HTTP请求报头: Authorization
HTTP响应报头: WWW-Authenticate
HTTP认证是基于质询/回应(challenge/response)的认证模式。
HTTP认证
BASIC认证
BASIC认证概述
当一个客户端向HTTP服务器进行数据请求时,如果客户端未被认证,则HTTP服务器将通过基本认证过程对客户端的用户名及密码进行验证,以决定用户是否合法。
客户端在接收到HTTP服务器的身份认证要求后,会提示用户输入用户名及密码,然后将用户名及密码以BASE64加密,加密后的密文将附加于请求信息中, 如当用户名为anjuta,密码为:123456时,客户端将用户名和密码用“:”合并,并将合并后的字符串用BASE64加密为密文,并于每次请求数据时,将密文附加于请求头(Request Header)中。HTTP服务器在每次收到请求包后,根据协议取得客户端附加的用户信息(BASE64加密的用户名和密码),解开请求包,对用户名及密码进行验证,如果用户名及密码正确,则根据客户端请求,返回客户端所需要的数据;否则,返回错误代码或重新要求客户端提供用户名及密码。
BASIC认证的过程
基本认证步骤:
1、客户端访问一个受http基本认证保护的资源。
2、服务器返回401状态,要求客户端提供用户名和密码进行认证。(验证失败的时候,响应头会加上WWW-Authenticate: Basic realm="请求域"。)
401 Unauthorized WWW-Authenticate: Basic realm="WallyWorld"
3、客户端将输入的用户名密码用Base64进行编码后,采用非加密的明文方式传送给服务器。
Authorization: Basic xxxxxxxxxx.
4、服务器将Authorization头中的用户名密码解码并取出,进行验证,如果认证成功,则返回相应的资源。如果认证失败,则仍返回401状态,要求重新进行认证。
BASIC认证的JAVA实现代码
HttpSession session=request.getSession(); String user=(String)session.getAttribute("user"); String pass; if(user==null){ try{ response.setCharacterEncoding("GBK"); PrintWriter ut=response.getWriter(); String authorization=request.getHeader("authorization"); if(authorization==null||authorization.equals("")){ response.setStatus(401); response.setHeader("WWW-authenticate","Basic realm="请输入管理员密码""); out.print("对不起你没有权限!!"); return; } String userAndPass=new String(new BASE64Decoder().decodeBuffer(authorization.split(" ")[1])); if(userAndPass.split(":").length<2){ response.setStatus(401); response.setHeader("WWW-authenticate","Basic realm="请输入管理员密码""); out.print("对不起你没有权限!!"); return; } user=userAndPass.split(":")[0]; pass=userAndPass.split(":")[1]; if(user.equals("111")&&pass.equals("111")){ session.setAttribute("user",user); RequestDispatcher dispatcher=request.getRequestDispatcher("index.jsp"); dispatcher.forward(request,response); }else{ response.setStatus(401); response.setHeader("WWW-authenticate","Basic realm="请输入管理员密码""); out.print("对不起你没有权限!!"); return; } }catch(Exception ex){ ex.printStackTrace(); } }else{ RequestDispatcher dispatcher=request.getRequestDispatcher("index.jsp"); dispatcher.forward(request,response); }
特记事项:
1、Http是无状态的,同一个客户端对同一个realm内资源的每一个访问会被要求进行认证。
2、客户端通常会缓存用户名和密码,并和authentication realm一起保存,所以,一般不需要你重新输入用户名和密码。
3、以非加密的明文方式传输,虽然转换成了不易被人直接识别的字符串,但是无法防止用户名密码被恶意盗用。虽然用肉眼看不出来,但用程序很容易解密。
优点:
基本认证的一个优点是基本上所有流行的网页浏览器都支持基本认证。基本认证很少在可公开访问的互联网网站上使用,有时候会在小的私有系统中使用(如路由器
网页管理接口)。后来的机制HTTP摘要认证是为替代基本认证而开发的,允许密钥以相对安全的方式在不安全的通道上传输。
缺点:
-
虽然基本认证非常容易实现,但该方案建立在以下的假设的基础上,即:客户端和服务器主机之间的连接是安全可信的。特别是,如果没有使用SSL/TLS这样的传输
层安全的协议,那么以明文传输的密钥和口令很容易被拦截。该方案也同样没有对服务器返回的信息提供保护。 -
现存的浏览器保存认证信息直到标签页或浏览器被关闭,或者用户清除历史记录。HTTP没有为服务器提供一种方法指示客户端丢弃这些被缓存的密钥。这意味着服务
器端在用户不关闭浏览器的情况下,并没有一种有效的方法来让用户登出。
HTTP OAuth认证
OAuth对于Http来说,就是放在Authorization header中的不是用户名密码, 而是一个token。微软的Skydrive就是使用这样的方式。
参考:http://www.tuicool.com/articles/qqeuE3
摘要认证
digest authentication(HTTP1.1提出的基本认证的替代方法)
这个认证可以看做是基本认证的增强版本,不包含密码的明文传递。
引入了一系列安全增强的选项;“保护质量”(qop)、随机数计数器由客户端增加、以及客户生成的随机数。
在HTTP摘要认证中使用 MD5 加密是为了达成"不可逆的",也就是说,当输出已知的时候,确定原始的输入应该是相当困难的。如果密码本身太过简单,也许可以
通过尝试所有可能的输入来找到对应的输出(穷举攻击),甚至可以通过字典或者适当的查找表加快查找速度。
示例及说明
下面的例子仅仅涵盖了“auth”保护质量的代码,因为在撰写期间,所知道的只有Opera和Konqueror网页浏览器支持“auth-int”(带完整性保护的认证)。
典型的认证过程包括如下步骤:
客户端请求一个需要认证的页面,但是不提供用户名和密码。通常这是由于用户简单的输入了一个地址或者在页面中点击了某个超链接。
