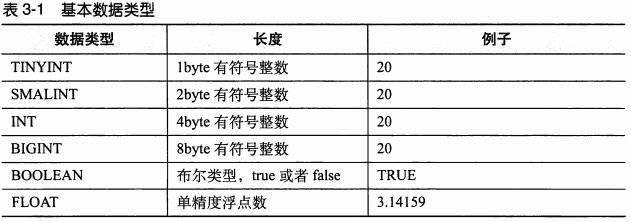
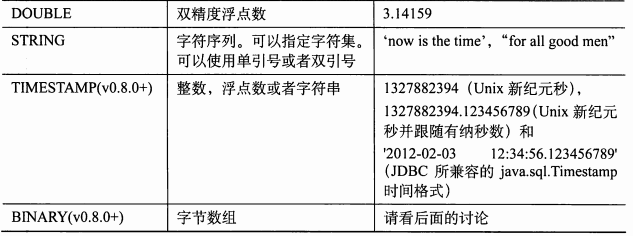
基本数据类型
(常用的两种建表例子)
查看所有函数
SHOW FUNCTIONS;
搜索函数
[erp@master2-dev ~]$ hive -S -e "SHOW FUNCTIONS" | grep time
from_unixtime
from_utc_timestamp
to_unix_timestamp
to_utc_timestamp
unix_timestamp
[erp@master2-dev ~]$ hive -S -e "SHOW FUNCTIONS" | grep date
date_add
date_sub
datediff
finance.getdate
to_date
搜索表
SHOW TABLES;
SHOW TABLES '*534';
查看函数使用方法
DESCRIBE FUNCTION EXTENDED concat;
关键字补全
命令行中的Tab:列出所有关键字及补全。所以如果脚本需要在HIVE命令行里直接调试时,脚本不要使用Tab来缩进,使用空格
显示表头
set hive.cli.print.header=true;
SET环境变量

在命令行中,可以使用 SET 命令显示或者修改变量的值
如果直接输入 SET 命令,即会显示所有环境变量
与 hivevar、 hiveconf 变量不同的是,system: 与 env: 前缀是不能省略的
使用变量:${变量}
set hivevar:dd=aa;
select '${hivevar:dd}';//注:使用时加上命名空间
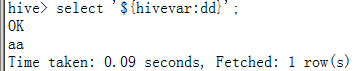
注:定义与使用时还是最好加上hivevar名称空间,否则可能找不到
set hiveconf:hive.exec.dynamic.partition.mode=nonstrict;
查看建表语句、数据文件置
show create table sap_r3_zfit534;
DESCRIBE formatted sap_r3_zfit534;
执行外部命令
在hive命令提示符下执行Hadoop的dfs命令:
只需要将hadoop命令中的关键字hadoop去掉,并以分号结尾即可:
dfs -ls hdfs://SuningHadoop2/user/erp/hive/warehouse/erp.db/ztst_6;
用户在不用退出hive命令符就可以执行简单的 bash shell 命令:以 ! 开头,以 ; 结尾
hive> ! echo 'Hello';
NVL
NVL( string1, replace_with)
string1为 NULL则NVL函数返replace_with值,否则返string1值
droptable test;
CREATETABLE test AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,1 as f3;

select *,nvl(f2,'值为NULL') from test;

CONCAT
concat(str1, str2, ... strN):如果其中任何一个为NULL,则结果为NULL,所以最好结合NVL使用:
concat(NVL(a.office,''),'00',NVL(b.posOrderId,'')))
droptable test;
CREATETABLE test AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,1 as f3;
select *,concat(f1,f2,f3) from test;

select *,concat(f1,nvl(f2,'NULL'),f3) from test;

IF
if(条件,值1,值2)
当条件为真时,取值1,否则取值2。值1或值2还可以是其他可返回值的函数表达式,如IF或CASE,即可以嵌套IF
droptable test;
CREATETABLE test AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,1 as f3;
select *,if(f2 isnull,'NULL','NOT NULL') from test;

