简介:这里对之前的hdfs、yarn、MR相关概念做一个总结,方便快速阅读理解。
一、HDFS
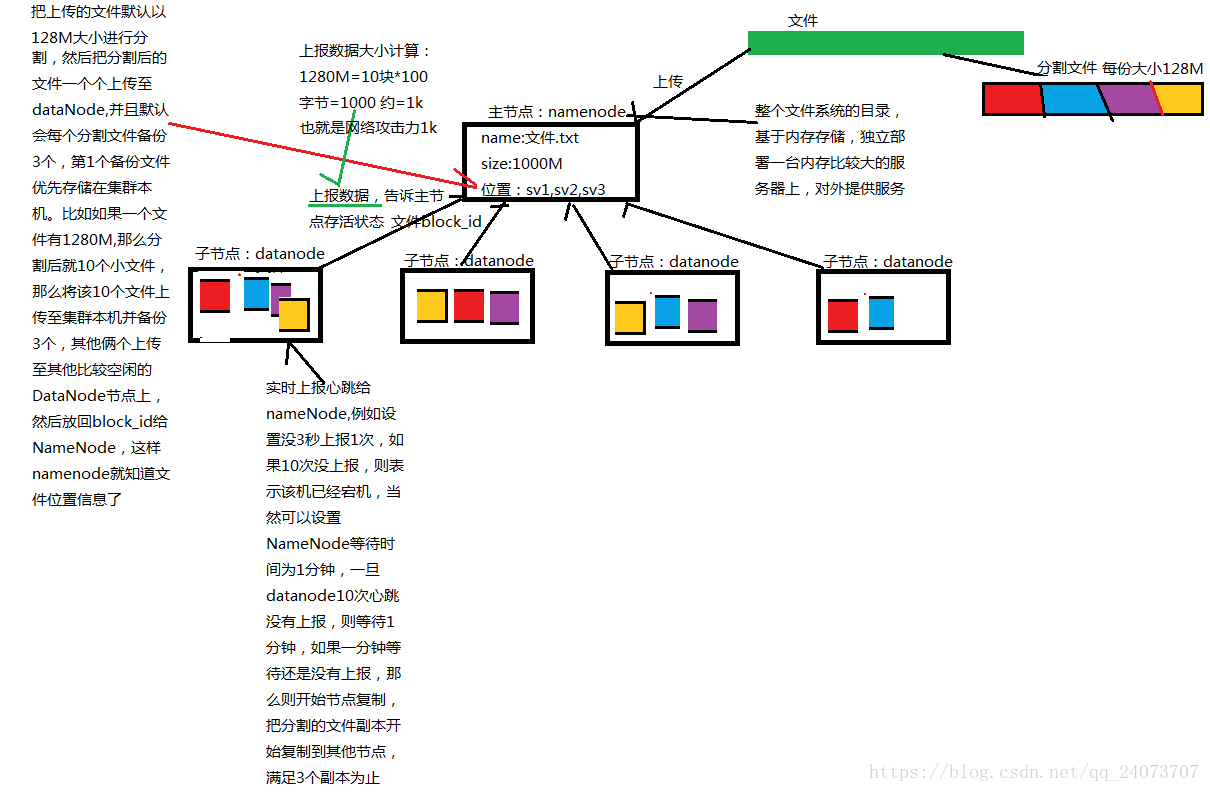
HDFS是分布式文件系统,有高容错性的特点,可以部署在价格低廉的服务器上,主要包含namenode和datanode。
Namenode是hdfs中文件目录和文件分配管理者,它保存着文件名和数据块的映射管理,数据块和datanode列表的映射关系。其中文件名和数据块的关系保存在磁盘上,但是namenode上不保存数据块和datanode列表的关系,该列表是通过datanode上报建立起来的。
Namenode上的有三种交互,1、client访问namenode获取的相关datanode的信息。2、datanode心跳汇报当前block的情况。3、secondarynamenode做checkpoint交互。
DataNode它负责实际的数据存储,并将数据息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为128MB。当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode;同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认是3,该参数可配置)不同的DataNode上。这种文件切割后存储的过程是对用户透明的。
CheckPoint的时间点
fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
流程解析
1、每隔两个小时,或者edits文件超过最大值时,SecondaryNameNode通知NameNode切换edits,
此时在NameNode中生成一个名为edits.new的新edits,在fsimage被替换之前,所有的操作都会写到edits.new中。
2、SecondaryNameNode通过Http协议复制edits和fsimage到SecondaryNameNode中
3、SecondaryNameNode将fsimage导入内存,用edits中的操作,生成新的fsimage.ckpt文件
4、SecondaryNameNode将新的fsimage复制,并通过http Post传给NameNode
5、NameNode将接收到的新的fsimage.ckpt替换掉之前的fsimage,同时将新的edits.new重命名为edits,将之前的替换掉
SecondaryNameNode,用来辅助namenode进行元数据的合并,并且传回到namenode。
二、YARN
YARN主要包括几种角色