服务器返回401 "Unauthorized" 响应代码,并提供认证域(realm),以及一个随机生成的、只使用一次的数值,称为密码随机数 nonce。
此时,浏览器会向用户提示认证域(realm)(通常是所访问的计算机或系统的描述),并且提示用户名和密码。用户此时可以选择取消。
一旦提供了用户名和密码,客户端会重新发送同样的请求,但是添加了一个认证头包括了响应代码。
注意:客户端可能已经拥有了用户名和密码,因此不需要提示用户,比如以前存储在浏览器里的。
客户端请求 (无认证):
GET /dir/index.html HTTP/1.0 Host: localhost (跟随一个新行,形式为一个回车再跟一个换行)
服务器响应:
HTTP/1.0 401 Unauthorized Server: HTTPd/0.9 Date: Sun, 10 Apr 2005 20:26:47 GMT WWW-Authenticate: Digest realm="testrealm@host.com", //认证域 qop="auth,auth-int", //保护质量 nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093", //服务器密码随机数 opaque="5ccc069c403ebaf9f0171e9517f40e41" Content-Type: text/html Content-Length: 311 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/1999/REC-html401-19991224/loose.dtd"> <HTML> <HEAD> <TITLE>Error</TITLE> <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=ISO-8859-1"> </HEAD> <BODY><H1>401 Unauthorized.</H1></BODY> </HTML>
客户端请求 (用户名 "Mufasa", 密码 "Circle Of Life"):
GET /dir/index.html HTTP/1.0 Host: localhost Authorization: Digest username="Mufasa", realm="testrealm@host.com", nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093", uri="/dir/index.html", qop=auth, nc=00000001,//请求计数 cnonce="0a4f113b", //客户端密码随机数 response="6629fae49393a05397450978507c4ef1", opaque="5ccc069c403ebaf9f0171e9517f40e41" (跟随一个新行,形式如前所述)。
服务器响应:
HTTP/1.0 200 OK Server: HTTPd/0.9 Date: Sun, 10 Apr 2005 20:27:03 GMT Content-Type: text/html Content-Length: 7984 (随后是一个空行,然后是所请求受限制的HTML页面)
response 值由三步计算而成。当多个数值合并的时候,使用冒号作为分割符:
1、对用户名、认证域(realm)以及密码的合并值计算 MD5 哈希值,结果称为 HA1。
2、对HTTP方法以及URI的摘要的合并值计算 MD5 哈希值,例如,"GET" 和 "/dir/index.html",结果称为 HA2。
3、对HA1、服务器密码随机数(nonce)、请求计数(nc)、客户端密码随机数(cnonce)、保护质量(qop)以及 HA2 的合并值计算 MD5 哈希值。结果即为客户端提供的
response 值。
因为服务器拥有与客户端同样的信息,因此服务器可以进行同样的计算,以验证客户端提交的 response 值的正确性。在上面给出的例子中,结果是如下计算的。
(MD5()表示用于计算MD5哈希值的函数;“”表示接下一行;引号并不参与计算)
HA1 = MD5( "Mufasa:testrealm@host.com:Circle Of Life" ) = 939e7578ed9e3c518a452acee763bce9 HA2 = MD5( "GET:/dir/index.html" ) = 39aff3a2bab6126f332b942af96d3366 Response = MD5( "939e7578ed9e3c518a452acee763bce9: dcd98b7102dd2f0e8b11d0f600bfb0c093: 00000001:0a4f113b:auth: 39aff3a2bab6126f332b942af96d3366" ) = 6629fae49393a05397450978507c4ef1
此时客户端可以提交一个新的请求,重复使用服务器密码随机数(nonce)(服务器仅在每次“401”响应后发行新的nonce),但是提供新的客户端密码随机数(cnonce)。在后续的请求中,十六进制请求计数器(nc)必须比前一次使用的时候要大,否则攻击者可以简单的使用同样的认证信息重放老的请求。由服务器来确保在每个发出的密码随机数nonce时,计数器是在增加的,并拒绝掉任何错误的请求。显然,改变HTTP方法和/或计数器数值都会导致不同的 response值。
服务器应当记住最近所生成的服务器密码随机数nonce的值。也可以在发行每一个密码随机数nonce后,记住过一段时间让它们过期。如果客户端使用了一个过期的值,服务器应该响应“401”状态号,并且在认证头中添加stale=TRUE,表明客户端应当使用新提供的服务器密码随机数nonce重发请求,而不必提示用户其它用户名和口令。
Cookie Auth
Cookie认证机制:用户输入用户名和密码发起请求,服务器认证后给每个Session分配一个唯一的JSESSIONID,并通过Cookie发送给客户端。
当客户端发起新的请求的时候,将在Cookie头中携带这个JSESSIONID。这样服务器能够找到这个客户端对应的Session。默认的,当我们关闭浏览器的时候,客户端cookie会被删除,可以通过修改cookie 的expire time使cookie在一定时间内有效。但是服务器端的session不会被销毁,除非通过invalidate或超时。
Token Auth
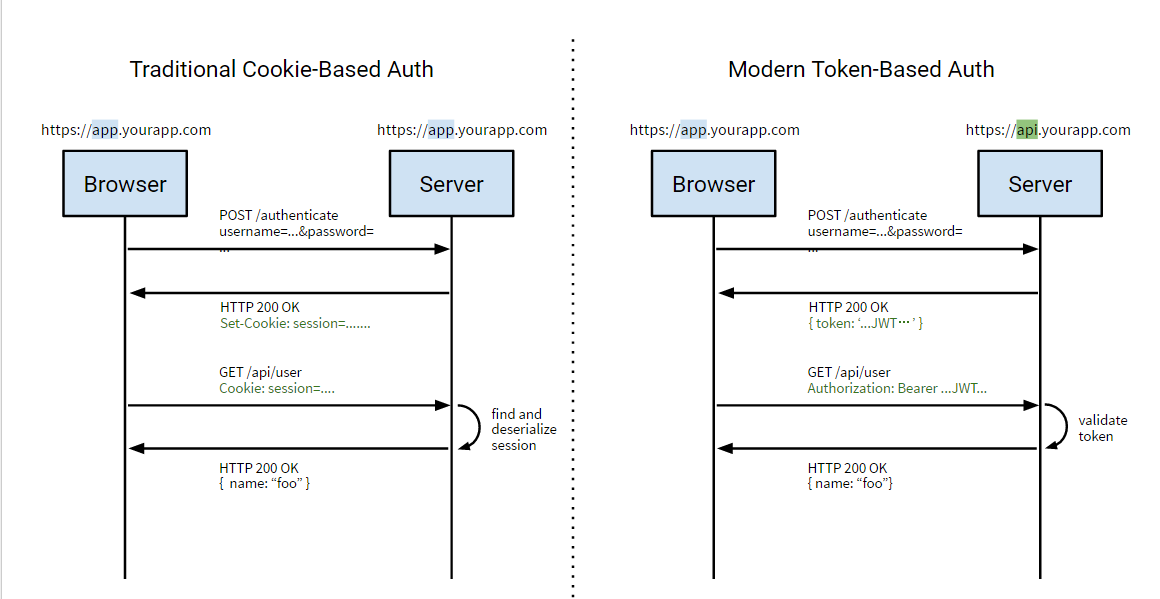
常用的Token Auth(和Cookie Auth区别不大):
- 首次登陆,用户名和密码验证过之后,将sessionId保存在token中,或者将一个key保存在token中,key的值可以设置为用户唯一性的信息(账号/密码/身份认证机制(电话号/身份证号/支付宝账号/银行卡信息)...);当然我们在程序中的实现是保存UUID作为ticket。
- 设置token的有效期,并保存在服务器数据库中;
- 服务器将这个token值返回给客户端,客户端拿到 token 值之后,将 token 保存在 cookie 中,以后客户端再次发送网络请求(一般不是登录请求)的时候,就会将这个 token 值附带到参数中发送给服务器。服务器接收到客户端的请求之后,会取出token值与保存在本地(数据库)中的token值做对比!