CASE
情况很多时,可以使用CASE来代替嵌套的IF:
case
when b.kunnr is not null and b.kunnr <> '' then b.kunnr
when b.lifnr is not null and b.lifnr <> '' then b.lifnr
else b.hkont
end
droptable test;
CREATETABLE test AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,2 as f3
unionall
SELECT'c' f1,'d'as f2,3 as f3;
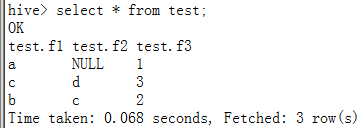
select *,case f3 when 1 then'一' when 2 then'二' when 3 then'三'endfrom test;
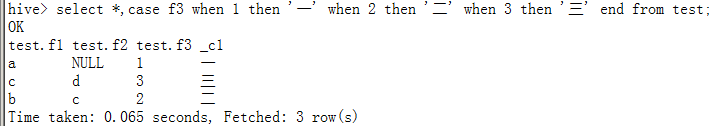
TRIM
去除前后空格
selecttrim(' facebook '),length(trim(' facebook '));

如果为NULL,则trim结果还是NULL
droptable test;
CREATETABLE test AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,2 as f3;
select *,trim(f2) from test;

注:Trim不能直接对NULL进行操作:
hive> selecttrim(null);
FAILED: SemanticException [Error 10014]: Line 1:7 Wrong arguments 'TOK_NULL': trim takes only STRING/CHAR/VARCHAR types. Found VOID
但通过其他函数返回的NULL值是可以的(因为这些函数返回的类型为字符类型而非VOID类型):
selecttrim(if(1<>1,'1',null));
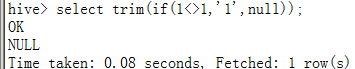
SUBSTRING
substr(str, pos[, len]) :位置是从1开始数,不是0。如果是负,则从后往前数,然后再截后面
SELECTsubstr('Facebook', 5) ;
'book'
SELECTsubstr('Facebook', -5) ;
'ebook'
SELECTsubstr('Facebook', 5, 1);;
'b'
substring(a.XBLNR,1,4)--取XBLNR前四位
如果为NULL,则返回NULL:

LENGTH
字符串长度

如果为NULL,则返回NULL:
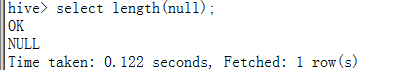
注:NULL <> 0
UPPER
转大写:

upper(trim(nvl(c.USNAM,''))) <> 'RETAIL'
如果为NULL,则返回NULL:

非空判断
如果有将NULL与空字符串都看做空的话,可以这样:
trim(nvl(b.KUNNR,'')) <> ''
LPAD
左填充:lpad(str, len, pad)
如果str长度小于len,则使用pad填充左侧直到len长度:
SELECTlpad('hi', 5, '??') ;
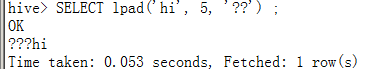
如果str长度大于len,则会截断至len长度:
SELECTlpad('hi', 1, '??') ;
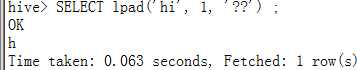
rpad(str, len, pad)
日期函数
select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'); --当前时间

select from_unixtime(unix_timestamp('20150101','yyyyMMdd'),'yyy-MM-dd'); --格式化

select from_unixtime(unix_timestamp('2015/01-01','yyyy/MM-dd'),'yyyMMdd');--去掉日期格式
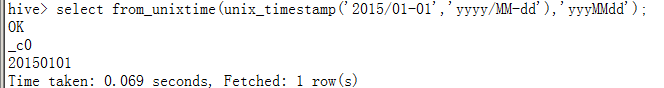
unix_timestamp('20150101','yyyyMMdd') 与 to_unix_timestamp('20150101','yyyyMMdd')相同
但 unix_timestamp 还可以返回当前时间,to_unix_timestamp不可以
【is null】 = 【 = null】?、【is not null】 = 【 <> null】?
hive 里(包括IF函数与Where条件里)判断是否为NULL要用 is null或 is not null ,不能使用 <> null 或 = null(虽然不报错)
测试如下:
droptable test;
CREATETABLE test AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,1 as f3;
select * from test where f2 = null;

select * from test where f2 isnull;

select *,if(f2=null,'null','not null') from test;

select *,if(f2 isnull,'null','not null') from test;

