一、分析原因:查看服务器的远程端口绑定ip

这边显示绑定的是127.0.0.1:7077表示只能本地访问
正确的访问方式为:局域网Ip:7077
二、查看启动脚本设置:
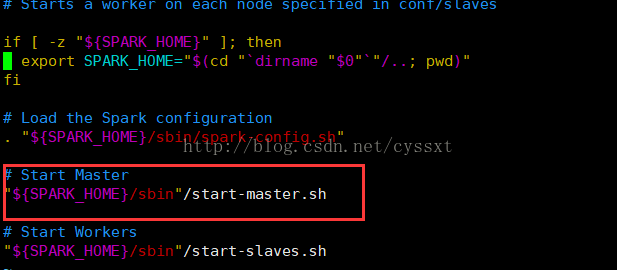
分析脚本可以看到这边启动master和slaves分别是两个脚本,由于我们是通过start-master.sh去运行的,我们查看start-master.sh
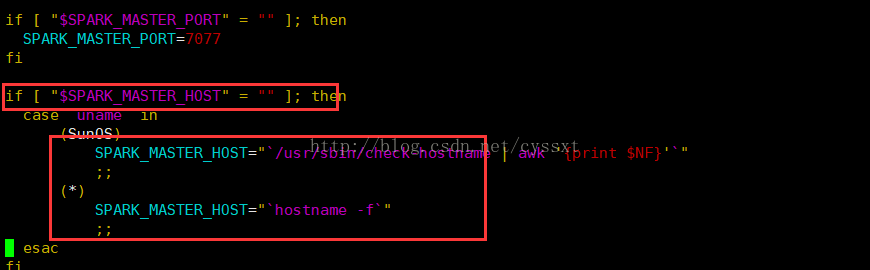
通过start-master可以发现,这边启动的ip是根据SPARK_MASTER_HOST的环境变量获取,如果不存在,则通过hostname -f去获取
我们键入hostname -f

我们在查看/etc/hosts文件配置:
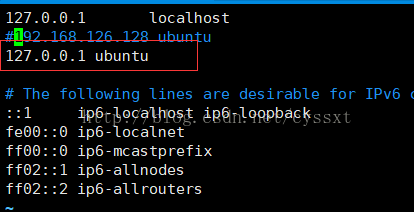
发现ubuntu映射127.0.0.1 我们改为
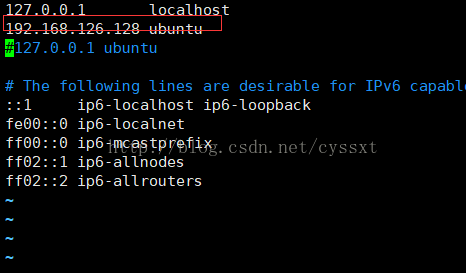
重启spark
查看结果

发现ip已经是正式ip而不是回环ip
在本地的eclipse或者intellij idea上就能正确调试附上调试代码
package main.scala
import org.apache.spark.{SparkConf, SparkContext}
object SimpleApp {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir","D:\\xxx\\hadoop-2.8.0")
val logFile = "README.md" // Should be some file on your system
// spark://ubuntu:7077
val conf = new SparkConf().setAppName("Simple Application").setMaster("spark://192.168.126.128:7077")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
————————————————
版权声明:本文为CSDN博主「徐涛_java_web前端」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cyssxt/article/details/73477754