一、缓存
1、缓存使用
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落 盘工作。 哪些数据适合放入缓存? (1)即时性、数据一致性要求不高的 (2)访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
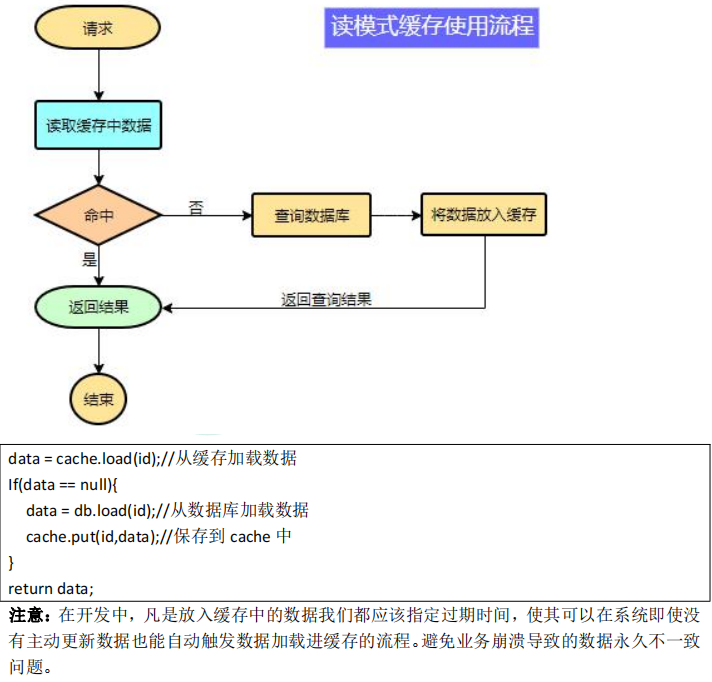
本地缓存与分布式缓存
本地缓存:和微服务同一个进程。缺点:分布式时本地缓存不能共享
分布式缓存:缓存中间件,例如:redis
2、整合 redis 作为缓存
(1)安装 redis
参考:谷粒商城分布式基础(二)—— 环境搭建(基础篇)(虚拟机 & JDK & Maven & docker & mysql & redis & vue) 中的 “6、docker安装redis”
(2)gulimall-product 引入 redis-starter
<!--引入redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
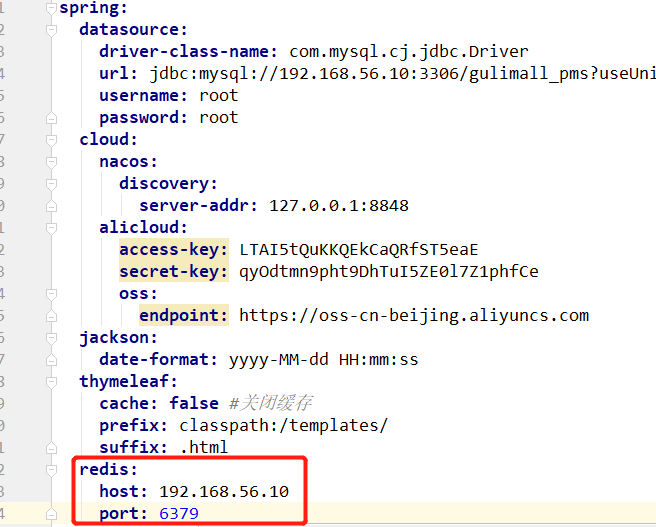
(3)application.yml 配置 redis
(4)使用 RedisTemplate 操作 redis
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testStringRedisTemplate(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
//保存
ops.set("hello","word"+ UUID.randomUUID().toString());
//查询
String hello = ops.get("hello");
System.out.println("之前保存的数据是:"+hello);
}
测试结果:

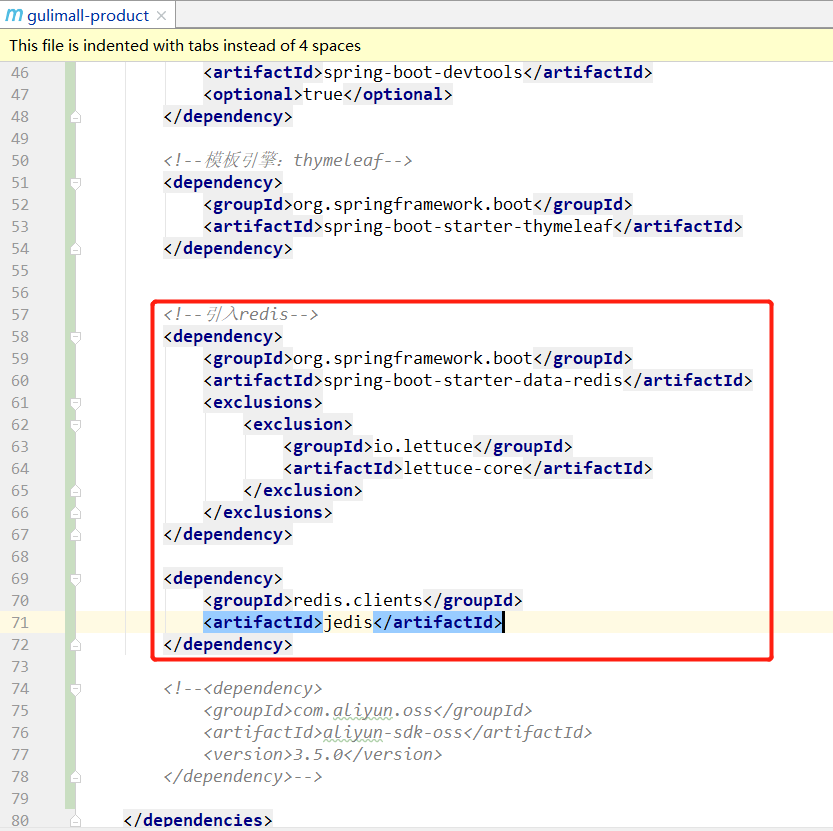
(5)切换使用 jedis 解决内存泄漏
目的:解决堆外内存溢出

修改 pom.xml,切换使用jedis
<!--引入redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
3、改造三级分类业务
修改 com.atguigu.gulimall.product.service.impl.CategoryServiceImpl 的 getCatalogJson 方法
@Autowired
StringRedisTemplate redisTemplate;
//TODO 产生堆外内存溢出:OutOfDirectMemoryError
//(1)springboot2.0以后默认使用lettuce作为操作redis客户端。它使用netty进行网络通信
//(2)lettuce的bug导致netty堆外内存溢出 -Xmx300m;netty如果没有指定堆外内存,默认使用-Xmx300m
// 可以通过-Dio.netty.maxDirectMemory进行设置
// 解决方案:不能使用-Dio.netty.maxDirectMemory只去调大堆外内存。
//(1)升级lettuce客户端
//(2)切换使用jedis
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//给缓存中放json字符串,拿出的json字符串,还要逆转为能用的对象类型:【序列化与反序列化】
//1、加入缓存逻辑,缓存中存的数据是json字符串
//JSO跨语言、跨平台兼容
String catalogJson = redisTemplate.opsForValue().get("catalogJson");
if(StringUtils.isEmpty(catalogJson)){
//2、缓存中没有,查询数据库
Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDb();
//3、查到的数据再放入缓存,将对象转为json放到缓存中
String s = JSON.toJSONString(catalogJsonFromDb);
redisTemplate.opsForValue().set("catalogJson", s);
return catalogJsonFromDb;
}
//转为我们指定的对象
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>(){});
return result;
}
/**
* 从数据库查询并封装分类数据
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDb() {
/**
* 1、将数据库的多次查询变为一次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
//1、查询所有一级分类
List<CategoryEntity> level1Catagorys = getParent_cid(selectList, 0L);
//2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Catagorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 1、每一个的一级分类,查到这个以及分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
//2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catalog = getParent_cid(selectList, l2.getCatId());
if(level3Catalog!=null){
List<Catelog2Vo.Category3Vo> collect = level3Catalog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Category3Vo category3Vo = new Catelog2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