如果两个 token 值相同 :说明用户登录成功过!当前用户处于登录状态!如果没有这个token或者过期,则设置token为无效,并让用户重新登录。
这种方式在客户端变化不大,也要利用cookie,改动的是服务器端
过去:通过sessionId查找Tomcat服务器内存中是否有sessionId对应的session存在,若存在,则表示登陆过,然后从session找出用户信息;
现在:通过token查找数据库中是否有相同的token,并且token要处于有效期前,有的话通过token在数据库中找出用户信息,否则重新登录,(其实还包括sessionId的验证,因为jsp默认创建session)。
如果觉得查询数据库比较耗时,可以用memcache或者redis缓存一下。
首先说明一下session何时会被创建:
- 1、 请求JSP页面时自动创建session,利用request.getSession(true);语句
原因:
由于HTTP是无状态协议,这意味着每次客户端检索网页时,都要单独打开一个服务器http连接,如果我同一个浏览器,不同页面打开你的主页10次,那就要进行10次连接和断开(TCP3次握手,4次挥手),浪费系统资源,http提供了一种长连接,keep-alive,相同会话的不同请求可以用同一连接,故jsp默认创建session。而session的创建过程中会自动将sessionId写入cookie的JSESSIONID中的,这样,只要不关闭浏览器,你在同一网站的任意网页跳转,由于每次请求都会携带同一个sessionId,不会重新创建新的会话,防止创建多个会话浪费系统资源。
否则:黑客利用几台主机,疯狂的点击某一个JSP页面,如果每次点击都创建一个新的会话,可能使服务器崩溃。
例子:
登录函数:
// 用户登录操作 public void login(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("gb2312"); String account = request.getParameter("account"); consumerDao = new ConsumerDao(); ConsumerForm consumerForm = consumerDao.getConsumerForm(account); if (consumerForm == null) { request.setAttribute("information", "您输入的用户名不存在,请重新输入!"); } else if (!consumerForm.getPassword().equals(request.getParameter("password"))) { request.setAttribute("information", "您输入的登录密码有误,请重新输入!"); } else { request.setAttribute("form", consumerForm); } RequestDispatcher requestDispatcher = request.getRequestDispatcher("dealwith.jsp"); requestDispatcher.forward(request, response); }
登录主页:
<body onselectstart="return false"> <table width="800" height="496" border="0" align="center" cellpadding="0" cellspacing="0" background="images/login.jpg"> <tr> <td valign="top"> <table width="658" border="0"> <tr> <td colspan="2"> </td> </tr> <tr> <td width="92" height="358"> </td> <td width="550" valign="bottom"> <form name="form1" method="post" action="ConsumerServlet?method=0&sign=0" onSubmit="return userCheck()"> <table width="291" border="0" align="center" cellpadding="0" cellspacing="0"> <tr> <td width="66" height="30">用户名:</td> <td width="225"><input name="account" type="text" class="inputinput" id="account" size="30"></td> </tr> <tr> <td height="30">密 码:</td> <td><input name="password" type="password" class="inputinput" id="password" size="30"></td> </tr> <tr> <td height="30" colspan="2" align="center"><input type="image" class="inputinputinput" src="images/land.gif"> <a href="#" onClick="javascript:document.form1.reset()"><img src="images/reset.gif"></a> <a href="consumer/accountAdd.jsp"><img src="images/register.gif"></a></td> </tr> </table> </form> </td> </tr> </table> </td> </tr> </table> </body>
其中并没有利用session的语句,但是主界面,当还没有登录时: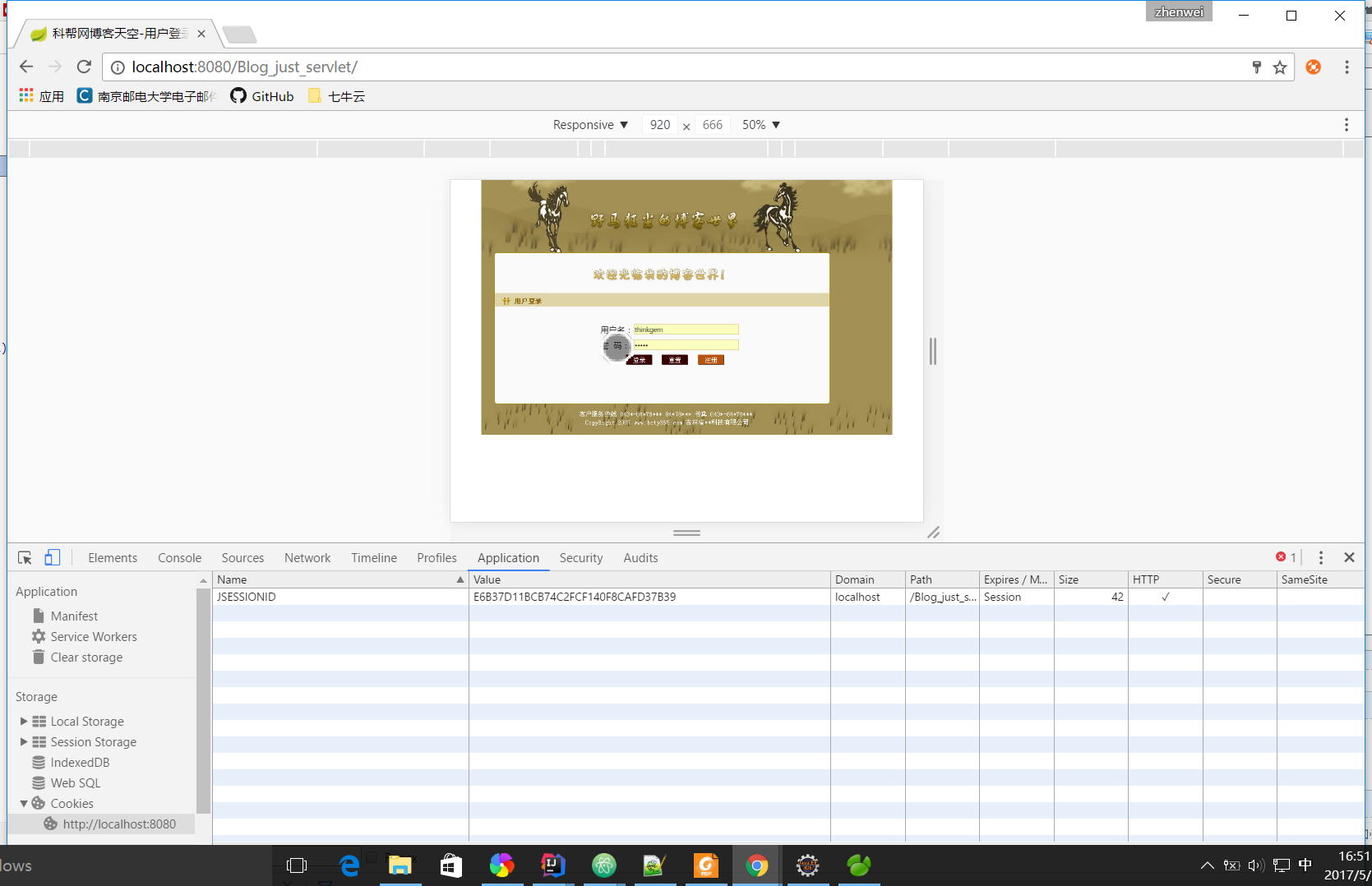
可见有一个JSESSIONID,并且点击其他页面并没有开启新的JSESSIONID。但是换一个浏览器就会产生新的JSESSIONID,因为不同浏览器的会话缓存是不可以互相用的
登录以后还是这个JSESSIONID: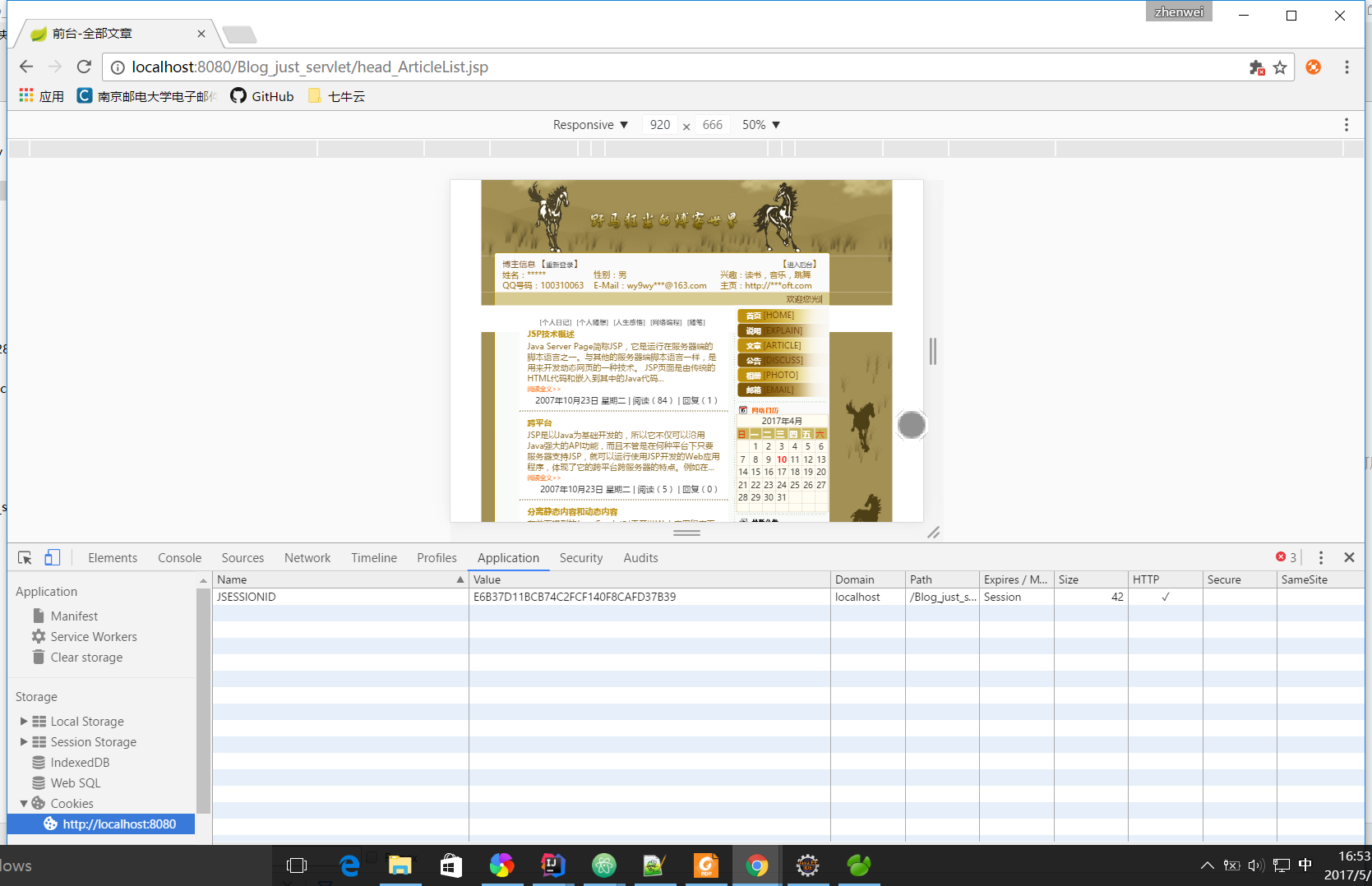
Session的销毁只有三种方式:
1.调用了session.invalidate()方法
2.session过期(超时)
3.服务器重新启动
单个JSP页面禁用session方式
<%@ page session="false">- 在servlet中,只要代码不调用Session相关的API就不会创建session
