from sklearn import tree
from sklearn.datasets import load_wine # 红酒数据
from sklearn.model_selection import train_test_split
wine = load_wine() # 导入数据
wine
{'data': array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
...,
[1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,
8.350e+02],
[1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,
8.400e+02],
[1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,
5.600e+02]]),
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2]),
'target_names': array(['class_0', 'class_1', 'class_2'], dtype='<U7'),
'DESCR': '......rics).
',
'feature_names': ['alcohol',
'malic_acid',
'ash',
'alcalinity_of_ash',
'magnesium',
'total_phenols',
'flavanoids',
'nonflavanoid_phenols',
'proanthocyanins',
'color_intensity',
'hue',
'od280/od315_of_diluted_wines',
'proline']}
import pandas as pd
# 将特征数据与 target拼接起来
wine_df = pd.concat([pd.DataFrame(wine.data), pd.DataFrame(wine.target)] ,axis=1)
wine_df.columns=list(wine.feature_names) + ['target'] # 将数据特征名称与数据对应
wine_df['target'] = wine_df['target'].map(dict(zip(range(3), wine.target_names))) # 显示类别名称
wine_df
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | class_0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | class_0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | class_0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | class_0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | class_0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 173 | 13.71 | 5.65 | 2.45 | 20.5 | 95.0 | 1.68 | 0.61 | 0.52 | 1.06 | 7.70 | 0.64 | 1.74 | 740.0 | class_2 |
| 174 | 13.40 | 3.91 | 2.48 | 23.0 | 102.0 | 1.80 | 0.75 | 0.43 | 1.41 | 7.30 | 0.70 | 1.56 | 750.0 | class_2 |
| 175 | 13.27 | 4.28 | 2.26 | 20.0 | 120.0 | 1.59 | 0.69 | 0.43 | 1.35 | 10.20 | 0.59 | 1.56 | 835.0 | class_2 |
| 176 | 13.17 | 2.59 | 2.37 | 20.0 | 120.0 | 1.65 | 0.68 | 0.53 | 1.46 | 9.30 | 0.60 | 1.62 | 840.0 | class_2 |
| 177 | 14.13 | 4.10 | 2.74 | 24.5 | 96.0 | 2.05 | 0.76 | 0.56 | 1.35 | 9.20 | 0.61 | 1.60 | 560.0 | class_2 |
178 rows × 14 columns
# 拆分数据为:训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target, test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) # 返回准确度
score
0.9444444444444444
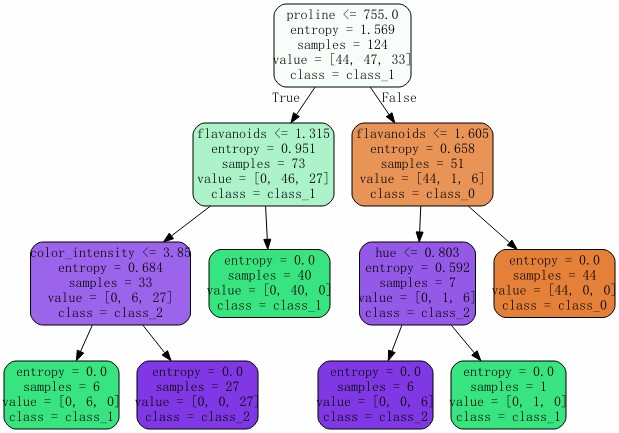
import graphviz # 需要提前安装graphviz
dot_data = tree.export_graphviz(clf
,feature_names = wine.feature_names # 特征名
,class_names = wine.target_names # 标签名
,filled = True # 颜色填充
,rounded = True # 圆角边框
)
graph = graphviz.Source(dot_data)
graph
clf.feature_importances_ # 查看各特征的重要性,没有被使用的特征 重要性为0
array([0. , 0. , 0. , 0. , 0. ,
0. , 0.3918564 , 0. , 0. , 0.1160134 ,
0.02128596, 0. , 0.47084424])
dict(zip(wine.feature_names, clf.feature_importances_)) # 将特征名称与重要性对应
{'alcohol': 0.0,
'malic_acid': 0.0,
'ash': 0.0,
'alcalinity_of_ash': 0.0,
'magnesium': 0.0,
'total_phenols': 0.0,
'flavanoids': 0.26190367697120653,
'nonflavanoid_phenols': 0.0,
'proanthocyanins': 0.0,
'color_intensity': 0.11601339710491781,
'hue': 0.0,
'od280/od315_of_diluted_wines': 0.15123868318487035,
'proline': 0.47084424273900527}
增加决策树随机性
- 决策树的随机性在高维度的数据集中表现的会比较好
- 在低维度数据集(比如鸢尾花数据集中),随机性就表现得不够好
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=50 # 随机种子
# splitter:默认是best,就是上面的重要性。虽然随机,但是还是选择最重要的。
# random让决策树更加随机,树会更大更深
,splitter="random"
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) # 返回准确度
score
0.8888888888888888
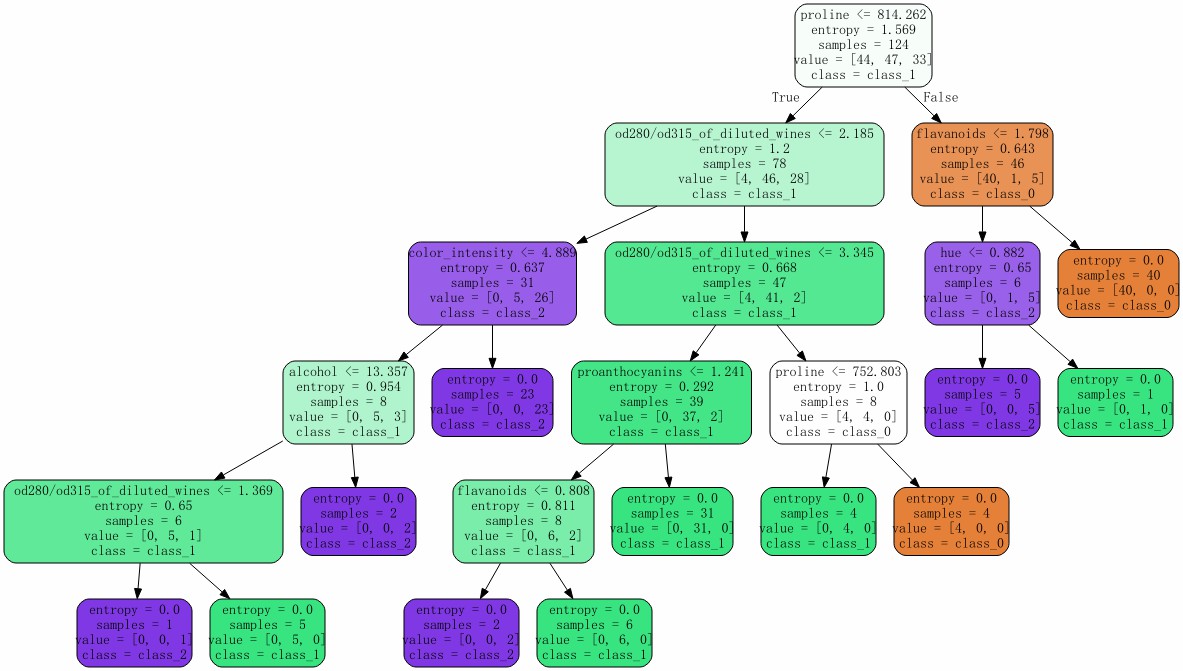
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names = wine.feature_names # 特征名
,class_names = wine.target_names # 标签名
,filled = True # 颜色填充
,rounded = True # 圆角边框
)
graph = graphviz.Source(dot_data)
graph
剪枝参数:min_samples_leaf & min_samples_split
- 为了使决策树具有更大的泛化能力
- 限制树的最大深度,建议从3开始逐渐尝试
- 限制叶子节点数量
- 限制划分节点数量
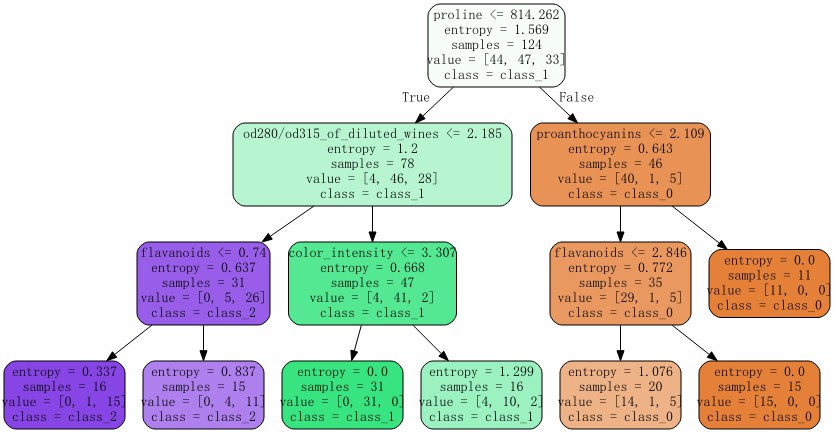
import graphviz
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=50
,splitter="random"
,max_depth = 3
,min_samples_leaf=10 # 将样本数量小于10的叶子节点剪掉
,min_samples_split=10 # 将中间节点样本数量小于10的剪掉