[NOT] IN、[NOT] EXISTS、LEFT SEMI JOIN
droptable test1;
CREATETABLE test1 AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,2 as f3;
droptable test2;
CREATETABLE test2 AS
SELECT'a' f1,nullas f2,3 as f3
unionall
SELECT'd' f1,'d'as f2,4 as f3;


select * from test1 a whereEXISTS(select f1 from test2 b where a.f1 = b.f1); --注:HIVE与标准SQL不同的是:[NOT] EXISTS后面跟的子查询一定要是相关子查询,否则运行出错(相关子查询对外层查询结果集中的每条记录都会执行一次,所以尽量少用相关子查询——标准SQL好似这样,HIVE不一定)
select * from test1 a where a.f1 IN(select f1 from test2 b);
select * from test1 a LEFT SEMI JOIN test2 b on a.f1 = b.f1;

SEMI-JOIN比通常的inner JION效率要高:对于左表中的一条记录,在右边表中一旦找到匹配的记录,Hive就会立即停止扫描
LEFT SEMI JOIN 的限制是:右表中的字段只能在ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行,所以这也就是为什么LEFT SEMI JOIN 只能当作 IN/EXISTS 来使用的原因
早期版本可能还不支持[NOT] IN、[NOT] EXISTS,所以最好使用LEFT SEMI JOIN
ORDER BY、SORT BY
ORDER BY为全局排序,会将所有数据送到同一个Reducer中后再对所有数据进行排序,对于大数据会很慢,谨慎使用
SORT BY为局部排序,只会在每一个Reducer中对数据进行排序,在每个Reducer输出是有序的,但并非全局排序(每个reducer出来的数据是有序的,但是不能保证所有的数据是有序的——即文件(分区)之间无序,除非只有一个reducer)
DISTRIBUTE BY 是控制map的输出被送到哪个reducer端进行汇总计算。注:HIVE reducer分区个数由mapreduce.job.reduces来决定,该选项只决定使用哪些字段做为分区依据,如果没通过DISTRIBUTE BY指定分区字段,则默认将整个文本行做为分区依据。分区算法默认是HASH,也可以自己实现。
注:这里DISTRIBUTE BY讲的分区概念是指Hadoop里的,而非我们HIVE数据文本存储分区。Hadoop里的Partition主要作用就是将map的结果发送到相应的reduce,默认使用HASH算法,不过可以重写
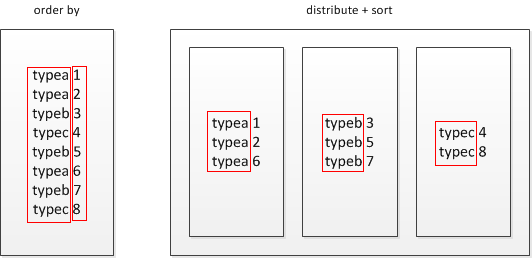
droptable test1;
createtable test1 as
select'typea' f1,6 f2
unionall
select'typea' f1,2 f2
unionall
select'typeb' f1,7 f2
unionall
select'typec' f1,8 f2
unionall
select'typeb' f1,5 f2
unionall
select'typea' f1,1 f2
unionall
select'typeb' f1,3 f2
unionall
select'typec' f1,4 f2;
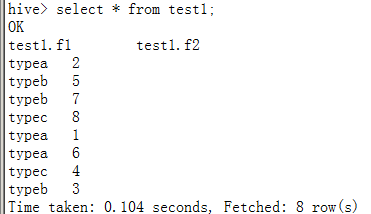
select * from test1 orderby f2 asc;--全局有序
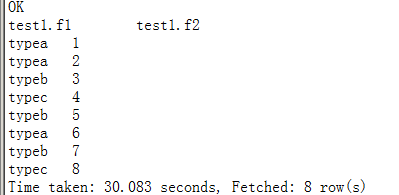
set mapreduce.job.reduces=10;
select * from test1 sort by f2;--虽然SORT BY是区内有序,但由于未通过DISTRIBUTE指定分区字段,而最大分区又设置为了10,所以每条记录所分配到的reducer可能不尽相同(有可能某两条会放在同一分区中,这取决于HASH算法),所以此时看不出什么区内有序