request.getSession() 等价于 request.getSession(true)
这两个方法的作用是相同的,查找请求中是否有关联的JSESSIONID,如果有则返回这个号码所对应的session对象,如果没有则生成一个新的session对象。所以说,通过此方法是一定可以获得一个session对象。
request.getSession(false) 查找请求中是否有关联的JSESSIONID号,如果有则返回这个号码所对应的session对象,如果没有则返回一个null。
注意在创建session的过程中,sessionId是自动写入cookie的JSESSIONID中的,如果禁用cookie,则通过url回传
参考的头条项目: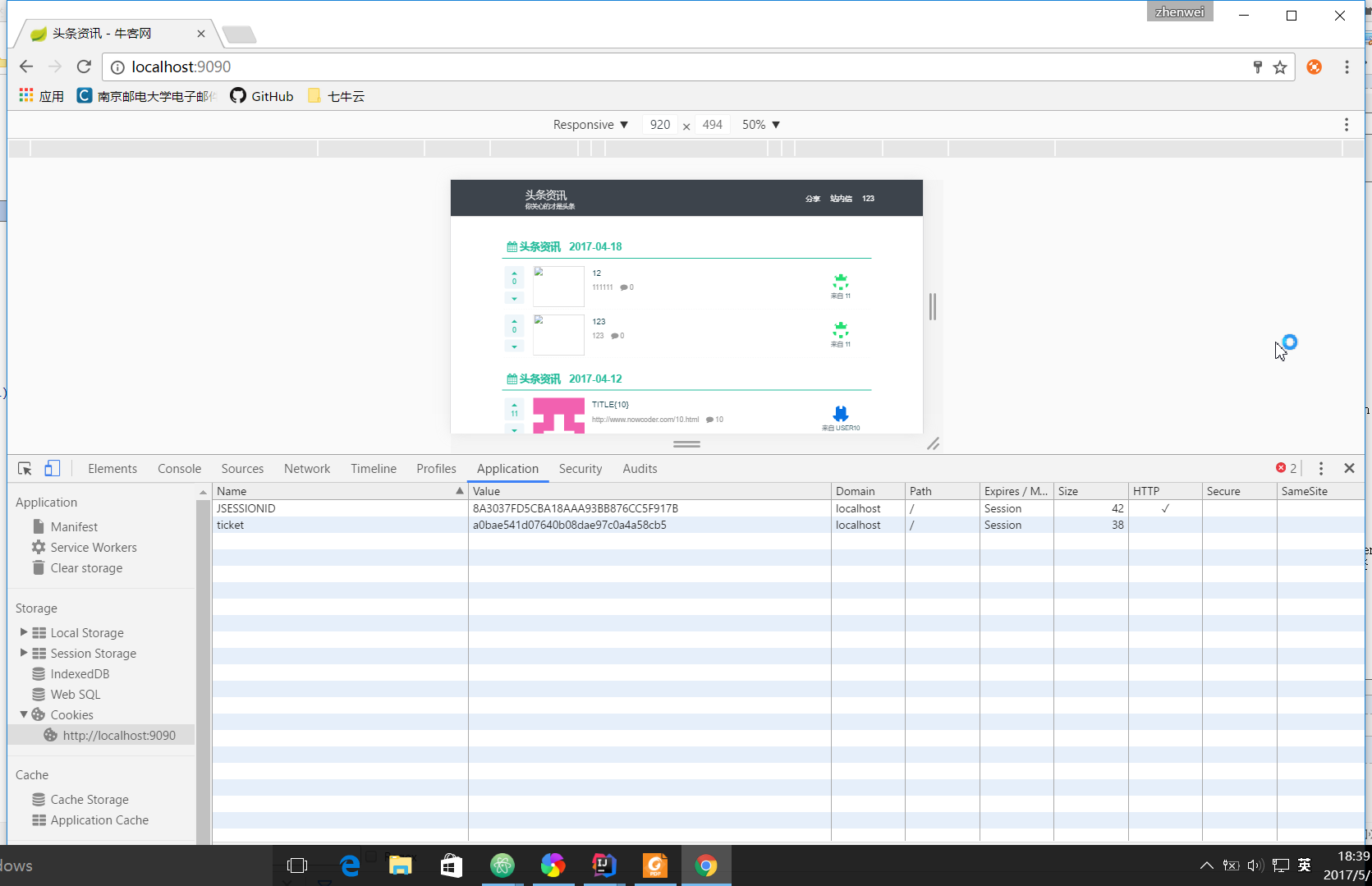
JSESSIONID和token(即ticket)同时存在,尽量不往session里放东西,将用户主键,过期时间等都存到和ticket一起的表中,优点:1.减少内存占用;2.Tomcat默认30分钟session销毁,采用token可以长时间保持登录状态,但可能就不是这一个session了;3.除了JSESSIONID验证一致性,增加一个token验证,防止黑客暴力破解JSESSIONID,但黑客可以获得JSESSIONID,估计获得token也不难,只是会麻烦一点。
牛客网: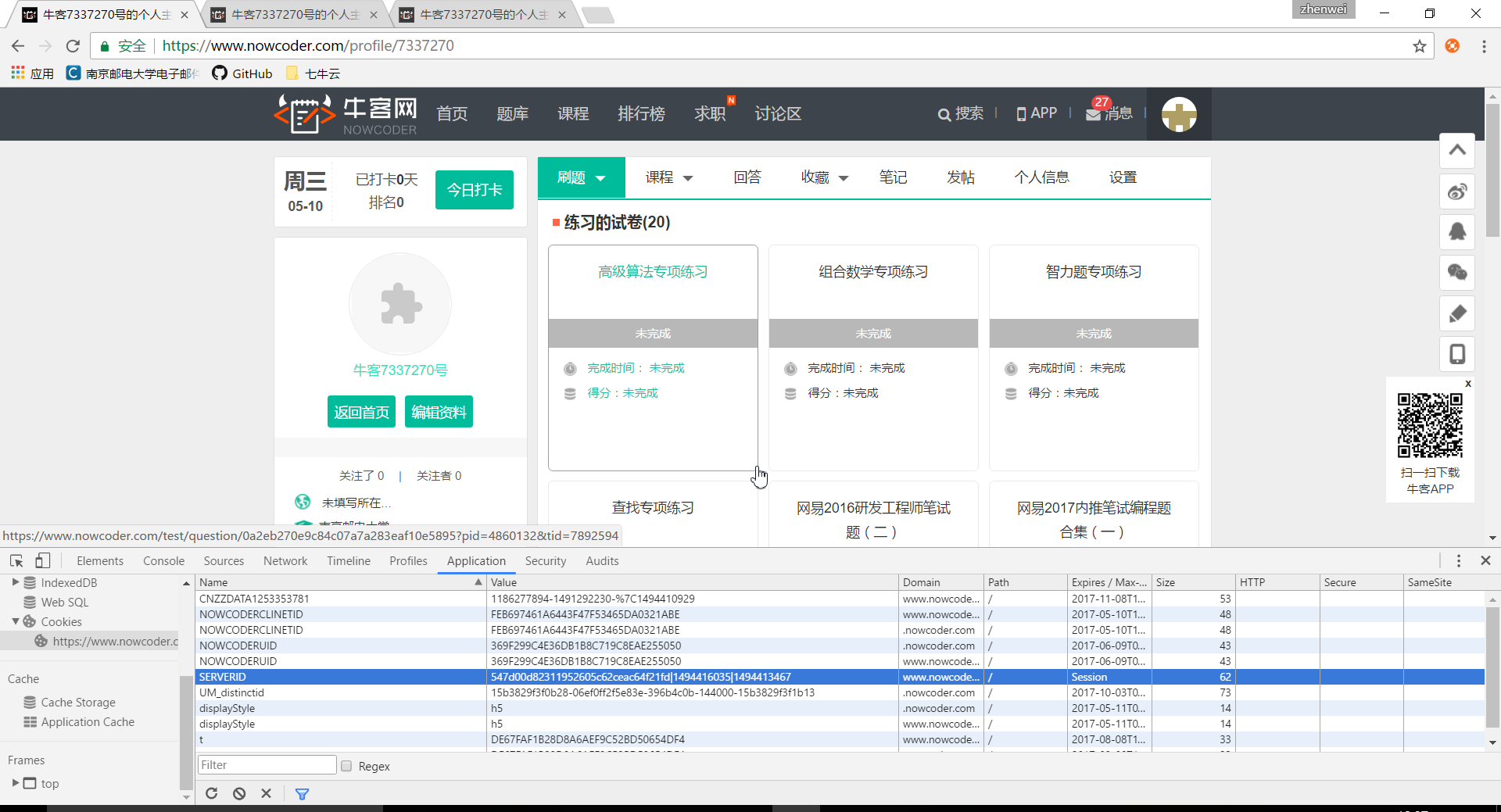
淘宝网: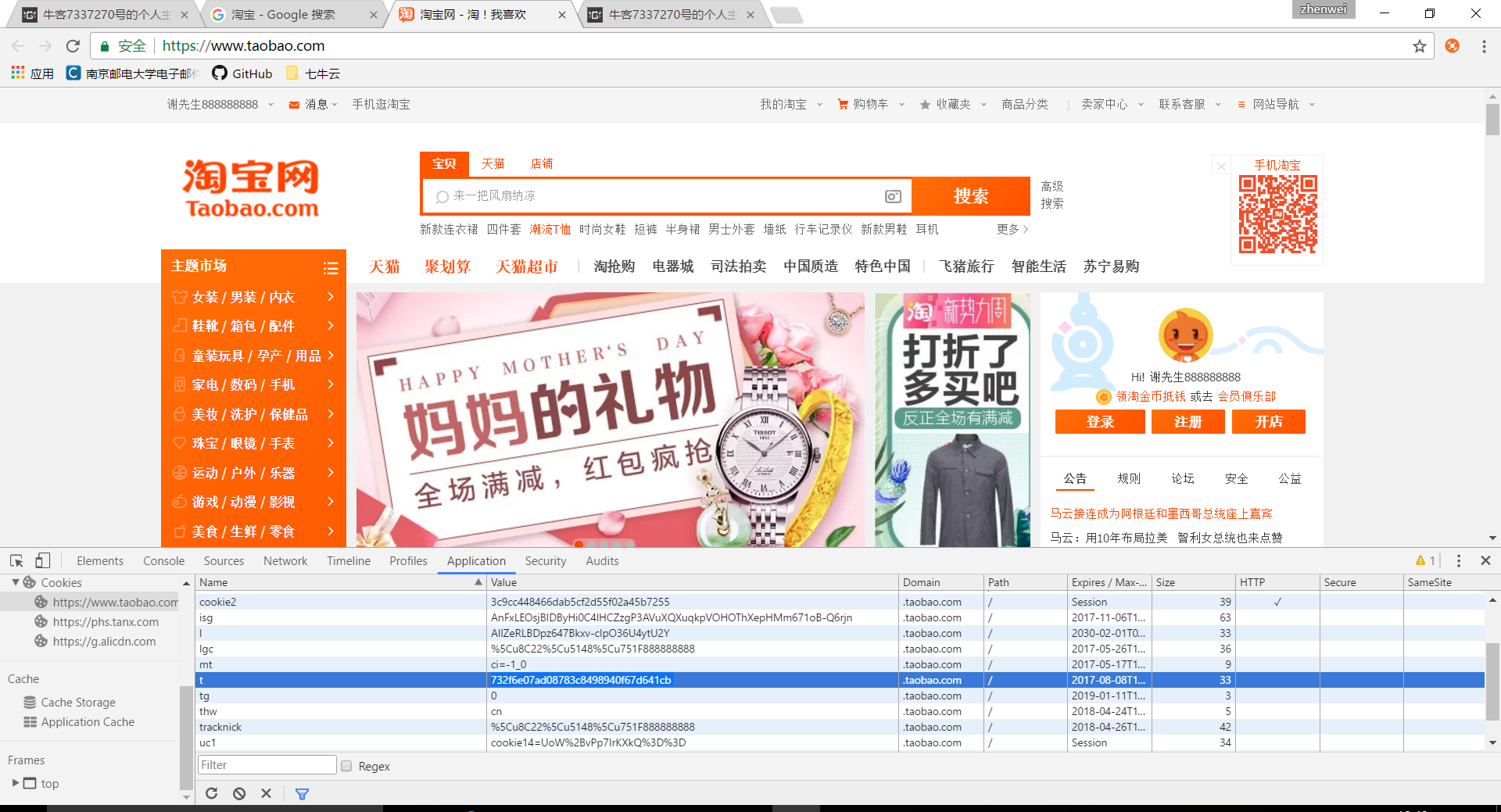
都用了token和session(NOWCODERCLINETID和cookie2,这个只是猜测),只是不是直接保存JSESSIONID,改名字了,如果攻击者不分析站点,就不能猜到Session名称,阻挡部分攻击。
真正的应用:JWT
通过token可以将用户的基本信息(非隐私的,比如UserId,过期时间,生成的随机key等)全部加密签名后放入token中,从而服务器端不需要保存用户登录信息,大大减轻服务器压力。用户认证完全靠token识别,通过签名来保证token没有被修改过(只有服务器才知道秘钥,比如常见的非对称加密算法),是服务器下发的token。在后续请求中,服务端只需要对用户请求中包含的token进行解码,验证用户登录是否过期。
很多大型网站也都在用,比如 Facebook,Twitter,Google+,Github 等等,比起传统的身份验证方法,Token 扩展性更强,也更安全点,非常适合用在 Web 应用或者移动应用上。
Token Auth优点:
- 减轻服务器压力:通过token可以将用户的基本信息(非隐私的,比如UserId,过期时间,生成的随机key等)全部加密签名后放入token中,从而服务器端不需要保存用户登录信息,大大减轻服务器压力。用户认证完全靠token识别,通过签名来保证token没有被修改过(只有服务器才知道秘钥,比如常见的非对称加密算法),是服务器下发的token。
- 支持跨域访问:因为服务器并没有保存登录状态,完全靠签名的token识别,那么另一个网站只要有对应的私钥,就可以对token验证,前提是传输的用户认证信息通过HTTP头传输;
- 更适用CDN: 可以通过内容分发网络请求你服务端的所有资料(如:javascript,HTML,图片等),因为不需要同步服务器上的登录状态信息;