private List<CategoryEntity> getParent_cid( List<CategoryEntity> selectList, Long parent_cid) {
List<CategoryEntity> collect = selectList.stream().filter(item -> item.getParentCid() == parent_cid).collect(Collectors.toList());
return collect;
}
lettuce和jedis是操作redis的底层客户端,RedisTemplate是再次封装
二、缓存失效问题
先来解决大并发读情况下的缓存失效问题;
1、缓存穿透
(1)含义
指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,
这将导致这个不 存在的数据每次请求都要到存储层去查询,失去了缓存的意义
(2)风险
利用不存在的数据进行攻击,数据库瞬时压力增大,最终导致崩溃
(2)解决方案
null结果缓存,并加入短暂过期时间
2、缓存雪崩
(1)含义
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间, 导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时 压力过重雪崩。
(2)解决方案:
原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这 样每一个缓存的过期时间的重复率就会降低,就很难引发集体 失效的事件。
出现雪崩:降级 熔断
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
事后:利用 redis 持久化机制保存的数据尽快恢复缓存
3、缓存击穿
(1)含义
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
如果这个key在大量请求同时进来前正好失效,那么所有对 这个key的数据查询都落到db,我们称为缓存击穿。
(2)解决方案
加锁
大量并发只让一个去查,其他人等待,查到以后释放锁,其他 人获取到锁,先查缓存,就会有数据,不用去db
4、加锁解决缓存击穿问题

(1) 修改 com.atguigu.gulimall.product.service.impl.CategoryServiceImpl 的 getCatalogJson 方法
//TODO 产生堆外内存溢出:OutOfDirectMemoryError
//(1)springboot2.0以后默认使用lettuce作为操作redis客户端。它使用netty进行网络通信
//(2)lettuce的bug导致netty堆外内存溢出 -Xmx300m;netty如果没有指定堆外内存,默认使用-Xmx300m
// 可以通过-Dio.netty.maxDirectMemory进行设置
// 解决方案:不能使用-Dio.netty.maxDirectMemory只去调大堆外内存。