ResourceManager(RM):主要接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM),一个集群只有一个。
NodeManager:主要是节点上的资源管理,启动Container运行task计算,上报资源、container情况给RM和任务处理情况给AM,整个集群有多个。
ApplicationMaster:主要是单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launch Container指令,接收NM的task处理状态信息。每个应用有一个。
Container:是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。

三、MapReduce
MapReduce是hadoop的一种离线计算框架,适合离线批处理,具有很好的容错性和扩展性,适合简单的批处理任务。缺点启动开销大,任务多使用磁盘效率比较低。
一个MapReduce 作业通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序,然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。通常,MapReduce框架和分布式文件系统是运行在一组相同的节点上的,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
一个MapReduce任务包含一般会这几个部分:Map、Shuffle(Sort、Partitioner、 Combiner、Merge、Sort)、Reduce。
Mapreduce工作原理如下图:
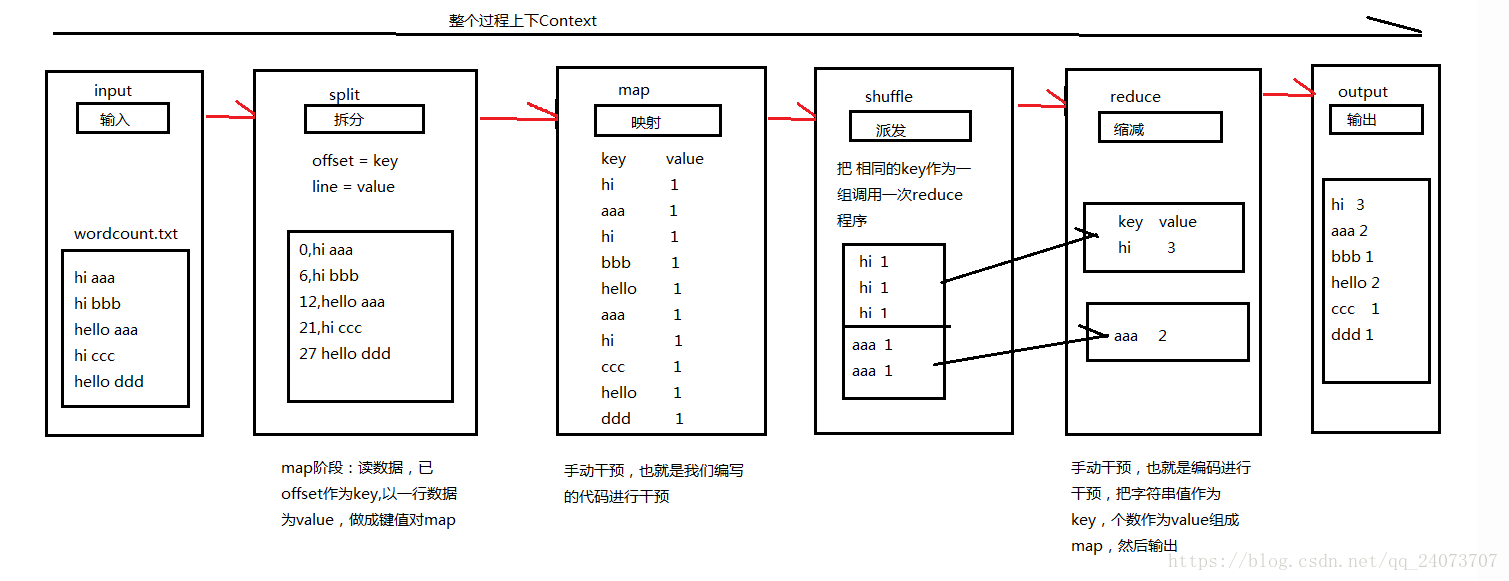
MR注意:重要
1)map数决定了任务的并行度,即影响作业的计算速度,默认一个数据块一个map
2)Shuffle操作具体有(Sort、Partitioner、 Combiner、Merge)
3)不是map进程完成后才能进入reduce,可能map完成60%、reduce已经开始了,如图中shuffle操作,本机数据先做了一次shuffle操作。
4)MR运行慢根本原因:对作业的map结果进行sort排序(有时根本不需要sort)、数据不停地落在磁盘上(读写慢,高消耗IO)。这也是spark优于MR的地方。
————————————————
版权声明:本文为CSDN博主「skwang_君永夜」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32641659/article/details/87966861