hadoop2.2.0、centos6.5
hadoop任务的提交常用的两种,一种是测试常用的IDE远程提交,另一种就是生产上用的客户端命令行提交
通用的任务程序提交步骤为:
1.将程序打成jar包;
2.将jar包上传到HDFS上;
3.用命令行提交HDFS上的任务程序。
跟着提交步骤从命令行提交开始
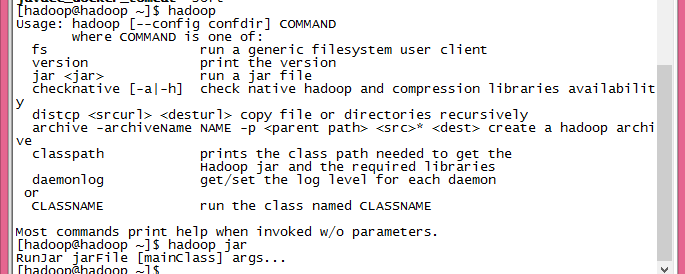
最简单的提交命令应该如:
hadoop jar /home/hadoop/hadoop-2.2.0/hadoop-examples.jar wordcount inputPath outputPath
在名为hadoop的shell 命令文件中当参数为jar时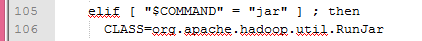
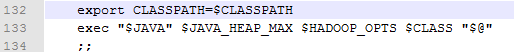
确定了要运行的CLASS文件和环境变量后最后执行了了exec命令来运行
看org.apache.hadoop.util.RunJar类的main方法

1 public static void main(String[] args) throws Throwable {
2 String usage = "RunJar jarFile [mainClass] args...";
3 //验证提交的参数数量
4 if (args.length < 1) {
5 System.err.println(usage);
6 System.exit(-1);
7 }
8 //验证jar文件是否存在
9 int firstArg = 0;
10 String fileName = args[firstArg++];
11 File file = new File(fileName);
12 if (!file.exists() || !file.isFile()) {
13 System.err.println("Not a valid JAR: " + file.getCanonicalPath());
14 System.exit(-1);
15 }
16 String mainClassName = null;
17
18 JarFile jarFile;
19 try {
20 jarFile = new JarFile(fileName);
21 } catch(IOException io) {
22 throw new IOException("Error opening job jar: " + fileName)
23 .initCause(io);
24 }
25 //验证是否存在main方法
26 Manifest manifest = jarFile.getManifest();
27 if (manifest != null) {
28 mainClassName = manifest.getMainAttributes().getValue("Main-Class");
29 }
30 jarFile.close();
31
32 if (mainClassName == null) {
33 if (args.length < 2) {
34 System.err.println(usage);
35 System.exit(-1);
36 }
37 mainClassName = args[firstArg++];
38 }
39 mainClassName = mainClassName.replaceAll("/", ".");
40 //设置临时目录并验证
41 File tmpDir = new File(new Configuration().get("hadoop.tmp.dir"));
42 ensureDirectory(tmpDir);
43
44 final File workDir;
45 try {
46 workDir = File.createTempFile("hadoop-unjar", "", tmpDir);
47 } catch (IOException ioe) {
48 // If user has insufficient perms to write to tmpDir, default
49 // "Permission denied" message doesn't specify a filename.
