做开发的,可能都做过信息采集相关的程序,史林枫也经常做一些数据采集或某些网站的业务办理自动化操作软件。
获取目标网页的信息很简单,使用网络编程,利用HttpWebResponse、HttpWebRequest和WebClient就可以了。
复杂的是获取网页内容后,需要对关键信息进行过滤,最初史林枫主要使用正则表达式来匹配目标数据。
这样的匹配也能达到目的,但对于不熟悉正则表达式的开发者或初学者就比较吃力了,尤其是比较复杂的正则。
最好要有专门的工具先测试,再把正则放到程序中测试。这里推荐RegexTester.exe。
后来,一次偶然的机会接触到HtmlAgilityPack。这是个开源的类库。想研究源码的可以移步这里:HtmlAgilityPack源码
刚开始使用是比较随性的,需要用了就开始new 然后找跟节点,找目标节点,取属性或取文本。使用的多了,就有封装类库的想法,然后在使用过程中不断改进,更新,目前使用还是比较稳定的。
使用的时候需要引用HtmlAgilityPack.dll Visual Studio中的NuGet可以获取到
先上类库源码:
1 /// <summary> 2 /// html文档解析辅助类库 3 /// </summary> 4 public class HtmlParse { 5 private readonly HtmlDocument doc = new HtmlDocument(); 6 7 /// <summary> 8 /// 构造函数 初始化文档并解析 默认utf-8模式 9 /// </summary> 10 /// <param name="htmlOrUrl">获取的html字符串或url链接</param> 11 public HtmlParse(string htmlOrUrl) { 12 InitDoc(htmlOrUrl); 13 } 14 15 /// <summary> 16 /// 构造函数 初始化文档并解析 默认utf-8模式 17 /// </summary> 18 /// <param name="htmlOrUrl">获取的html字符串或url链接</param> 19 /// <param name="encode">字符编码</param> 20 public HtmlParse(string htmlOrUrl, string encode) { 21 InitDoc(htmlOrUrl, encode); 22 } 23 24 25 /// <summary> 26 /// 根据url或html字符串获取文档并解析 27 /// </summary> 28 /// <param name="htmlOrUrl">html字符串或url</param> 29 /// <param name="encode">网站编码</param> 30 /// <returns></returns> 31 public HtmlDocument InitDoc(string htmlOrUrl, string encode = "utf-8") { 32 if (htmlOrUrl.Trim().StartsWith("http")) { 33 htmlOrUrl = NetHelper.GetPageStr(htmlOrUrl, "", encode); 34 } 35 doc.LoadHtml(htmlOrUrl); 36 return doc; 37 } 38 39 /// <summary> 40 /// 获取节点集合 41 /// </summary> 42 /// <param name="xPath"></param> 43 /// <returns></returns> 44 public HtmlNodeCollection