参考:https://blog.csdn.net/exiaojiu/article/details/51252515
http://www.cnblogs.com/wangjun1234/p/3719635.html
源代码版本为 .NET Framework 4.6.1
Dictionary是Hashtable的一种泛型实现(也是一种哈希表)实现了IDictionary泛型接口和非泛型接口等,将键映射到相应的值。任何非 null 对象都可以用作键。使用与Hashtable不同的冲突解决方法,Dictionary使用拉链法。
概念重播
对于不同的关键字可能得到同一哈希地址,即key1 != key2 => F(key1)=F(fey2),这种现象叫做冲突,在一般情况下,冲突只能尽可能的少,而不能完全避免。因为,哈希函数是从关键字集合到地址集合的映像。通常,关键字集合比较大,它的元素包括很多有可能的关键字。既然如此,那么,如何处理冲突则是构造哈希表不可缺少的一个方面。
通常用于处理冲突的方法有:开放定址法、再哈希法、链地址法、建立一个公共溢出区等。
在哈希表上进行查找的过程和哈希造表的过程基本一致。给定K值,根据造表时设定的哈希函数求得哈希地址,若表中此位置没有记录,则查找不成功;否则比较关键字,若和给定值相等,则查找成功;否则根据处理冲突的方法寻找“下一地址”,只到哈希表中某个位置为空或者表中所填记录的关键字等于给定值时为止。
哈希函数
Dictionary使用的哈希函数是除留余数法,在源码中的公式为:
h = F(k) % m; m 为哈希表长度(这个长度一般为素数)
(内部有一个素数数组:3,7,11,17....如图: );
);
通过给定或默认的GetHashCode()函数计算出关键字的哈希码模以哈希表长度,计算出哈希地址。
拉链法
Dictionary使用的解决冲突方法是拉链法,又称链地址法。
拉链法的原理:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。结构图大致如下:
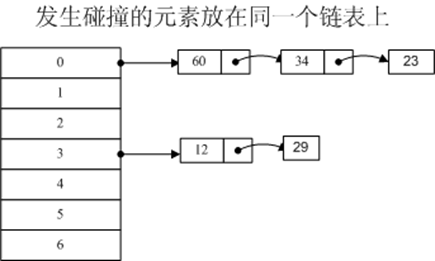
特别强调:拉链法只是使用链表的原理去解决冲突,并不是真的有一个链表存在。
基本成员
1 private struct Entry { 2 public int hashCode; //31位散列值,32最高位表示符号位,-1表示未使用 3 public int next; //下一项的索引值,-1表示结尾 4 public TKey key; //键 5 public TValue value; //值 6 } 7 8 private int[] buckets;//内部维护的数据地址 9 private Entry[] entries;//元素数组,用于维护哈希表中的数据 10 private int count;//元素数量 11 private int version; 12 private int freeList;//空闲的列表 13 private int freeCount;//空闲列表元素数量 14 private IEqualityComparer<TKey> comparer;//哈希表中的比较函数 15 private KeyCollection keys;//键集合 16 private ValueCollection values;//值集合 17 private Object _syncRoot;
buckets 就想在哈希函数与entries之间解耦的一层关系,哈希函数的F(k)变化不在直接影响到entries。
freeList 类似一个单链表,用于存储被释放出来的空间即空链表,一般有被优先存入数据。
freeCount 空链表的空位数量。
初始化函数
该函数用于,初始化的数据构造
1 private void Initialize(int capacity) { 2 //根据构造函数设定的初始容量,获取一个近似的素数 3 int size = HashHelpers.GetPrime(capacity); 4 buckets = new int[size]; 5 for (int i = 0; i < buckets.Length; i++) buckets[i] = -1; 6 entries = new Entry[size]; 7 freeList = -1; 8 }
初始化Dictionary内部数组容器:buckets int[]和entries<T,V>[],分别分配长度3。
(内部有一个素数数组:3,7,11,17....如图:);
size 哈希表的长度是素数,可以使元素更均匀地分布在每个节点上。
buckets 中的节点值,-1表示空值。
freeList 为-1表示没有空链表。
buckets 和 freeList 所值指向的数据其实全是存储于一块连续的内存空间(entries )之中。
插入元素
1 public void Add(TKey key, TValue value) { 2 Insert(key, value, true); 3 } 4 private void Insert(TKey key, TValue value, bool add){ 5 if( key == null ) { 6 ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); 7 } 8 9 if (buckets == null) Initialize(0); 10 int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; 11 int targetBucket = hashCode % buckets.Length; 12 13 //循环冲突 14 for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) { 15 if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) { 16 if (add) { 17 ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate); 18 } 19 entries[i].value = value; 20 version++; 21 return; 22 } 23 24 collisionCount++; 25 } 26 27 //添加元素 28 int index; 29 //是否有空列表 30 if (freeCount > 0) { 31 index = freeList; 32 freeList = entries[index].next; 33 freeCount--; 34 } 35 else { 36 if (count == entries.Length) 37 { 38 Resize();//自动扩容 39 targetBucket = hashCode % buckets.Length;//哈希函数寻址 40 } 41 index = count; 42 count++; 43 } 44 45 entries[index].hashCode = hashCode; 46 entries[index].next = buckets[targetBucket]; 47 entries[index].key = key; 48 entries[index].value = value; 49 buckets[targetBucket] = index; 50 51 //单链接的节点数(冲突数)达到了一定的阈值,之后更新散列值 52 if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer)) 53 { 54 comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer); 55 Resize(entries.Length, true); 56 } 57 }
思路分析:
(1)通过哈希函数寻址,计算出哈希地址(因为中间有一个解耦关系buckets,所以不再直接指向entries的索引值,而是buckets的索引)。
(2)判断buckets中映射到的值是否为-1(即为空位)。若不为-1,表示有冲突,遍历冲突链,不允许重复的键。
(3)判断是否有空链表,有则插入空链表的当前位置,将freeList指针后移,freeCount减一,否则将元素插入当前空位。在这一步,容量不足将自动扩容,若当前位置已经存在元素则将该元素的地址存在插入元素的next中,形成一个单链表的形式。类似下图中的索引0。
移除
1 public bool Remove(TKey key) { 2 if(key == null) { 3 ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); 4 } 5 6 if (buckets != null) { 7 int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; 8 int bucket = hashCode % buckets.Length; 9 int last = -1;//记录上一个节点 10 //定位到一个单链表,每一个节点都会保存下一个节点的地址,操作不再重新计算哈希地址 11 for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) { 12 if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) { 13 if (last < 0) { 14 buckets[bucket] = entries[i].next; 15 } 16 else { 17 entries[last].next = entries[i].next; 18 } 19 entries[i].hashCode = -1;//移除的元素散列值值为-1 20 entries[i].next = freeList;//将移除的元素放入空列表 21 entries[i].key = default(TKey); 22 entries[i].value = default(TValue); 23 freeList = i;//记录当前地址,以便下个元素能直接插入 24 freeCount++;//空链表节点数+1 25 version++; 26 return true; 27 } 28 } 29 } 30 return false; 31 }
Dictionary中存储元素的结构非常有趣,通过一个数据桶buckets将哈希函数与数据数组进行了解耦,使得每一个buckets的值对应的都是一条单链表,在内存空间上却是连续的存储块。同时Dictionary在空间与性能之间做了一些取舍,消耗了空间,提升了性能(影响性能的最大因素是哈希函数)。
移除思路分析:
(1)通过哈希函数确定单链表的位置,然后进行遍历。
(2)该索引对应的值为-1,表示没有没有单链接节点,返回false,结束
(3)该索引对应的值大于-1,表示有单链表节点,进行遍历,对比散列值与key,将映射到的entries节点散列值赋-1,next指向空链表的第一个元素地址(-1为头节点),freeList指向头节点地址,空链表节点数+1,返回true,结束;否则返回false,结束。(此处的节点地址统指索引值)。
查询
1 public bool TryGetValue(TKey key, out TValue value) { 2 int i = FindEntry(key);//关键方法 3 if (i >= 0) { 4 value = entries[i].value; 5 return true; 6 } 7 value = default(TValue); 8 return false; 9 } 10 11 12 private int FindEntry(TKey key) { 13 if( key == null) { 14 ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); 15 } 16 17 if (buckets != null) { 18 int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; 19 for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) { 20 if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i; 21 } 22 } 23 return -1; 24 }
代码是不是一目了然,在FindEntry方法中,定位单链接的位置,进行遍历,对比散列值与key,比较成功则返回true,结束。
扩容