50 System.err.println("Error creating temp dir in hadoop.tmp.dir "
51 + tmpDir + " due to " + ioe.getMessage());
52 System.exit(-1);
53 return;
54 }
55
56 if (!workDir.delete()) {
57 System.err.println("Delete failed for " + workDir);
58 System.exit(-1);
59 }
60 ensureDirectory(workDir);
61 //增加删除工作目录的钩子,任务执行完后要删除
62 ShutdownHookManager.get().addShutdownHook(
63 new Runnable() {
64 @Override
65 public void run() {
66 FileUtil.fullyDelete(workDir);
67 }
68 }, SHUTDOWN_HOOK_PRIORITY);
69
70
71 unJar(file, workDir);
72
73 ArrayList<URL> classPath = new ArrayList<URL>();
74 classPath.add(new File(workDir+"/").toURI().toURL());
75 classPath.add(file.toURI().toURL());
76 classPath.add(new File(workDir, "classes/").toURI().toURL());
77 File[] libs = new File(workDir, "lib").listFiles();
78 if (libs != null) {
79 for (int i = 0; i < libs.length; i++) {
80 classPath.add(libs[i].toURI().toURL());
81 }
82 }
83 //通过反射的方式执行任务程序的main方法,并把剩余的参数作为任务程序main方法的参数
84 ClassLoader loader =
85 new URLClassLoader(classPath.toArray(new URL[0]));
86
87 Thread.currentThread().setContextClassLoader(loader);
88 Class<?> mainClass = Class.forName(mainClassName, true, loader);
89 Method main = mainClass.getMethod("main", new Class[] {
90 Array.newInstance(String.class, 0).getClass()
91 });
92 String[] newArgs = Arrays.asList(args)
93 .subList(firstArg, args.length).toArray(new String[0]);
94 try {
95 main.invoke(null, new Object[] { newArgs });
96 } catch (InvocationTargetException e) {
97 throw e.getTargetException();
98 }
99 }
环境设置好后就要开始执行任务程序的main方法了
以WordCount为例:
1 package org.apache.hadoop.examples;
2
3 import java.io.IOException;
4 import java.util.StringTokenizer;
5
6 import org.apache.hadoop.conf.Configuration;
7 import org.apache.hadoop.fs.Path;
8 import org.apache.hadoop.io.IntWritable;
9 import org.apache.hadoop.io.Text;
10 import org.apache.hadoop.mapreduce.Job;
11 import org.apache.hadoop.mapreduce.Mapper;
12 import org.apache.hadoop.mapreduce.Reducer;
13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
15 import org.apache.hadoop.util.GenericOptionsParser;
16
17 public class WordCount {
18
19 public static class TokenizerMapper
20 extends Mapper<Object, Text, Text, IntWritable>{
21
22 private final static IntWritable one = new IntWritable(1);
23 private Text word = new Text();
24
25 public void map(Object key, Text value, Context context
26 ) throws IOException, InterruptedException {
27 StringTokenizer itr = new StringTokenizer(value.toString());
28 while (itr.hasMoreTokens()) {
29 word.set(itr.nextToken());
30 context.write(word, one);
31 }
32 }
33 }
34
35 public static class IntSumReducer
36 extends Reducer<Text,IntWritable,Text,IntWritable> {
37 private IntWritable result = new IntWritable();
38
39 public void reduce(Text key, Iterable<IntWritable> values,
40 Context context
41 ) throws IOException, InterruptedException {
42 int sum = 0;
43 for (IntWritable val : values) {
44 sum += val.get();
45 }
46 result.set(sum);
47 context.write(key, result);
48 }
49 }
50
51 public static void main(String[] args) throws Exception {
52 Configuration conf = new Configuration();
53 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
54 if (otherArgs.length != 2) {
55 System.err.println("Usage: wordcount <in> <out>");
56 System.exit(2);
57 }
58 Job job = new Job(conf, "word count");
59 job.setJarByClass(WordCount.class);
60 job.setMapperClass(TokenizerMapper.class);
61 job.setCombinerClass(IntSumReducer.class);
62 job.setReducerClass(IntSumReducer.class);
63 job.setOutputKeyClass(Text.class);
64 job.setOutputValueClass(IntWritable.class);
65 FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
66 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
67 System.exit(job.waitForCompletion(true) ? 0 : 1);
68 }
69 }
在程序运行入口main方法中
