1:pandas常用统计方法


2:数据的合并和分组聚合
2.1

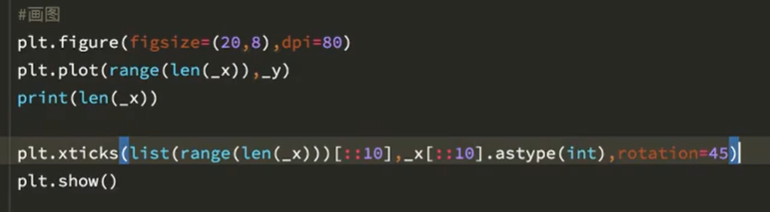
[注]plt.figure()参数详解请参考http://www.yuepc.com/a/1507.html
2.2数据合并之join

[注]t1.join(t2)则以t1为基准,t2.join(t1)则以t2为基准。如下:
[注]如果没有相同的行,则不能进行合并。
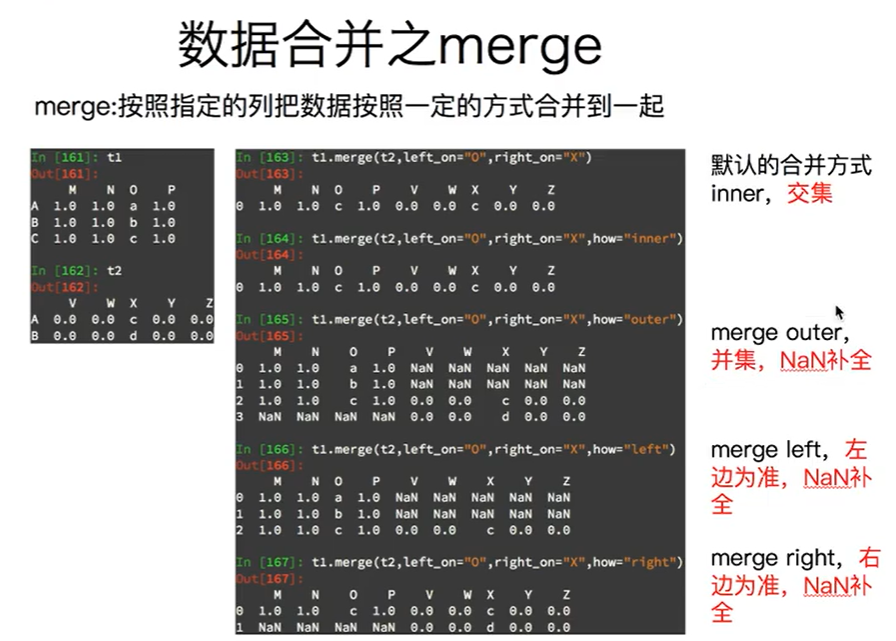
2.3数据合并之merge
2.4分组聚合


按单字段分组的常用操作:

聚合的常用操作:

按多字段进行分组的常用操作:


【注】当对df进行分组时,可以直接使用:by=['country','state/Province'],如果对df['country']进行分组时则必须使用:by=[df['country'],df['state/province']].
【注】当使用多字段对df['']分组时,得到的结果为series类型。如果想要得到dataFrame类型的数据,可以使用对字段对df[['','']]分组。(df[['','']]表示可以取多列).
3.索引和符合索引
简单的索引操作:

series数据类型的复合索引:


DataFrame数据类型的复合索引:

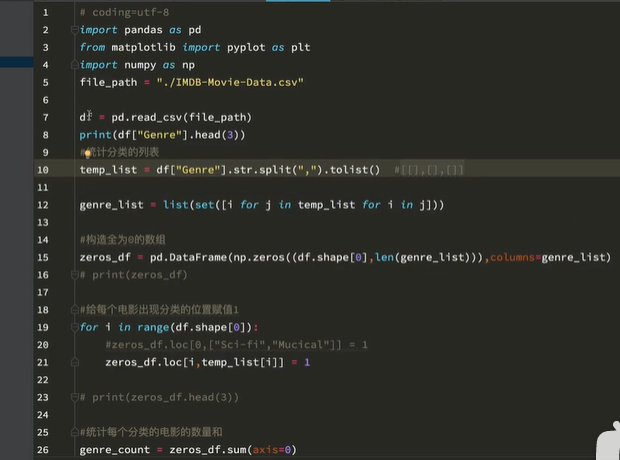
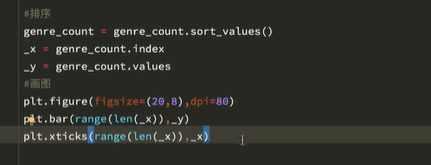
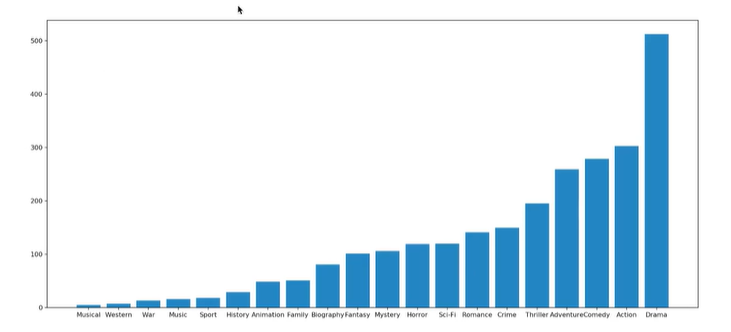
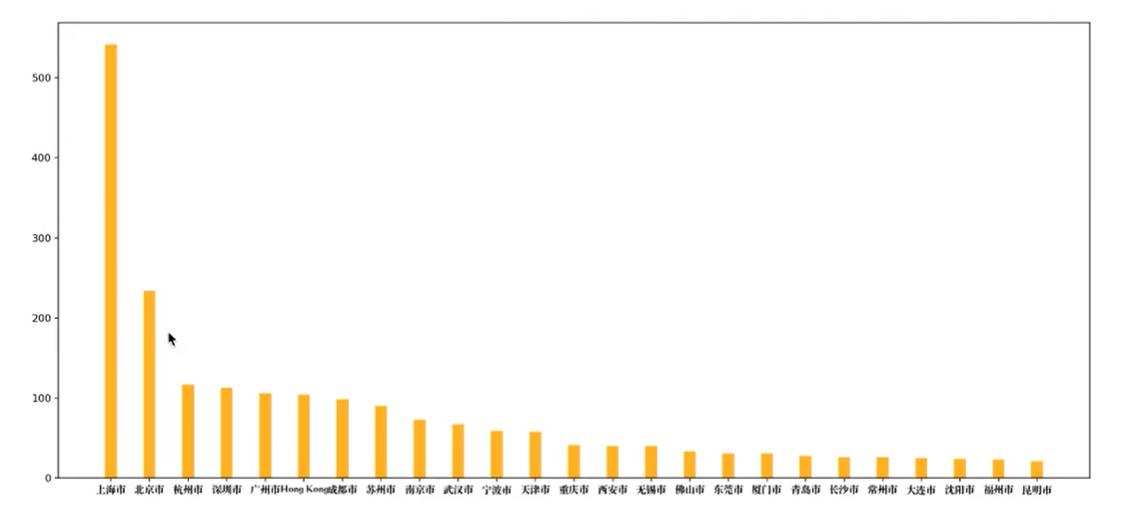
实战案列1:

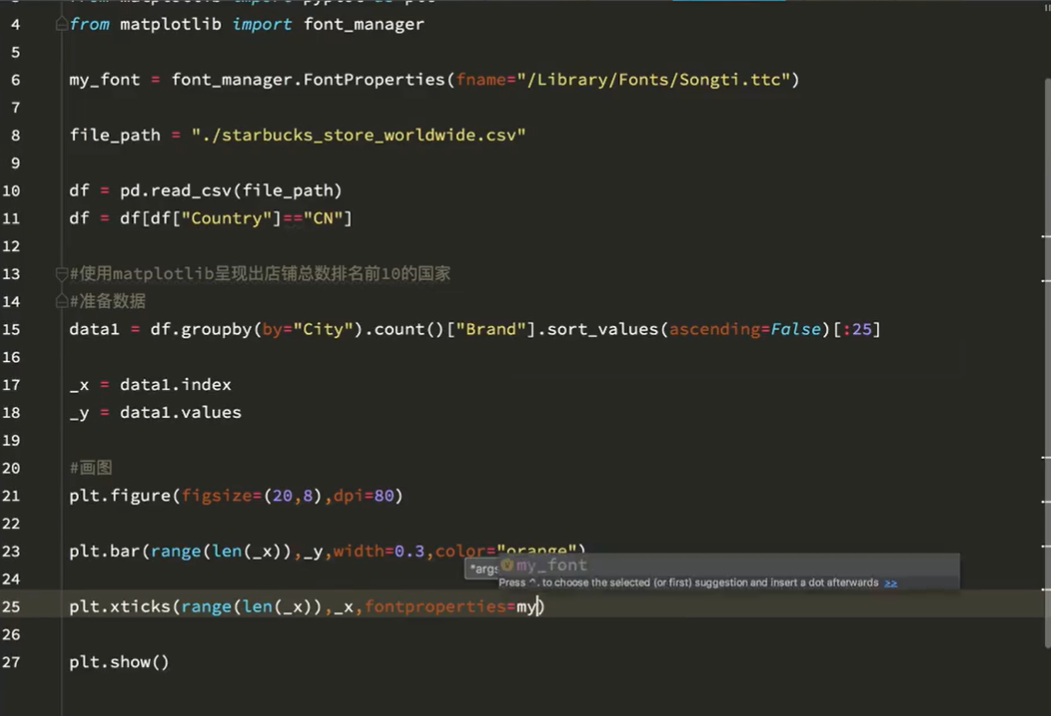
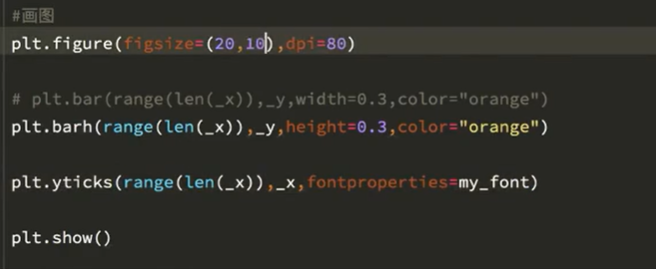
【注】可以使用两种画图方式。
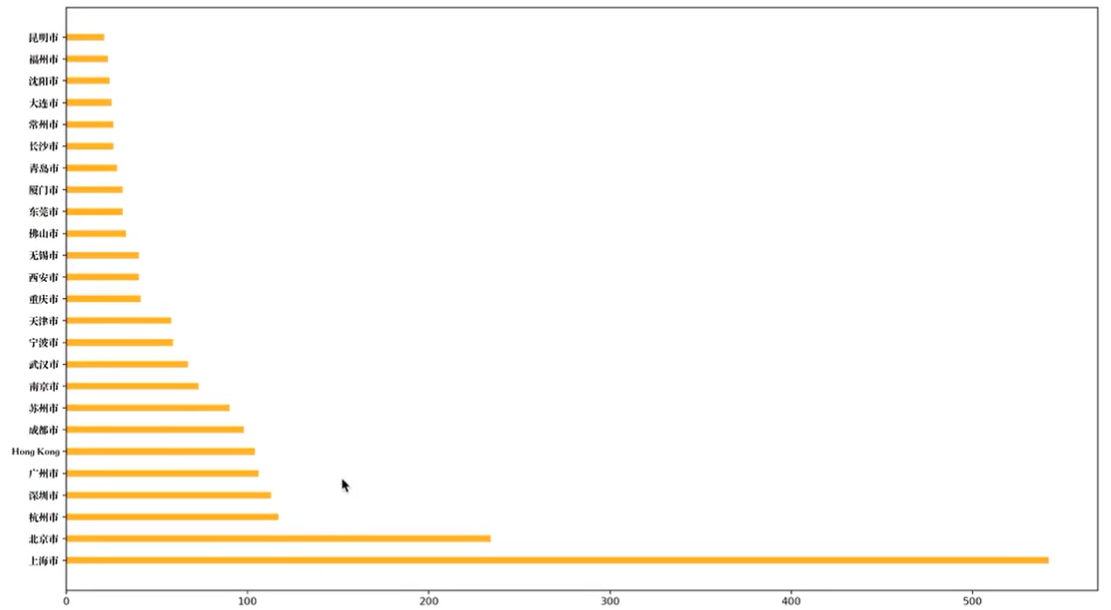
实战案例2: