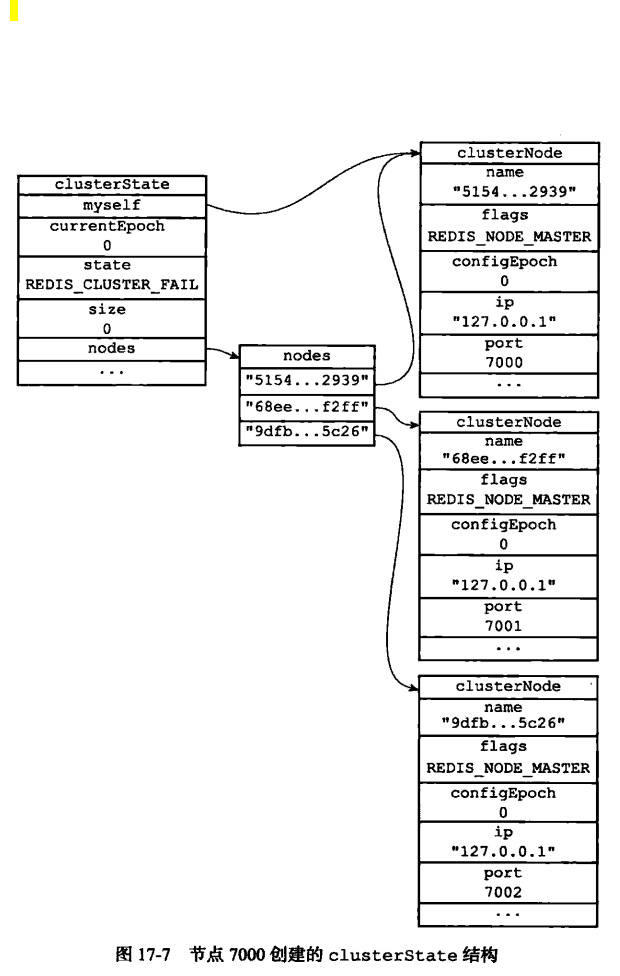
1. 一个集群会包含多个节点(一个节点就是一个reid是服务器),CLUST MEET <ip><port>可以添加一个node到集群,命令执行后,两个node之间就会进行握手,握手成功构成集群
2.节点(即redis服务器)启动时,将cluster-enable配置为YES,来决定是否开启服务器的集群模式,开启的node功能如下


3.集群数据结构



CLUSTER MEET的流程,在两个node进行了握手后,发起者NODE A会发送gossip协议消息给所有集群里的其他nodes,他们一一和NODE B进行握手,完成整个集群的配置。

4. 槽指派
所谓槽,就是对每次键值请求,对键进行散列,散列到一个槽,然后通过槽的指派,找到槽对应的那个node,就由这个node来负责处理这次请求。
REDIS有16384个槽,数据库中每个键都属于这个槽,而每个槽都要有node来处理,只有所有槽都被集群里的node处理了,集群才算上线。
下面命令是分配0-5000给指定的node
CLUSTER ADD SLOT <SLOT> [SLOT......] :cluster add slot 0 1 2 3 4 ... 5000
clusterNode结构用来记录它负责哪些槽,其中slots是一个数组,数组的一个元素占用一个字节,储存8个槽位,即每个bit代表是否管理对应的槽(1为管理),
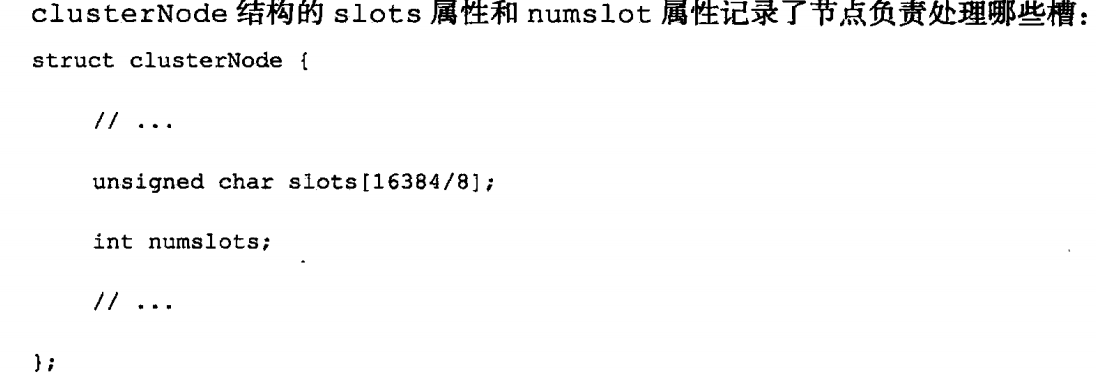
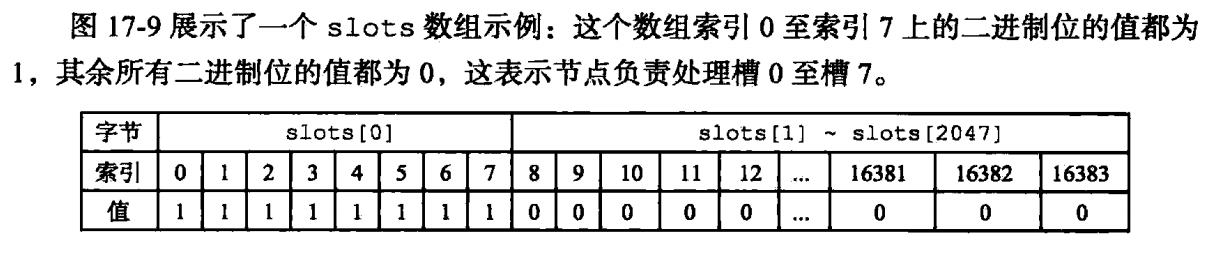
通过node找槽位:某个node配置了它所管理的槽位后,会通知集群的其他node,每个node更新自己的clusterState.node结构里的slots数组,这样在任何一个node,都能知道集群里整个slot是如何分配的,哪些node管理哪些槽位。
除了通过上面的clusterNode结构里保存一个全局的slot[]数组,在clusterState结构里也有个clusterNode *slots[16384], 存储了clusterNode的指针,表明对应的slot分配给了对应的clusterNode。
空间换时间,下面的操作复杂度都是O(1)
clusterState.slots[]负责通过slot快速找到所属于的node
clusterNode.slots[]负责通过node快速找到它所负责的所有的slots
为什么需要clusterState.slots[]