首先定义配置文件类 Configuration,此类是Hadoop各个模块的公共使用类,用于加载类路径下的各种配置文件,读写其中的配置选项;
第二步中用到了 GenericOptionsParser 类,其目的是将命令行中的后部分参数自动设置到变量conf中,
如果代码提交的时候传入其他参数,比如指定reduce的个数,可以根据 GenericOptionsParser的命令行格式这么写:
bin/hadoop jar MyJob.jar com.xxx.MyJobDriver -Dmapred.reduce.tasks=5,
其规则是 -D 加上MR的配置选项(默认reduce task的个数为1,map的个数也为1);
之后就是 Job 的定义
使用的job类的构造方法为
public Job(Configuration conf, String jobName) throws IOException {
this(conf);
setJobName(jobName);
}
调用了另外一个构造方法,并设置了Job的名字(即WordCount)
public Job(Configuration conf) throws IOException {
this(new JobConf(conf));
}
public JobConf(Configuration conf) {
super(conf);
if (conf instanceof JobConf) {
JobConf that = (JobConf)conf;
credentials = that.credentials;
}
checkAndWarnDeprecation();
}
job 已经根据 配置信息实例化好运行环境了,下面就是加入实体“口食”
依次给job添加Jar包、设置Mapper类、设置合并类、设置Reducer类、设置输出键类型、设置输出值类型
在setJarByClass中
public void setJarByClass(Class<?> cls) {
ensureState(JobState.DEFINE);
conf.setJarByClass(cls);
}
它先判断当前job的状态是否在运行中,接着通过class找到jar文件,将jar路径赋值给mapreduce.jar.jar属性(寻找jar文件的方法使通过ClassUtil类中的findContainingJar方法)
job的提交方法是
job.waitForCompletion(true)
1 public boolean waitForCompletion(boolean verbose
2 ) throws IOException, InterruptedException,
3 ClassNotFoundException {
4 if (state == JobState.DEFINE) {
5 submit();
6 }
7 if (verbose) {
8 monitorAndPrintJob();
9 } else {
10 // get the completion poll interval from the client.
11 int completionPollIntervalMillis =
12 Job.getCompletionPollInterval(cluster.getConf());
13 while (!isComplete()) {
14 try {
15 Thread.sleep(completionPollIntervalMillis);
16 } catch (InterruptedException ie) {
17 }
18 }
19 }
20 return isSuccessful();
21 }
参数 verbose ,如果想在控制台打印当前的任务执行进度,则设为true
1 public void submit()
2 throws IOException, InterruptedException, ClassNotFoundException {
3 ensureState(JobState.DEFINE);
4 setUseNewAPI();
5 connect();
6 final JobSubmitter submitter =
7 getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
8 status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
9 public JobStatus run() throws IOException, InterruptedException,
10 ClassNotFoundException {
11 return submitter.submitJobInternal(Job.this, cluster);
12 }
13 });
14 state = JobState.RUNNING;
15 LOG.info("The url to track the job: " + getTrackingURL());
16 }
在submit 方法中会把Job提交给对应的Cluster,然后不等待Job执行结束就立刻返回
同时会把Job实例的状态设置为JobState.RUNNING,从而来表示Job正在进行中
然后在Job运行过程中,可以调用getJobState()来获取Job的运行状态
Submit主要进行如下操作
- 检查Job的输入输出是各项参数,获取配置信息和远程主机的地址,生成JobID,确定所需工作目录(也是MRAppMaster.java所在目录),执行期间设置必要的信息
- 拷贝所需要的Jar文件和配置文件信息到HDFS系统上的指定工作目录,以便各个节点调用使用
- 计算并获数去输入分片(Input Split)的数目,以确定map的个数
- 调用YARNRunner类下的submitJob()函数,提交Job,传出相应的所需参数(例如 JobID等)。
- 等待submit()执行返回Job执行状态,最后删除相应的工作目录。
在提交前先链接集群(cluster),通过connect方法
1 private synchronized void connect()
2 throws IOException, InterruptedException, ClassNotFoundException {
3 if (cluster == null) {
4 cluster =
5 ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
6 public Cluster run()
7 throws IOException, InterruptedException,
8 ClassNotFoundException {
9 return new Cluster(getConfiguration());
10 }
11 });
12 }
13 }
这是一个线程保护方法。这个方法中根据配置信息初始化了一个Cluster对象,即代表集群
1 public Cluster(Configuration conf) throws IOException {
2 this(null, conf);
3 }
4
5 public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
6 throws IOException {
7 this.conf = conf;
8 this.ugi = UserGroupInformation.getCurrentUser();
9 initialize(jobTrackAddr, conf);
10 }
11
12 private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
13 throws IOException {
14
15 synchronized (frameworkLoader) {
16 for (ClientProtocolProvider provider : frameworkLoader) {
17 LOG.debug("Trying ClientProtocolProvider : "
18 + provider.getClass().getName());
19 ClientProtocol clientProtocol = null;
20 try {
21 if (jobTrackAddr == null) {
//创建YARNRunner对象
22 clientProtocol = provider.create(conf);
23 } else {