//(1)升级lettuce客户端
//(2)切换使用jedis
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//给缓存中放json字符串,拿出的json字符串,还要逆转为能用的对象类型:【序列化与反序列化】
/**
* 1、空结果缓存:解决缓存穿透
* 2、设置过期时间(加随机值):解决缓存雪崩
* 3、枷锁:解决缓存击穿
*/
//1、加入缓存逻辑,缓存中存的数据是json字符串
//JSO跨语言、跨平台兼容
String catalogJson = redisTemplate.opsForValue().get("catalogJson");
if(StringUtils.isEmpty(catalogJson)){
//2、缓存中没有,查询数据库
Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDb();
System.out.println("缓存不命中....将要查询数据库....");
return catalogJsonFromDb;
}
System.out.println("缓存命中....直接返回.....");
//转为我们指定的对象
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>(){});
return result;
}
/**
* 从数据库查询并封装分类数据
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDb() {
//只要是同一把锁,就能锁住,需要这个锁的所有线程
//1、synchronized (this):SprinBoot所有的组件在容器中都是单例的
//TODO 本地锁:synchronized,JUC(lock),在分布式情况下,想要锁住所有,必须使用分布式锁
synchronized (this){
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJson = redisTemplate.opsForValue().get("catalogJson");
if(!StringUtils.isEmpty(catalogJson)){
//缓存不为null直接返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>(){});
return result;
}
System.out.println("查询了数据库.....");
/**
* 1、将数据库的多次查询变为一次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
//1、查询所有一级分类
List<CategoryEntity> level1Catagorys = getParent_cid(selectList, 0L);
