一个网页的节点太多,一个个的用正则表达式去查找不方便且不灵活。BeautifulSoup将html文档转换成一个属性结构,每个节点都是python对象。这样我们就能针对每个结点进行操作。参考如下代码:
from urllib.request import urlopen
from urllib import error
from bs4 import BeautifulSoup
try:
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
bsObj = BeautifulSoup(html.read())
except error.HTTPError as e:
print("HTTPError:.....")
except error.URLError as e:
print("URLError....")
else:
print(bsObj.h1)
BeautifulSoup中传入的就是urlopen中反馈的html网页。
运行结果报错:

解决方法:
这个提示的意思是没有给BeautifulSoup中传递一个解析网页的方式。有2中方式可以使用:html.parser以及lxml。这里我们先用html.parser,lxml。
看源码:
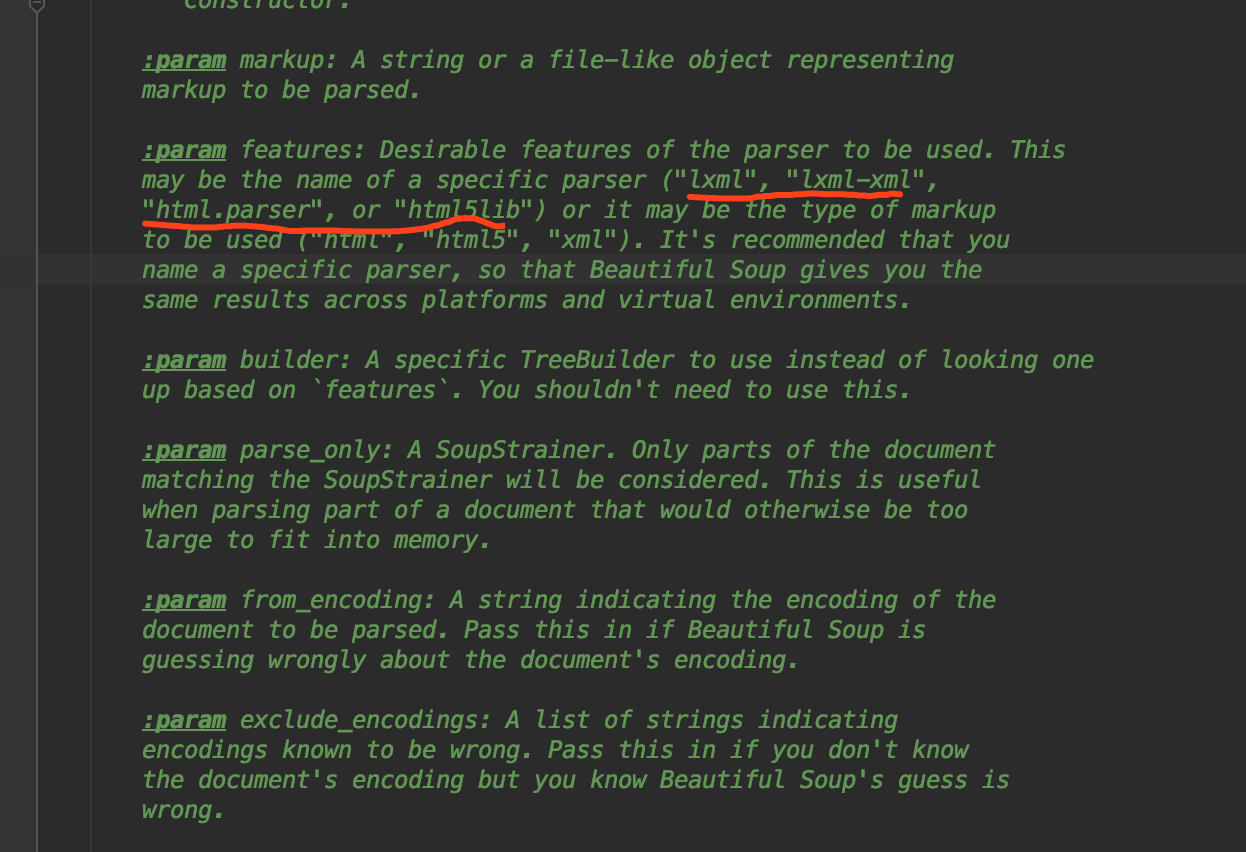
需要传入这四种解析方式。