24 clientProtocol = provider.create(jobTrackAddr, conf);
25 }
26 //初始化Cluster内部成员变量
27 if (clientProtocol != null) {
28 clientProtocolProvider = provider;
29 client = clientProtocol;
30 LOG.debug("Picked " + provider.getClass().getName()
31 + " as the ClientProtocolProvider");
32 break;
33 }
34 else {
35 LOG.debug("Cannot pick " + provider.getClass().getName()
36 + " as the ClientProtocolProvider - returned null protocol");
37 }
38 }
39 catch (Exception e) {
40 LOG.info("Failed to use " + provider.getClass().getName()
41 + " due to error: " + e.getMessage());
42 }
43 }
44 }
45
46 if (null == clientProtocolProvider || null == client) {
47 throw new IOException(
48 "Cannot initialize Cluster. Please check your configuration for "
49 + MRConfig.FRAMEWORK_NAME
50 + " and the correspond server addresses.");
51 }
52 }
可以看出创建客户端代理阶段使用了java.util.ServiceLoader,在2.3.0版本中包含LocalClientProtocolProvider(本地作业)和YarnClientProtocolProvider(yarn作业)(hadoop有一个Yarn参数mapreduce.framework.name用来控制你选择的应用框架。在MRv2里,mapreduce.framework.name有两个值:local和yarn),此处会根据mapreduce.framework.name的配置创建相应的客户端

(ServiceLoader是服务加载类,它根据文件配置来在java classpath环境中加载对应接口的实现类)
这里在实际生产中一般都是yarn,所以会创建一个YARNRunner对象(客户端代理类)类进行任务的提交
实例化Cluster后开始真正的任务提交
submitter.submitJobInternal(Job.this, cluster)
1 JobStatus submitJobInternal(Job job, Cluster cluster)
2 throws ClassNotFoundException, InterruptedException, IOException {
3
4
5 //检测输出目录合法性,是否已存在,或未设置
6 checkSpecs(job);
7
8
9 Configuration conf = job.getConfiguration();
10 addMRFrameworkToDistributedCache(conf);
11 //获得登录区,用以存放作业执行过程中用到的文件,默认位置/tmp/hadoop-yarn/staging/root/.staging ,可通过yarn.app.mapreduce.am.staging-dir修改
12 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
13 //主机名和地址设置
14 InetAddress ip = InetAddress.getLocalHost();
15 if (ip != null) {
16 submitHostAddress = ip.getHostAddress();
17 submitHostName = ip.getHostName();
18 conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
19 conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
20 }
21 //获取新的JobID,此处需要RPC调用
22 JobID jobId = submitClient.getNewJobID();
23 job.setJobID(jobId);
24 //获取提交目录:/tmp/hadoop-yarn/staging/root/.staging/job_1395778831382_0002
25 Path submitJobDir = new Path(jobStagingArea, jobId.toString());
26 JobStatus status = null;
27 try {
28 conf.set(MRJobConfig.USER_NAME,
29 UserGroupInformation.getCurrentUser().getShortUserName());
30 conf.set("hadoop.http.filter.initializers",
31 "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
32 conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
33 LOG.debug("Configuring job " + jobId + " with " + submitJobDir
34 + " as the submit dir");
35 // get delegation token for the dir
36 TokenCache.obtainTokensForNamenodes(job.getCredentials(),
37 new Path[] { submitJobDir }, conf);
38
39 populateTokenCache(conf, job.getCredentials());
40
41
42 // generate a secret to authenticate shuffle transfers
43 if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
44 KeyGenerator keyGen;
45 try {
46 keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
47 keyGen.init(SHUFFLE_KEY_LENGTH);
48 } catch (NoSuchAlgorithmException e) {
49 throw new IOException("Error generating shuffle secret key", e);
50 }
51 SecretKey shuffleKey = keyGen.generateKey();
52 TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
53 job.getCredentials());
54 }
55 //向集群中拷贝所需文件,下面会单独分析(1)
56 copyAndConfigureFiles(job, submitJobDir);
57 Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
58
59 // 写分片文件job.split job.splitmetainfo,具体写入过程与MR1相同,可参考以前文章
60 LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
61 int maps = writeSplits(job, submitJobDir);
62 conf.setInt(MRJobConfig.NUM_MAPS, maps);
63 LOG.info("number of splits:" + maps);
64
65
66 // write "queue admins of the queue to which job is being submitted"
67 // to job file.