//2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Catagorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 1、每一个的一级分类,查到这个以及分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
//2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catalog = getParent_cid(selectList, l2.getCatId());
if(level3Catalog!=null){
List<Catelog2Vo.Category3Vo> collect = level3Catalog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Category3Vo category3Vo = new Catelog2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
//3、查到的数据再放入缓存,将对象转为json放到缓存中
String s = JSON.toJSONString(parent_cid);
redisTemplate.opsForValue().set("catalogJson", s, 1, TimeUnit.DAYS);
return parent_cid;
}
}
private List<CategoryEntity> getParent_cid( List<CategoryEntity> selectList, Long parent_cid) {
List<CategoryEntity> collect = selectList.stream().filter(item -> item.getParentCid() == parent_cid).collect(Collectors.toList());
return collect;
}
锁时序问题:之前的逻辑是查缓存没有,然后取竞争锁查数据库,这样就造成多 次查数据库。
解决方法:竞争到锁后,再次确认缓存中没有,再去查数据库。
(2)jemeter 测试 100的并发 查看是否锁住,是否只查询了一次数据库
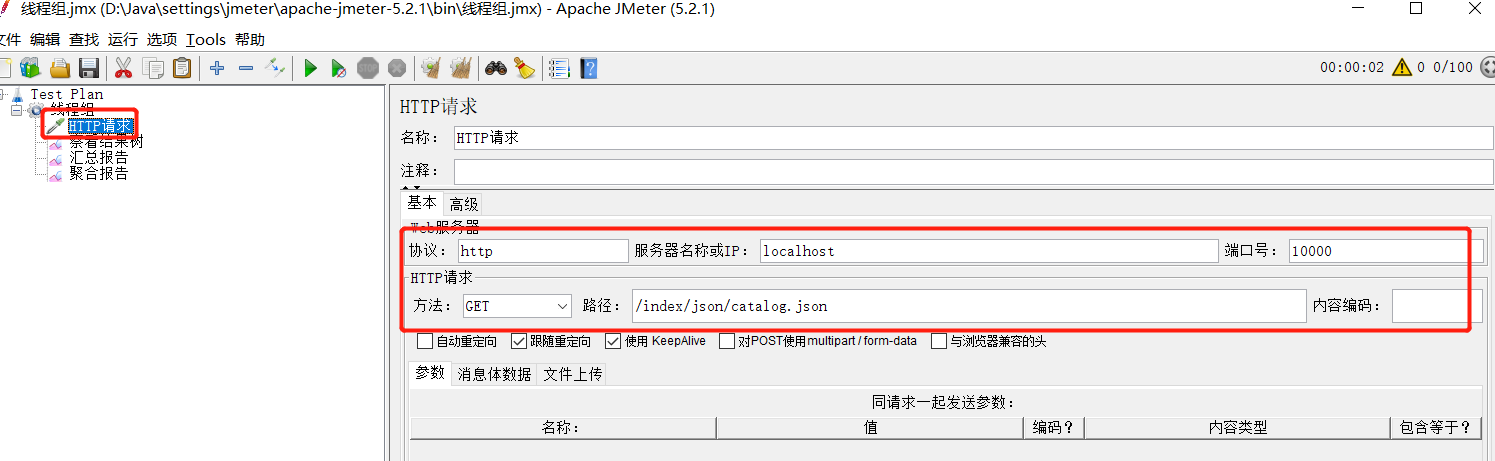
测试结果:
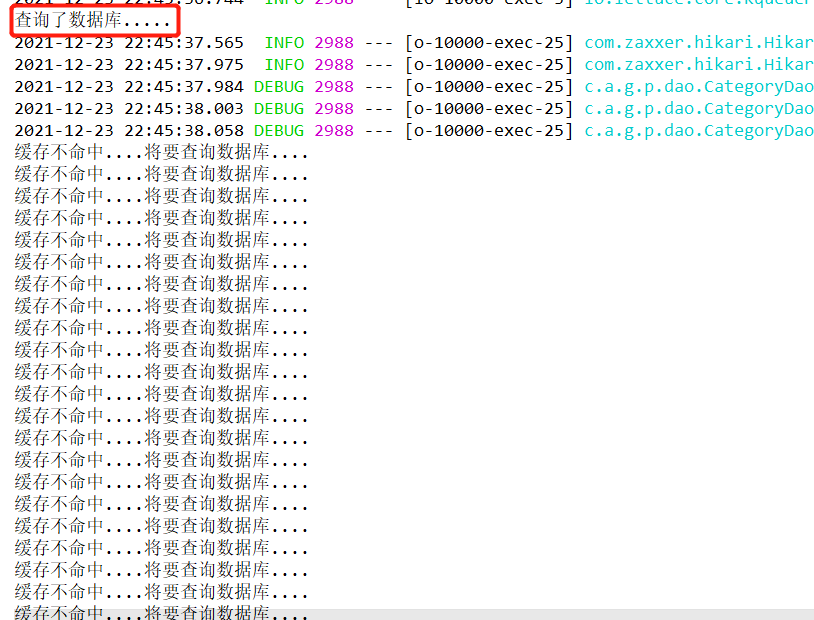
确认只查了一次,确实锁住了
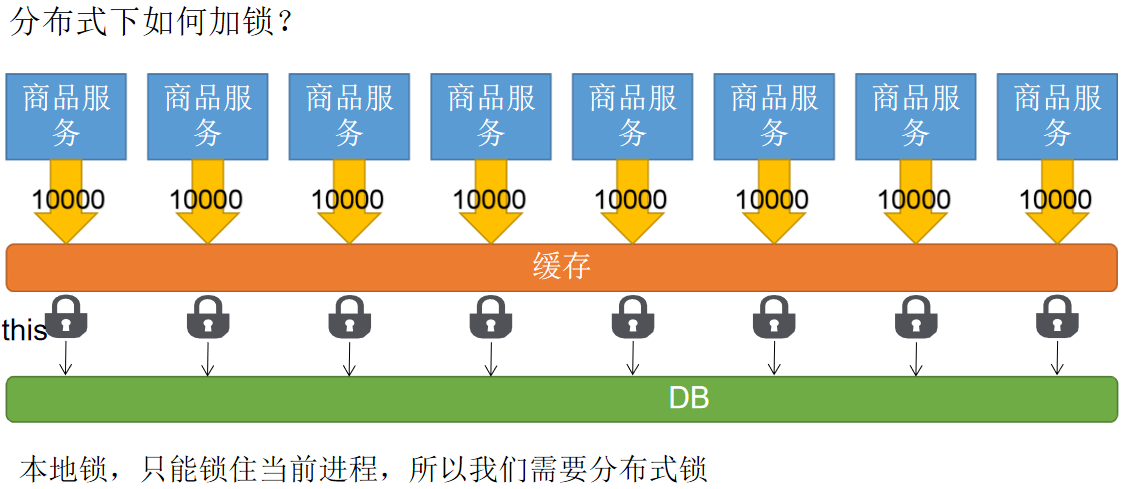
5、本地锁在分布式下的问题
(1)模拟多个商品服务,分别copy三个商品服务,端口号依次设置为10001、10002、10003
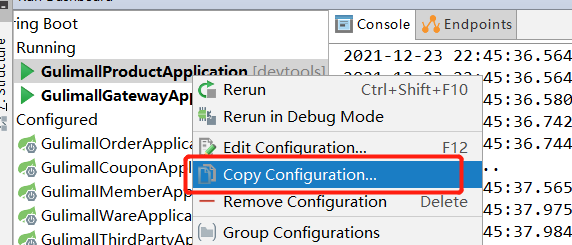
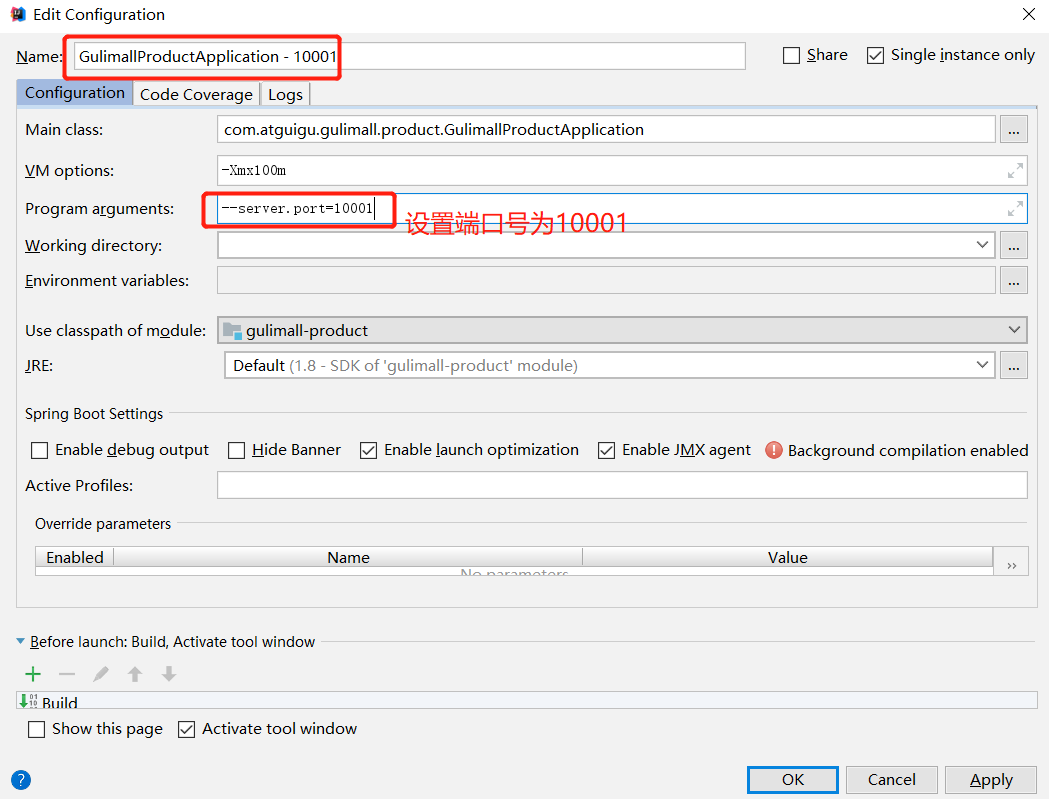

分别启动这四个服务
(2)修改jemeter

(3)清除之前测试的缓存数据,启动测试,查看结果
结果发现,每一个服务的控制台都显示查询了一次数据库,也就是说只能锁住本地服务,不能解决分布式下的所问题