GetNodes(string xPath) { 45 return doc.DocumentNode.SelectNodes(xPath); 46 } 47 48 49 /// <summary> 50 /// 获取单个节点 51 /// </summary> 52 /// <param name="xPath"></param> 53 /// <returns></returns> 54 public HtmlNode GetNode(string xPath) { 55 return doc.DocumentNode.SelectSingleNode(xPath); 56 } 57 58 /// <summary> 59 /// 获取节点的属性值 60 /// </summary> 61 /// <param name="node">节点</param> 62 /// <param name="attrName">属性名称</param> 63 /// <returns></returns> 64 public string GetNodeAttr(HtmlNode node, string attrName) { 65 if (node == null || node.Attributes[attrName] == null) { 66 return string.Empty; 67 } 68 return node.Attributes[attrName].Value; 69 } 70 71 /// <summary> 72 /// 获取节点的InnerText的值 73 /// </summary> 74 /// <param name="node"></param> 75 /// <returns></returns> 76 public string GetNodeText(HtmlNode node) { 77 if (node == null) { 78 return string.Empty; 79 } 80 return node.InnerText; 81 } 82 83 /// <summary> 84 /// 获取节点的InnerHtml或OuterHtml值 85 /// </summary> 86 /// <param name="node">节点</param> 87 /// <param name="isOuter">是否要获取OuterHtml</param> 88 /// <returns></returns> 89 public string GetNodeHtml(HtmlNode node, bool isOuter = false) { 90 if (node == null) { 91 return string.Empty; 92 } 93 if (isOuter) { 94 return node.OuterHtml; 95 } 96 return node.InnerHtml; 97 } 98 99 /// <summary> 100 /// 根据Xpath和属性名称获取属性值 101 /// </summary> 102 /// <param name="xPath"></param> 103 /// <param name="attrName"></param> 104 /// <returns></returns> 105 public string GetNodeAttr(string xPath, string attrName) { 106 var node = GetNode(xPath); 107 return GetNodeAttr(node, attrName); 108 } 109 110 /// <summary> 111 /// 根据XPath获取节点的InnerText 112 /// </summary> 113 /// <param name="xPath"></param> 114 /// <returns></returns> 115 public string GetNodeText(string xPath) { 116 var node = GetNode(xPath); 117 return GetNodeText(node); 118 } 119 120 /// <summary> 121 /// 根据XPath获取节点的InnerHtml或OuterHtml值 122 /// </summary> 123 /// <param name="xPath"></param> 124 /// <param name="isOuter"></param> 125 /// <returns></returns> 126 public string GetNodeHtml(string xPath, bool isOuter = false) { 127 var node = GetNode(xPath); 128 return GetNodeHtml(node); 129 } 130 }
提示:想要熟练的使用HtmlAgilityPack,必须要了解XPath的相关知识。不懂的可以移步这里:XPath入门教程
实际上XPath主要注意几个要点就可以解决80%的问题。
1.以/开头的是从根节点开始选取,以//开头的是模糊选取,而不考虑它们的位置
2.可以使用属性来定位要选取的节点或节点集合 比如//span[@class="time"] 就是选择文档中所有class="time"的span元素。
3.节点集合中的某一个使用[i]的方式选取 比如 //span[@class="time"][1] 就是选择文档中所有class="time"的span元素中的第一个span。注意在这里选择节点的索引是从1开始的,而不是0
4.使用| 来做容错选择,比如一个网页中某个数据可能在<div class="a1"></div>中 也可能在<div class="a2"></div> 这时就可以用 //div[@class="a1"]|//div[@class="a2"] 作为XPath
5.XPath中需要用到的引号 可以使用单引号 因为C#中字符串需要用双引号,XPath中需要引号的使用单引号即可,这样不用转义了。
上面还用到了一个NetHelper。主要用于获取Url的内容。这东西网上一大堆,这里就不献丑了。自行结合即可。
使用方法也很简单:
// 比如这里获取我的博客首页内容 并解析当前文章列表
var doc = new HtmlParse("http://www.cnblogs.com/jayshsoft/"); var nodeList = doc.GetNodes("//div[@class='post post-list-item']"); foreach (var node in nodeList) { //这里写自己的逻辑 }
自从封装好类库后,采集内容就变得非常Easy了,只要把流程分析好即可,Html文章中的元素任你宰割,蹂躏。。。
另外,推荐一个FireFox浏览器插件:XPath Checker

有了它 你就可以在浏览器中直接写好XPath,直接看到结果 一目了然
直接上图
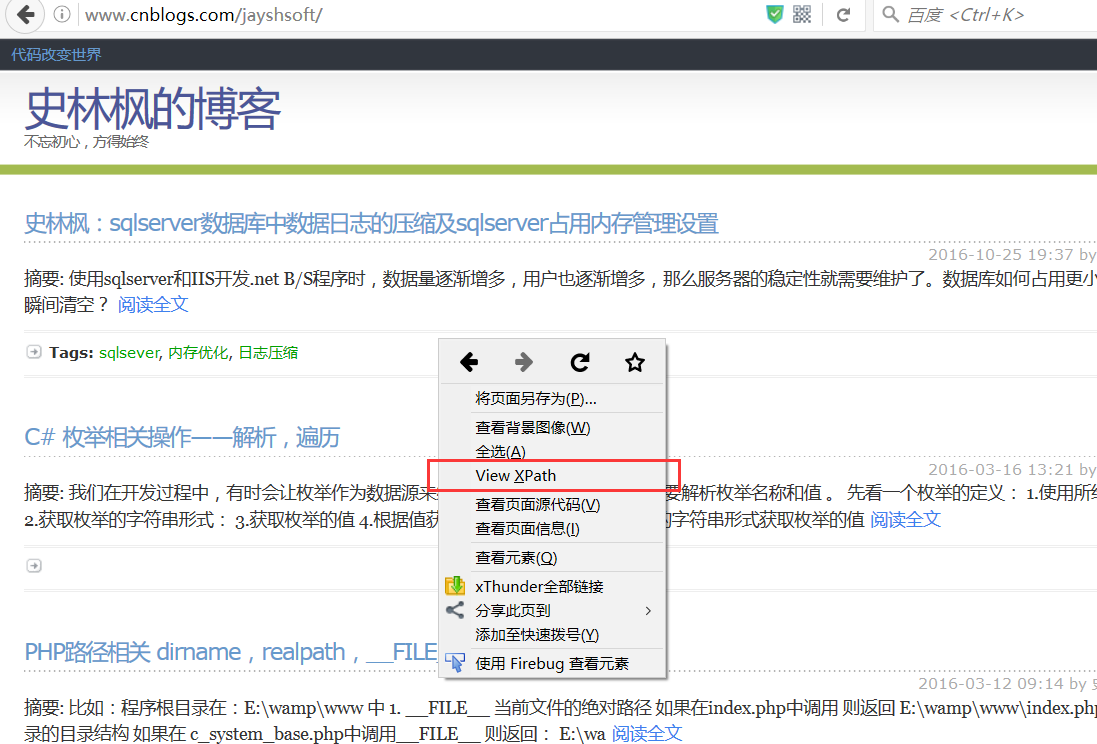
右键点击网页空白处 选择View XPath
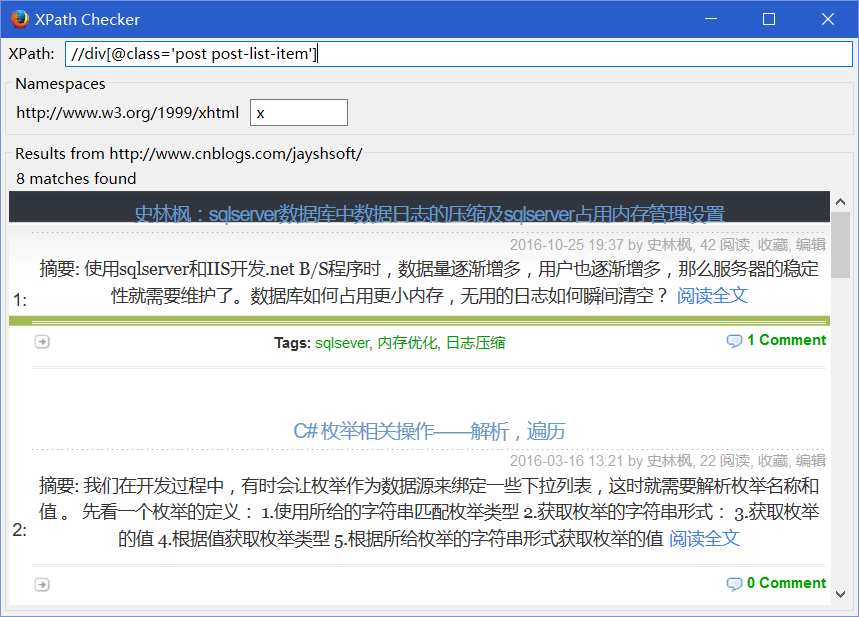
输入XPath 就可以得到你想要的数据了。是不是很直观?是就推荐一下 嘿嘿。。。