68 //设置队列名
69 String queue = conf.get(MRJobConfig.QUEUE_NAME,
70 JobConf.DEFAULT_QUEUE_NAME);
71 AccessControlList acl = submitClient.getQueueAdmins(queue);
72 conf.set(toFullPropertyName(queue,
73 QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
74
75
76 // removing jobtoken referrals before copying the jobconf to HDFS
77 // as the tasks don't need this setting, actually they may break
78 // because of it if present as the referral will point to a
79 // different job.
80 TokenCache.cleanUpTokenReferral(conf);
81
82
83 if (conf.getBoolean(
84 MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
85 MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
86 // Add HDFS tracking ids
87 ArrayList<String> trackingIds = new ArrayList<String>();
88 for (Token<? extends TokenIdentifier> t :
89 job.getCredentials().getAllTokens()) {
90 trackingIds.add(t.decodeIdentifier().getTrackingId());
91 }
92 conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
93 trackingIds.toArray(new String[trackingIds.size()]));
94 }
95
96
97 // Write job file to submit dir
98 //写入job.xml
99 writeConf(conf, submitJobFile);
100
101 //
102 // Now, actually submit the job (using the submit name)
103 //这里才开始真正提交,见下面分析(2)
104 printTokens(jobId, job.getCredentials());
105 status = submitClient.submitJob(
106 jobId, submitJobDir.toString(), job.getCredentials());
107 if (status != null) {
108 return status;
109 } else {
110 throw new IOException("Could not launch job");
111 }
112 } finally {
113 if (status == null) {
114 LOG.info("Cleaning up the staging area " + submitJobDir);
115 if (jtFs != null && submitJobDir != null)
116 jtFs.delete(submitJobDir, true);
117
118
119 }
120 }
121 }
洋洋洒洒一百余行
(这个可谓任务提交的核心部分,前面的都是铺垫)
关于split的分片:http://www.cnblogs.com/admln/p/hadoop-mapper-numbers-question.html
status = submitClient.submitJob( jobId, submitJobDir.toString(), job.getCredentials());
这里就涉及到YarnClient和RresourceManager的RPC通信了。包括获取applicationId、进行状态检查、网络通信等
这里的submitClient其实就是 YARNRunner的实体类了;
monitorAndPrintJob();
这只是粗略的job提交,详细的还有从在yarn上的RPC通信、在datanode上从文件的输入到map的执行、经过shuffle过程、reduce的执行最后结果的写文件
MR任务的提交大多是任务环境的初始化过程,任务的执行则大多涉及到任务的调度
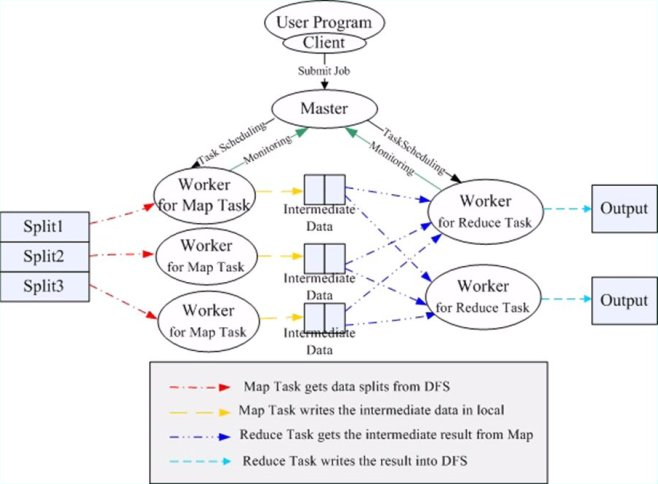
转自:https://www.cnblogs.com/admln/p/hadoop2-work-excute-submit.html