为什么需要clusterNode.slots[]:

执行CLUSTER ADDSLOTS <SLOT> [slot....]

5 在集群中执行命令
keyHashSlot()函数会将key进行散列,匹配到槽,方法简单如下:

通过散列后,得到KEY对应的slot,然后查询clusterState.slots[],找到对应的node,如果这个node是自己的node,直接处理,否则发送MOVED错误,带上发现的node的IP和port,转移到客户端,进行处理的转移。一个集群客户端通常与急群众的多个节点创建套接字连接,而所谓的节点转向实际上就是换一个套接字来发送命令。如果连接不存在,客户端先根据MOVED错误提提供的IP和port连接节点,然后进行转向。
集群节点保存键值对的方式和一般redis服务器没有区别,只是它只用0号redisDB,
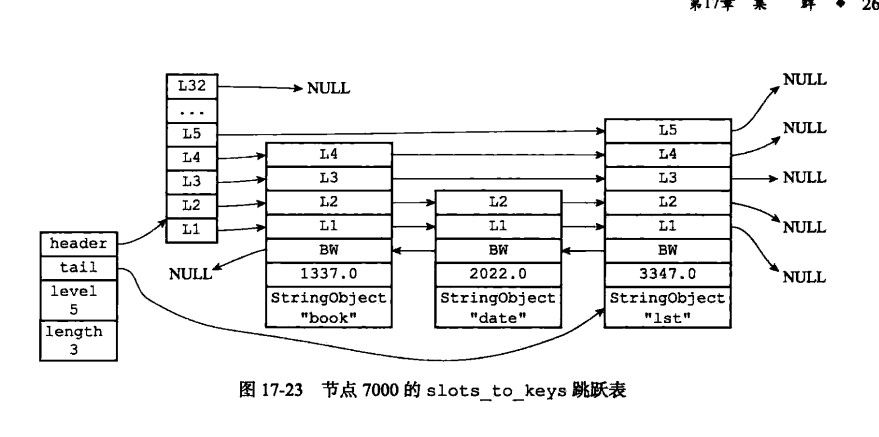
同时,clusterState会有一个slots_to_keys的跳跃表,存储了槽和key的对应关系
6 复制与故障转移
REDIS集群里的node分为master node和slave node。主节点处理槽,从节点负责从主节点复制,并在主节点下线时竞争成为主节点。
设置一个从节点: CLUSTER REPLICATE <node_id>;
- 接收到命令的节点会将clusterState.myself.slaveOf指向clusterState.nodes中的主node的地址,
- 修改clusterState.myself.flags中的属性为REIDS_NODE_SLAVE
- 然后运用和REDIS服务器的复制功能相同的方法,进行主从复制
clusterNode里有个slaves数组,如果clusterNode是主node,这个slaves里会存着它的从节点们的指针。
故障检测:
集群中每个节点都会互发ping-pong,构成心跳检测, 如果发现规定时间内没有PONG回来,就在cluster.node里,将对应的node.flags标记为PFAIL(疑似下线)。
集群中每个节点之间都会互相发消息,交换集群中各个节点的状态信息,当半数以上负责处理槽的主节点将某个主节点标记为疑似下线,那么这个节点就会被标记为FAIL(下线),然后向集群广播,集群所有node都会将其标记为下线。
故障转移:

选择哪个从节点作为主节点,选举的方法类似sentinel选举领头sentinel的方法,每个可以竞选的从节点发送请求,每个管理槽的主节点会回复第一个受到请求的node,将投票回给它,被投票超过 N/2+1票,成功当选,否则,进入下一个纪元,重新开始选举。