- 性能更好: 因为从token中可以获得userId,不用查询登录状态表;
但是都不能很好的预防会话劫持
什么是Realm
Tomcat提供Realm支持。
Tomcat使用Realm使某些特定的用户组具有访问某些特定的Web应用的权限,而没有权限的用户不能访问这个应用。
Tomcat提供了三种不同Realm对访问某个Web应用程序的用户进行相应的验证。
1、JDBCRealm,这个Realm将用户信息存在数据库里,通过JDBC从数据库中获得用户信息并进行验证。
2、JNDIRealm,将用户信息存在基于LDAP等目录服务的服务器里,通过JNDI技术从LDAP服务器中获取用户信息并进行验证。
3、MemoryRealm,将用户信息存在一个xml文件中,对用户进行验证时,将会从相应的xml文件中提取用户信息。manager(Tomcat提供的一个web应用程序)应用在进行验证时即使用此种Realm。Realm类似于Unix里面的group。在Unix中,一个group对应着系统的一定资源,某个group不能访问不属于它的资源。Tomcat用Realm来对不同的应用(类似系统资源)赋给不同的用户(类似group)。没有权限的用户则不能访问这个应用。
HTTPS传输协议原理
HTTPS(HTTP over SSL,实际上是在原有的 HTTP 数据外面加了一层 SSL 的封装。HTTP 协议原有的 GET、POST 之类的机制,基本上原封不动),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容请看SSL。
两种基本的加解密算法类型
- 对称加密:密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES等。
- 非对称加密:密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。
HTTPS通信过程
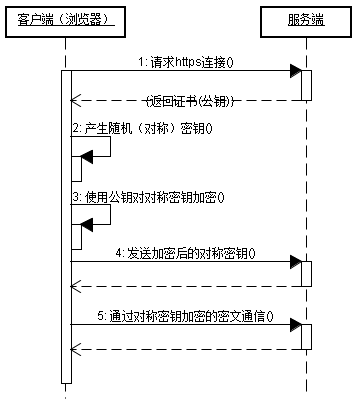
HTTPS通信的优点
客户端产生的密钥只有客户端和服务器端能得到;
加密的数据只有客户端和服务器端才能得到明文;
客户端到服务端的通信是安全的。
SSL/TLS协议
SSL/TLS协议希望达到:
(1) 所有信息都是加密传播,第三方无法窃听。
(2) 具有校验机制,一旦被篡改,通信双方会立刻发现。
(3) 配备身份证书,防止身份被冒充。
历史
1994年,NetScape公司设计了SSL协议(Secure Sockets Layer)的1.0版,但是未发布。
1995年,NetScape公司发布SSL 2.0版,很快发现有严重漏洞。
1996年,SSL 3.0版问世,得到大规模应用。
1999年,互联网标准化组织ISOC接替NetScape公司,发布了SSL的升级版TLS 1.0版。
2006年和2008年,TLS进行了两次升级,分别为TLS 1.1版和TLS 1.2版。最新的变动是2011年TLS 1.2的修订版。
目前,应用最广泛的是TLS 1.0,接下来是SSL 3.0。但是,主流浏览器都已经实现了TLS 1.2的支持。
TLS 1.0通常被标示为SSL 3.1,TLS 1.1为SSL 3.2,TLS 1.2为SSL 3.3。
基本的运行过程
SSL/TLS协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
如何保证公钥不被篡改?
