一、基本概念
1.什么是hive
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
简洁的中文解释就是:
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
数据仓库的概念可以先查看百度百科的介绍:
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
数据库与数据仓库的区别对比,参考知乎相关问题 :https://www.zhihu.com/question/20623931
更加详细的数仓的介绍与深入,将另开随笔介绍!
2.为什么用hive
- 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
- 为什么要使用Hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
扩展功能很方便。
3.hive架构
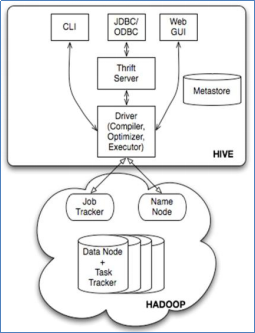
基本组件:
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql , derby中。
- 解释器、编译器、优化器、执行器。
组件功能:
- 用户接口主要由三个:CLI、JDBC/ODBC和WebGUI。其中,CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
- 元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
更多详细的hive体系架构深入介绍,参考:http://blog.csdn.net/zhoudaxia/article/details/8855937
4.hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询数据
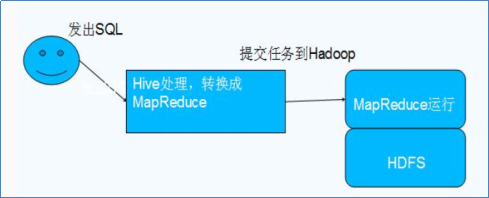
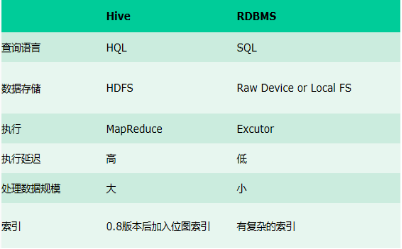
与传统数据库对比:
补充计算框架tez:https://www.cnblogs.com/yjt1993/p/11044578.html
性能优于MR的DAG计算框架!
5.hive数据存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
² db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
² table:在hdfs中表现所属db目录下一个文件夹
² external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
内外部表的区别:
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table); 区别: 内部表数据由Hive自身管理,外部表数据由HDFS管理; 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定; 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除; 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
使用场景:
外部表使用场景:导入hdfs中的源数据
内部表使用场景:存放Hive处理的中间表、结果表
如:
每天将日志数据传入HDFS,一天一个目录;Hive基于流入的数据建立外部表,将每天HDFS上的原始日志映射到外部表的天分区中;
在外部表基础上做统计分析,使用内部表存储中间表、结果表,数据通过SELECT+INSERT进入内部表
内部表外部表的区别,我们可以参考:https://blog.csdn.net/qq_36743482/article/details/78393678
https://www.jianshu.com/p/cd30f7980e9f
² partition:在hdfs中表现为table目录下的子目录
² bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
二、hive安装与配置
###hive可视化工具推荐:http://lxw1234.com/archives/2016/09/723.htm
https://www.cnblogs.com/wujiadong2014/p/6058851.html
1.准备安装包——推荐使用sftp上传,更快速!

2.解压
与之前保持一致,解压至apps,当然到usr/local等自定义的目录是完全没毛病的
[hadoop@mini1 ~]$ tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps/
顺便将解压出来的文件夹的过长的名字稍作更改:
[hadoop@mini1 apps]$ mv apache-hive-1.2.1-bin/ hive-1.2.1
3.安装mysql
由于hive是默认将元数据保存在本地内嵌的 Derby 数据库中,但是这种做法缺点也很明显,Derby不支持多会话连接,因此本文将选择mysql作为元数据存储。
mysql的安装参考之前linux的随笔,注意开启用户远程登录!
4.配置元数据库信息
这里暂时不修改默认的了,在conf目录下使用一个新的配置文件hive-site.xml:
vi hive-site.xml
以下配置项也是简单易懂的:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Zcc170821#</value>
<description>password to use against metastore database</description>
</property>
</configuration>
hive进行元数据管理,参考介绍:https://www.cnblogs.com/qingyunzong/p/8710356.html#_label2
5.添加mysql驱动包
在lib目录下添加驱动包

6.替换JLine的jar包
解决Jline包版本不一致的问题
[hadoop@mini1 lib]$ rm ~/apps/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar
[hadoop@mini1 lib]$ cp jline-2.12.jar ~/apps/hadoop-2.6.4/share/hadoop/yarn/lib/
7.配置环境变量
[hadoop@mini1 hive-1.2.1]$ sudo vim /etc/profile
export HIVE_HOME=/home/hadoop/apps/hive-1.2.1
export PATH=$PATH:$HIVE_HOME/bin
[hadoop@mini1 hive-1.2.1]$ source /etc/profile
8.初体验
启动之前,需要启动MySQL
systemctl start mysql
启动ZK(已编写一键启停脚本在/root下)
/root/bin/startZK.sh
启动Hadoop(在hadoop/sbin下已有脚本,配置即可)
sbin/start-dfs.sh sbin/start-yarn.sh
启动hive:
[hadoop@mini1 hive-1.2.1]$ bin/hive
// 配置环境变量后可以直接启动
建库:
hive> create database shizhan01;
OK
Time taken: 0.943 seconds
hive>

建表:
hive> use shizhan01;
OK
Time taken: 0.049 seconds
hive> create table t_user(id int,name string);
OK
Time taken: 0.395 seconds
hive>
// hive中使用完全的java数据类型即可!
查看元数据:
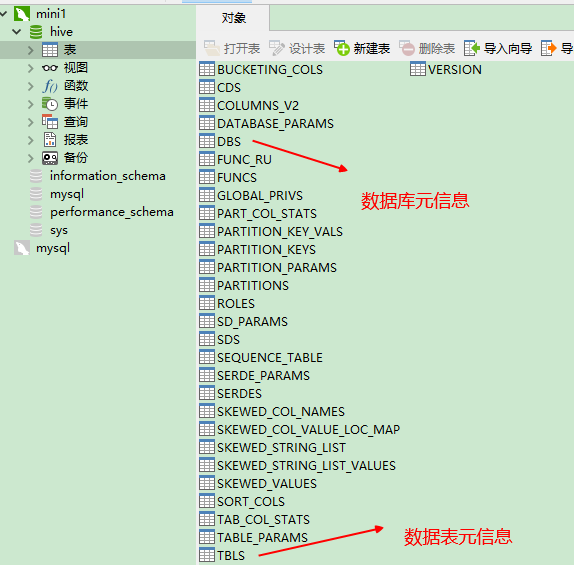
删除t_user;重新建表指定数据格式:
hive> create table t_user01(id int,name string)
> row format delimited
> fields terminated by ','
> ;
OK
Time taken: 0.074 seconds
hive>
上传测试数据:
[hadoop@mini1 ~]$ vim user.dat
[hadoop@mini1 ~]$ ls
apache-hive-1.2.1-bin.tar.gz apps hadoop-2.6.4.tar.gz hdpdata user.dat
[hadoop@mini1 ~]$ hadoop fs -put user.dat /user/hive/warehouse/shizhan01.db/t_user
正常查询:
hive> select * from t_user01;
OK
1 Join
2 Mary
3 Bob
通过mr任务:
hive> select count(*) from t_user01;
Query ID = hadoop_20180224172255_b984036d-5bdd-44fc-bfb5-380b9a433034
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1519458521203_0001, Tracking URL = http://mini1:8088/proxy/application_1519458521203_0001/
Kill Command = /home/hadoop/apps/hadoop-2.6.4/bin/hadoop job -kill job_1519458521203_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-02-24 17:23:09,002 Stage-1 map = 0%, reduce = 0%
2018-02-24 17:23:15,635 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.29 sec
2018-02-24 17:23:25,213 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.63 sec
MapReduce Total cumulative CPU time: 2 seconds 630 msec
Ended Job = job_1519458521203_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.63 sec HDFS Read: 6416 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 630 msec
OK
4
Time taken: 31.956 seconds, Fetched: 1 row(s)
hive>
三、启动为thrift服务
1.启动
启动为前台:bin/hiveserver2
启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
2.连接
使用支持thrift服务的进行连接,这里采用hive默认提供的beeline(另外复制一个SSH隧道)
[hadoop@mini1 ~]$ beeline Beeline version 1.2.1 by Apache Hive beeline> !connect jdbc:hive2://localhost:10000 Connecting to jdbc:hive2://localhost:10000 Enter username for jdbc:hive2://localhost:10000: hadoop Enter password for jdbc:hive2://localhost:10000: Connected to: Apache Hive (version 1.2.1) Driver: Hive JDBC (version 1.2.1) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000>
// 默认是使用hadoop用户无密码登录即可,或者进行配置(当然配置的意义不大)
或者使用启动即连接:
bin/beeline -u jdbc:hive2://localhost:10000 -n hadoop
当然,更加推荐的方式是自己在有环境变量的bin下写个启动脚本,以后就可以使用startbeeline.sh等自定义脚本一键启动了!
补充:
也可以通过hive -e 'sql'的形式
[hadoop@mini1 ~]$ hive -e 'sql'
这样的好处是执行完了回到命令行,也就是可以通过shell脚本来执行一连串的sql了,而不用一个一个在命令行敲了!
或者执行某个sql文件
[hadoop@mini1 ~]$ hive -f '1.sql'
四、使用HUE进行界面化管理
安装hue以及配置Mysql作为外部元数据库等参考HUE随笔!