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) # 返回准确度
print(score)
dot_data = tree.export_graphviz(clf
,feature_names = wine.feature_names # 特征名
,class_names = wine.target_names # 标签名
,filled = True # 颜色填充
,rounded = True # 圆角边框
)
graph = graphviz.Source(dot_data)
graph
0.8518518518518519
max_features & min_impurity_decrease
- max_features:最大特征数量限制,超过限制的特征会被舍弃,是一种降维方式,使用较少
- min_impurity_decrease:限制信息增益大小,当信息增益小于这个值,就不再进行分支了
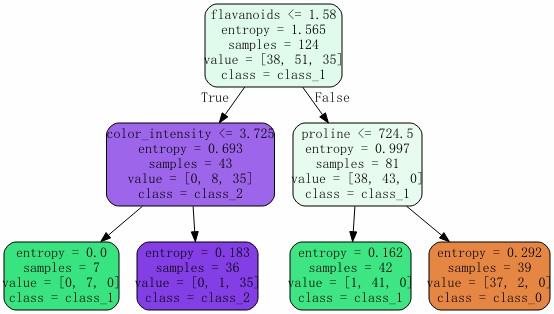
import graphviz
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=50
# ,splitter="random"
,max_depth = 5
# ,min_samples_leaf=10 # 将样本数量小于10的叶子节点剪掉
# ,min_samples_split=10 # 将中间节点样本数量小于10的剪掉
# ,max_features = 2
,min_impurity_decrease=0.1
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) # 返回准确度
print(score)
dot_data = tree.export_graphviz(clf
,feature_names = wine.feature_names # 特征名
,class_names = wine.target_names # 标签名
,filled = True # 颜色填充
,rounded = True # 圆角边框
)
graph = graphviz.Source(dot_data)
graph
0.9444444444444444
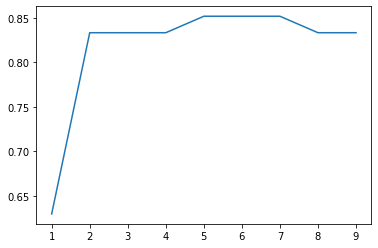
确认最优参数,画学习曲线
import matplotlib.pyplot as plt
deths_rt = []
for dep in range(1, 10):
clf = tree.DecisionTreeClassifier(criterion="entropy"
,max_depth = dep
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) # 返回准确度
deths_rt.append(score)
plt.plot(range(1, 10), deths_rt)
目标权重参数
- class_weight & min_weight_fraction_leaf
- 注意:sklearn不接受一维矩阵
class_weight # 目标类型的权重,其数据类型为dict或者列表内的dict,或者为"balanced"
min_weight_fraction_leaf # 权重剪枝参数,搭配目标权重使用,比min_samples_leaf更偏向于主导类
其他常用接口
# 返回样本所在叶子节点的索引
clf.apply(X_test)
array([ 5, 5, 5, 4, 3, 5, 5, 5, 5, 10, 10, 5, 5, 3, 10, 10, 10,
5, 4, 5, 10, 4, 5, 10, 5, 5, 4, 5, 4, 4, 5, 4, 4, 10,
10, 5, 4, 5, 5, 5, 4, 10, 10, 10, 5, 5, 10, 4, 10, 10, 5,
5, 5, 10], dtype=int64)
# 返回预测标签
clf.predict(X_test
array([1, 1, 1, 2, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 2, 1, 0, 2,
1, 0, 1, 1, 2, 1, 2, 2, 1, 2, 2, 0, 0, 1, 2, 1, 1, 1, 2, 0, 0, 0,
1, 1, 0, 2, 0, 0, 1, 1, 1, 0])