解决方法:将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。
公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个"对话密钥"(session key),用它来加密信息。由于"对话密钥"是对称加密,所以运算速度非常快,而服务器公钥只用于加密"对话密钥"本身,这样就减少了加密运算的消耗时间。即在客户端与服务器间传输的数据是通过使用对称算法(如 DES 或 RC4)进行加密的。
因此,SSL/TLS协议的基本过程是这样的:
(1) 客户端向服务器端索要并验证公钥。
(2) 双方协商生成"对话密钥"。
(3) 双方采用"对话密钥"进行加密通信。
上面过程的前两步,又称为"握手阶段"(handshake)。
握手阶段的详细过程
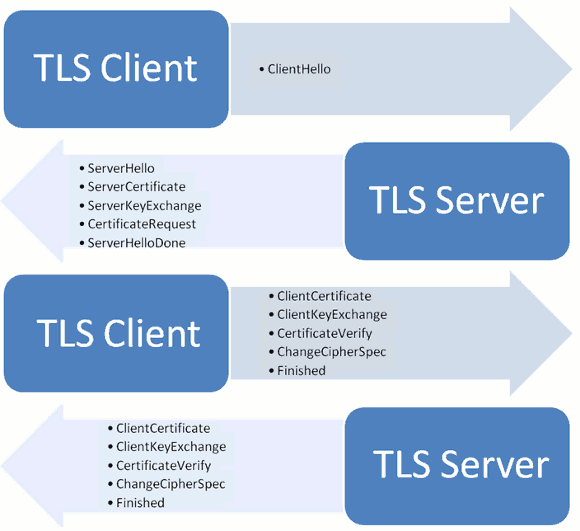
"握手阶段"涉及四次通信,我们一个个来看。
1 客户端发出请求(ClientHello)
首先,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求。
在这一步,客户端主要向服务器提供以下信息。
(1) 支持的协议版本,比如TLS 1.0版。
(2) 一个客户端生成的随机数,稍后用于生成"对话密钥"。
(3) 支持的加密方法,比如RSA公钥加密。
(4) 支持的压缩方法。
这里需要注意的是,客户端发送的信息之中不包括服务器的域名。也就是说,理论上服务器只能包含一个网站,否则会分不清应该向客户端提供哪一个网站的数字证书。这就是为什么通常一台服务器只能有一张数字证书的原因。
对于虚拟主机的用户来说,这当然很不方便。2006年,TLS协议加入了一个Server Name Indication扩展,允许客户端向服务器提供它所请求的域名。
2 服务器回应(SeverHello)
服务器收到客户端请求后,向客户端发出回应,这叫做SeverHello。服务器的回应包含以下内容。
(1) 确认使用的加密通信协议版本,比如TLS 1.0版本。如果浏览器与服务器支持的版本不一致,服务器关闭加密通信。
(2) 一个服务器生成的随机数,稍后用于生成"对话密钥"。
(3) 确认使用的加密方法,比如RSA公钥加密。
(4) 服务器证书。
除了上面这些信息,如果服务器需要确认客户端的身份,就会再包含一项请求,要求客户端提供"客户端证书"。比如,金融机构往往只允许认证客户连入自己的网络,就会向正式客户提供USB密钥,里面就包含了一张客户端证书。
3 客户端回应
客户端收到服务器回应以后,首先验证服务器证书。如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。
如果证书没有问题,客户端就会从证书中取出服务器的公钥。然后,向服务器发送下面三项信息。
(1) 一个随机数。该随机数用服务器公钥加密,防止被窃听。
(2) 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
(3) 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供服务器校验。
上面第一项的随机数,是整个握手阶段出现的第三个随机数,又称"pre-master key"。有了它以后,客户端和服务器就同时有了三个随机数,接着双方就用事先商定的加密方法,各自生成本次会话所用的同一把"会话密钥"。
至于为什么一定要用三个随机数,来生成"会话密钥":
"不管是客户端还是服务器,都需要随机数,这样生成的密钥才不会每次都一样。由于SSL协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。
对于RSA密钥交换算法来说,pre-master-key本身就是一个随机数,再加上hello消息中的随机,三个随机数通过一个密钥导出器最终导出一个对称密钥。
pre master的存在在于SSL协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么pre master secret就有可能被猜出来,那么仅适用pre master secret作为密钥就不合适了,因此必须引入新的随机因素,那么客户端和服务器加上pre master secret三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了,每增加一个自由度,随机性增加的可不是一。"
此外,如果前一步,服务器要求客户端证书,客户端会在这一步发送证书及相关信息。
4 服务器的最后回应
服务器收到客户端的第三个随机数pre-master key之后,计算生成本次会话所用的"会话密钥"。然后,向客户端最后发送下面信息。
(1)编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。
至此,整个握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用"会话密钥"加密内容。
非对称加密
需要一对密钥,一个是私人密钥,另一个则是公开密钥。这两个密钥是数学相关,用某用户密钥加密后所得的信息,只能用该用户的解密密钥才能解密。如果知道了其中一个,并不能计算出另外一个。因此如果公开了一对密钥中的一个,并不会危害到另外一个的秘密性质。称公开的密钥为公钥;不公开的密钥为私钥。
如果加密密钥是公开的,这用于客户给私钥所有者上传加密的数据,这被称作为公开密钥加密(狭义)。例如,网络银行的客户发给银行网站的操作信息的加密数据,采用公钥加密。
如果解密密钥是公开的,用私钥加密的信息,可以用公钥对其解密,用于客户验证持有私钥一方发布的数据或文件是完整准确的,接收者由此可知这条信息确实来自于拥有私钥的某人,这被称作数字签名,公钥的形式就是数字证书。
每个人都有一对“钥匙”(数字身份),其中一个只有她/他本人知道(私钥),另一个公开的(公钥)。签名的时候用私钥,验证签名的时候用公钥。又因为任何人都可以落款申称她/他就是使用者本人,因此公钥必须向接受者信任的人(身份认证机构)来注册。注册后身份认证机构给使用者发一数字证书。对文件签名后,使用者把此数字证书连同文件及签名一起发给接受者,接受者向身份认证机构求证是否真地是用使用者的密钥签发的文件。
