对于MapReduce模型的实现,有Java等一些语言实现了接口,或者用像Hive/Pig这样的平台来操作。MapReduce由Map函数、Reduce函数和Main函数实现。第一步,源数据文件按默认文件系统块大小分割成M个数据块后传给M个Map函数,M个Map函数分布在N台机器上。Map函数接受两个参数传入,第一个参数是键值(key),第二个参数是数据值(value),其实这就是一个tuple。文件中一行就是一个tuple的元素,key就是行在文件内的偏移量(offset)。给Map的数据看上去像这样:
(0, 0067011990999991950051507004…9999999N9+00001+99999999999…)
(106, 0043011990999991950051512004…9999999N9+00221+99999999999…)
(212, 0043011990999991950051518004…9999999N9-00111+99999999999…)
(318, 0043012650999991949032412004…0500001N9+01111+99999999999…)
(424, 0043012650999991949032418004…0500001N9+00781+99999999999…)
但是这个偏移量其实对于后面对MapReduce的实现没有用。我们需要做的是Map函数按照我们希望得到的数据结构进行分组生成一个新的tuple。Map函数会生成一个新的tuple,key变成我们希望的字段的值。tuple的值就是后面需要用到的值了。Map函数做的事情就是这么简单。Map输出的数据流不会马上进入到Reduce函数,而是有一个中间处理的过程(shuffle)来对数据进行排序和整合到一块。这一步我们不需要去实现,像Java这样的MapReduce接口已经自动实现这一步。这一步的目的是为了减小结果集,降低网络IO。合并数据结果集完成后再对数据进行分割(Partition),这个过程通过Hash函数对Key生成哈希值后和N进行模(Mod)运算,N=Reduce函数的数量,目的是为了让每个Reduce函数都处理一段范围的数据。结果存储以本地文件的形式存储。然后通知JobTracker自己的任务完成了并把中间结果集文件的地址告诉它。JobTacker再告诉TaskTracker接下来去哪拿到文件然后调用Reduce函数处理。这里问题就来了,不同的文件块在不同的节点上处理,那这里是不是需要不同的节点在彼此间进行数据交换,把应该别的节点处理的数据丢给他,自己也接受别的节点给过来的需要自己处理的数据,然后再生成文件存储在本地,等待TaskTracker下一步调用Reduce函数去处理它?可以这么看,其实整个过程就是数据流,利用元组或者数组(tuple)的形式存储一对值,按照值进行数据集整理,这样看有点类似于数据库里压缩技术,就是关键字压缩。最后丢给Reduce函数的元组看上去是这样(1, [a,b,c])。Reduce函数接收到元组再把元组中List的数据值拿出来进行计算。整个过程Map函数通过一个迭代器把键值对传给Reduce函数,这样不会出现内存溢出的情况。Map和Reduce在Data node由不同的Task tracker来执行。
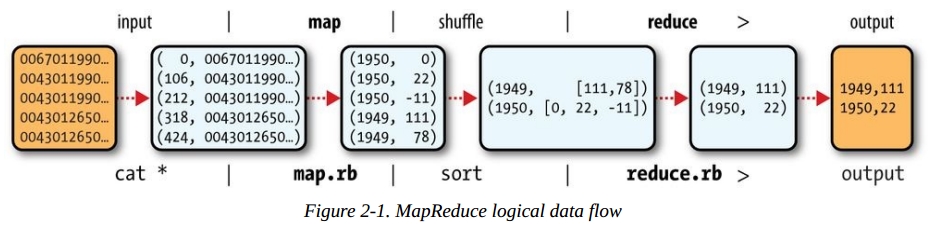
这里留下一些问题,在《Hadoop实战》一书中作者讲到Map函数输出的结果集在合并之后(也就是sort and merge这一步)可以进行数据分割(Partition),再给到Reduce函数去处理。这点倒是上面这张图没有体现出来的。
可以预先定义R个Reduce函数来接受分割后的input数据集,前一步分割的数据集的个数等于这个R。这时我想起了之前《Hadoop in action》一书讲到的可以通过多少JVM来启动多个任务来并行执行多个map函数和reduce函数。R个Reduce函数最终输出结果再合并成一个文件或者作为下一个任务管道的输入。