7598-1-1.html
6)HBase(《HBase权威指南》)—20小时
- hbase简介。
- habse安装。
- hbase数据模型。
- hbase命令。
- hbase开发。
- hbase原理。
官网:http://hbase.apache.org/
中文文档:http://abloz.com/hbase/book.html
中文社区:http://www.aboutyun.com/forum-142-1.html
7)Scala(《快学Scala》)–20小时
- Scala概述。
- Scala编译器安装。
- Scala基础。
- 数组、映射、元组、集合。
- 类、对象、继承、特质。
- 模式匹配和样例类。
- 了解Scala Actor并发编程。
- 理解Akka。
- 理解Scala高阶函数。
- 理解Scala隐式转换。
官网:http://www.scala-lang.org/
初级中文教程:http://www.runoob.com/scala/scala-tutorial.html
8)Spark (《Spark 权威指南》)—60小时
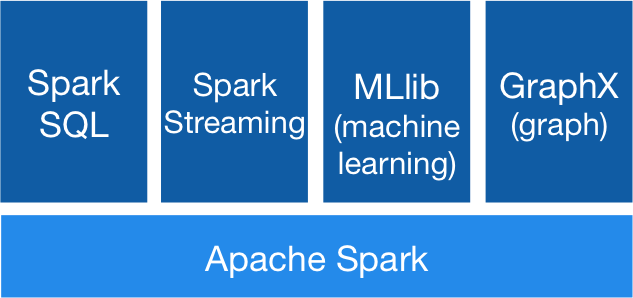
-
Spark core
- Spark概述。
- Spark集群安装。
- 执行第一个Spark案例程序(求PI)。
-
RDD
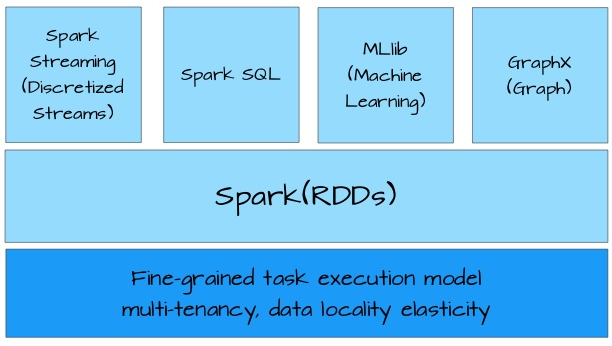
- RDD概述。
- 创建RDD。
- RDD编程API(Transformation 和 Action Operations)。
- RDD的依赖关系
- RDD的缓存
- DAG(有向无环图)
3.Spark SQL and DataFrame/DataSet

- Spark SQL概述。
- DataFrames。
- DataFrame常用操作。
- 编写Spark SQL查询程序。
Spark Streaming

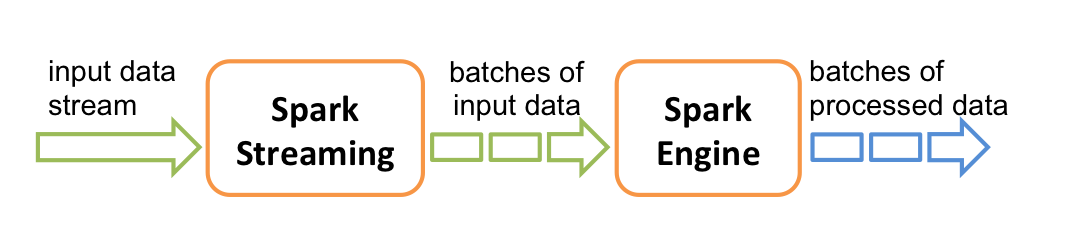
4
- park Streaming概述。
- 理解DStream。
- DStream相关操作(Transformations 和 Output Operations)。
5.。Structured Streaming
6。其他(MLlib and GraphX )
官网:http://spark.apache.org
中文文档(但是版本有点老):https://www.gitbook.com/book/aiyanbo/spark-programming-guide-zh-cn/details
中文社区:http://www.aboutyun.com/forum-146-1.html
9)Python (推荐廖雪峰的博客—30小时
10)自己用虚拟机搭建一个集群,把所有工具都装上,自己开发一个小demo —30小时
可以自己用VMware搭建4台虚拟机,然后安装以上软件,搭建一个小集群(本人亲测,I7,64位,16G内存,完全可以运行起来,以下附上我学习时用虚拟机搭建集群的操作文档)
学习之旅2:https://www.cnblogs.com/javadongx/p/hadoop_storm_spark_hdfs_hive.html