在中国,数字签名是具法律效力的,正在被普遍使用。
使用最广泛的是RSA算法
RSA算法原理
1977年,三位数学家Rivest、Shamir 和 Adleman 设计了一种算法,可以实现非对称加密。这种算法用他们三个人的名字命名,叫做RSA算法。
这种算法非常可靠,密钥越长,它就越难破解。根据已经披露的文献,目前被破解的最长RSA密钥是768个二进制位。也就是说,长度超过768位的密钥,还无法破解(至少没人公开宣布)。因此可以认为,1024位的RSA密钥基本安全,2048位的密钥极其安全。
"对极大整数做因数分解的难度决定了RSA算法的可靠性。换言之,对一极大整数做因数分解愈困难,RSA算法愈可靠。
假如有人找到一种快速因数分解的算法,那么RSA的可靠性就会极度下降。但找到这样的算法的可能性是非常小的。今天只有短的RSA密钥才可能被暴力破解。到2008年为止,世界上还没有任何可靠的攻击RSA算法的方式。
只要密钥长度足够长,用RSA加密的信息实际上是不能被解破的。"
RSA性能是非常低的,原因在于寻找大素数、大数计算、数据分割需要耗费很多的CPU周期,所以一般的HTTPS连接只在握手时使用非对称加密,通过握手交换对称加密密钥(其实只有第三次通信,客户端向服务器发送随机数时用公钥加密),在之后的通信走对称加密。
互质关系
如果两个正整数,除了1以外,没有其他公因子,我们就称这两个数是互质关系(coprime)。比如,15和32没有公因子,所以它们是互质关系。这说明,不是质数也可以构成互质关系。
关于互质关系,不难得到以下结论:
1. 任意两个质数构成互质关系,比如13和61。
2. 一个数是质数,另一个数只要不是前者的倍数,两者就构成互质关系,比如3和10。
3. 如果两个数之中,较大的那个数是质数,则两者构成互质关系,比如97和57。
4. 1和任意一个自然数是都是互质关系,比如1和99。
5. p是大于1的整数,则p和p-1构成互质关系,比如57和56。
6. p是大于1的奇数,则p和p-2构成互质关系,比如17和15。
欧拉函数
任意给定正整数n,请问在小于等于n的正整数之中,有多少个与n构成互质关系?(比如,在1到8之中,有多少个数与8构成互质关系?)
计算这个值的方法就叫做欧拉函数,以φ(n)表示。在1到8之中,与8形成互质关系的是1、3、5、7,所以 φ(n) = 4。
因为任意一个大于1的正整数,都可以写成一系列质数的积。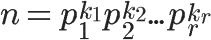
欧拉函数的通用计算公式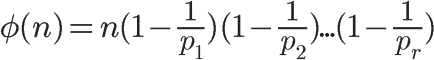
欧拉定理
模反元素
详细看:
http://www.ruanyifeng.com/blog/2013/06/rsa_algorithm_part_one.html
密钥生成的步骤
假设爱丽丝要与鲍勃进行加密通信,她该怎么生成公钥和私钥呢?
第一步,随机选择两个不相等的质数p和q。
爱丽丝选择了61和53。(实际应用中,这两个质数越大,就越难破解。)
第二步,计算p和q的乘积n。
爱丽丝就把61和53相乘。
n = 61×53 = 3233
n的长度就是密钥长度。3233写成二进制是110010100001,一共有12位,所以这个密钥就是12位。实际应用中,RSA密钥一般是1024位,重要场合则为2048位。
第三步,计算n的欧拉函数φ(n)。
根据公式:
φ(n) = (p-1)(q-1)
爱丽丝算出φ(3233)等于60×52,即3120。
第四步,随机选择一个整数e,条件是1< e < φ(n),且e与φ(n) 互质。
爱丽丝就在1到3120之间,随机选择了17。(实际应用中,常常选择65537。)
第五步,计算e对于φ(n)的模反元素d。
所谓"模反元素"就是指有一个整数d,可以使得ed被φ(n)除的余数为1。
ed ≡ 1 (mod φ(n))
这个式子等价于
ed - 1 = kφ(n)
于是,找到模反元素d,实质上就是对下面这个二元一次方程求解。
ex + φ(n)y = 1
已知 e=17, φ(n)=3120,
17x + 3120y = 1
这个方程可以用"扩展欧几里得算法"求解,此处省略具体过程。总之,爱丽丝算出一组整数解为 (x,y)=(2753,-15),即 d=2753。
至此所有计算完成。
第六步,将n和e封装成公钥,n和d封装成私钥。
在爱丽丝的例子中,n=3233,e=17,d=2753,所以公钥就是 (3233,17),私钥就是(3233, 2753)。
实际应用中,公钥和私钥的数据都采用ASN.1格式表达(实例)。
结论:如果n可以被因数分解,d就可以算出,也就意味着私钥被破解。
大整数的因数分解,是一件非常困难的事情。目前,除了暴力破解,还没有发现别的有效方法。
详细看:
http://www.ruanyifeng.com/blog/2013/07/rsa_algorithm_part_two.html
误区
HTTPS无法缓存
在大家的观念里,出于安全考虑,浏览器不会在本地保存HTTPS缓存。 实际上, 只要在HTTP头中使用特定命令,HTTPS是可以缓存的。
Microsoft 项目经理Eric Lawrence 写道:
比如,如果头命令是Cache-Control:max-age=600,那么HTTPS的网页就将被IE缓存10分钟,IE的缓存策略与是否使用HTTPS协议无线。其它浏览器也有类似的操作方法。
Firefox默认只在内存中缓存HTTPS。但是,只要头命令中有Cache-Control:Public,缓存就会被写到硬盘上。下面的图片显示,Firefox的硬盘缓存中有HTTPS内容,头命令正是Cache-Control:Public。
有了HTTPS,Cookie和查询字符串就安全了
虽然无法直接从HTTPS数据中读取Cookie和查询字符串,但是你仍然需要使它们的值变得难以预测。
比如,曾经有一家英国银行,直接使用顺序排列的数值表示session id:
黑客可以先注册一个账户,找到这个cookie,看到这个值的表示方法。然后,改动cookie,从而劫持其他人的session id。至于查询字符串,也可以通过类似方式泄漏。