1 private void Resize() { 2 Resize(HashHelpers.ExpandPrime(count), false); 3 } 4 5 private void Resize(int newSize, bool forceNewHashCodes) { 6 Contract.Assert(newSize >= entries.Length); 7 8 //重新初始化一个比原来空间还要大2倍左右的buckets和Entries,用于接收原来的buckets和Entries的数据 9 int[] newBuckets = new int[newSize]; 10 for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1; 11 Entry[] newEntries = new Entry[newSize]; 12 13 //数据搬家 14 Array.Copy(entries, 0, newEntries, 0, count); 15 16 //将散列值刷新,这是在某一个单链表节点数到达一个阈值(100)时触发 17 if(forceNewHashCodes) { 18 for (int i = 0; i < count; i++) { 19 if(newEntries[i].hashCode != -1) { 20 newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key) & 0x7FFFFFFF); 21 } 22 } 23 } 24 25 //单链表数据对齐,无关顺序 26 for (int i = 0; i < count; i++) { 27 if (newEntries[i].hashCode >= 0) { 28 int bucket = newEntries[i].hashCode % newSize; 29 newEntries[i].next = newBuckets[bucket]; 30 newBuckets[bucket] = i; 31 } 32 } 33 buckets = newBuckets; 34 entries = newEntries; 35 }
foreach遍历
Dictionary实现了IEnumerator接口,是可以用foreach进行遍历的,遍历的集合元素类型为KeyValuePair,是一种键值对的结构,实现是很简单的,包含了最基本的键属性和值属性,
从代码中可以看出,用foreach遍历Dictionary就像用for遍历一个基础数组一样。
这是内部类Enumerator(遍历就是对它进行的操作)中的方法MoveNext(实现IEnumerator接口的MoveNext方法)。
1 public bool MoveNext() { 2 if (version != dictionary.version) { 3 ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion); 4 } 5 6 while ((uint)index < (uint)dictionary.count) { 7 if (dictionary.entries[index].hashCode >= 0) { 8 current = new KeyValuePair<TKey, TValue>(dictionary.entries[index].key, dictionary.entries[index].value); 9 index++; 10 return true; 11 } 12 index++; 13 } 14 15 index = dictionary.count + 1; 16 current = new KeyValuePair<TKey, TValue>(); 17 return false; 18 } 19 20 21 public struct KeyValuePair<TKey, TValue> { 22 private TKey key; 23 private TValue value; 24 25 public KeyValuePair(TKey key, TValue value) { 26 this.key = key; 27 this.value = value; 28 } 29 30 //键属性 31 public TKey Key { 32 get { return key; } 33 } 34 35 //值属性 36 public TValue Value { 37 get { return value; } 38 } 39 40 public override string ToString() { 41 StringBuilder s = StringBuilderCache.Acquire(); 42 s.Append('['); 43 if( Key != null) { 44 s.Append(Key.ToString()); 45 } 46 s.Append(", "); 47 if( Value != null) { 48 s.Append(Value.ToString()); 49 } 50 s.Append(']'); 51 return StringBuilderCache.GetStringAndRelease(s); 52 } 53 }
Dictionary内部实现结构比Hashtable复杂,因为具有单链表的特性,效率也比Hashtable高。
举例说明:
一,实例化一个Dictionary, Dictionary<string,string> dic=new Dictionary<string,string>();
a,调用Dictionary默认无参构造函数。
b,初始化Dictionary内部数组容器:buckets int[]和entries<T,V>[],分别分配长度3。(内部有一个素数数组:3,7,11,17....如图:);
二,向dic添加一个值,dic.add("a","abc");
a,将bucket数组和entries数组扩容3个长度。
b,计算"a"的哈希值,
c,然后与bucket数组长度(3)进行取模计算,假如结果为:2
d,因为a是第一次写入,则自动将a的值赋值到entriys[0]的key,同理将"abc"赋值给entriys[0].value,将上面b步骤的哈希值赋值给entriys[0].hashCode,
entriys[0].next 赋值为-1,hashCode赋值b步骤计算出来的哈希值。
e,在bucket[2]存储0。
三,通过key获取对应的value, var v=dic["a"];
a, 先计算"a"的哈希值,假如结果为2,
b,根据上一步骤结果,找到buckets数组索引为2上的值,假如该值为0.
c, 找到到entriys数组上索引为0的key,
1),如果该key值和输入的的“a”字符相同,则对应的value值就是需要查找的值。
2) ,如果该key值和输入的"a"字符不相同,说明发生了碰撞,这时获取对应的next值,根据next值定位buckets数组(buckets[next]),然后获取对应buckets上存储的值在定位到entriys数组上,......,一直到找到为止。
3),如果该key值和输入的"a"字符不相同并且对应的next值为-1,则说明Dictionary不包含字符“a”。
基本成员