set mapreduce.job.reduces=1;
select * from test1 sort by f2;--将最大分区设置为一个分区,所以具有order by一样具有全局排序效果
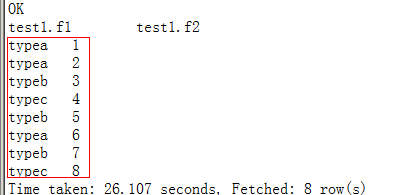
set mapreduce.job.reduces=10;
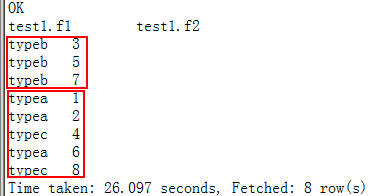
select * from test1 DISTRIBUTE BY f1 sort by f2;--将最大分区设为10,再通过DISTRIBUTE指定分区字段,而不使用默认整行文本来分区
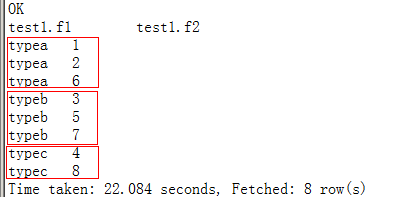
set mapreduce.job.reduces=2;
select * from test1 DISTRIBUTE BY f1 sort by f2;--由于分区最大设置为2,f1分区字段值有3种,这会根据HASH分区算法,会将其中某两种放在同一分区,而另外一种放在另外的分区,最终看到两个分区内部也是有序的
ROW_NUMBER
类似Oracle中的ROWNUM,给查询出的记录编号,HIVE中一般与DISTRIBUTE BY一起使用。其作用按指定的列进行分组生成行序列,在ROW_NUMBER() 时,会根据 DISTRIBUTE BY (a,b...)中指定的列来判断,若两条记录的a,b列相同,则行序列+1,否则重新计数。因为HIVE是基于MAPREADUCE的,必须保证列值相同的记录要在同一个reduce中,所以需要与DISTRIBUTE BY结合使用,否则ROW_NUMBER无意义。
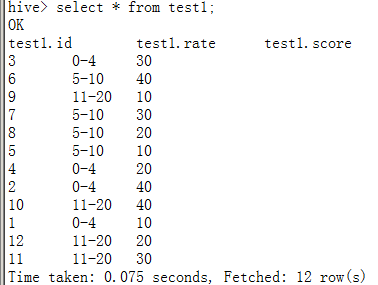
假设一个场景:存在表test1,该表的数据如下
id rate score
1 '0-4' 10
2 '0-4' 40
3 '0-4' 30
4 '0-4' 20
5 '5-10' 10
6 '5-10' 40
7 '5-10' 30
8 '5-10' 20
9 '11-20' 10
10 '11-20' 40
11 '11-20' 30
12 '11-20' 20
现在要求用一条查询语句取出每种rate下score最大的两条记录,也就算取出id为:2,3,6,7,10,11的记录
droptable test1;
createtable test1 as
select 1 id,'0-4' rate,10 score
unionall
select 2 id,'0-4' rate,40 score
unionall
select 3 id,'0-4' rate,30 score
unionall
select 4 id,'0-4' rate,20 score
unionall
select 5 id,'5-10' rate,10 score
unionall
select 6 id,'5-10' rate,40 score
unionall
select 7 id,'5-10' rate,30 score
unionall
select 8 id,'5-10' rate,20 score
unionall
select 9 id,'11-20' rate,10 score
unionall
select 10 id,'11-20' rate,40 score
unionall
select 11 id,'11-20' rate,30 score
unionall
select 12 id,'11-20' rate,20 score;
SELECT a.* FROM(SELECT *,row_number() over (distribute by rate SORTBY rate ASC, score DESC) rownum FROM test1 ) a WHERE rownum <= 2 ;--结果正确,只启动一个JOB

注:可以去掉SORT BY后面分区字段,而不影响结果,应该是在排序时默认就已加上了分区字段,但以防出错,不要省略
注:ROW_NUMBER+DISTRIBUTE BY结果与分区个数无关,所以通过set mapreduce.job.reduces不会影响正确结果:
hive> set mapreduce.job.reduces=1;
hive> SELECT a.* FROM(SELECT *,row_number() over (distribute by rate SORT BY score DESC) rownum FROM test1 ) a WHERE rownum <= 20;

SELECT a.* FROM(SELECT *,row_number() over (partition by rate ) rownum FROM test1 SORT BY rate ASC, score DESC) a WHERE rownum <= 2 ;--看见有人这么用过,但结果不正确,partition到底有啥用?会启动两个JOB,相对于distribute感觉慢,所以还是使用distribute吧

row_number()另一作用可以用来去除重复:先按分组字段分区,再通过 rownum = 1过滤即可。另外,去重还可以借助于group by:
select actual_pymnt_dt from sap_r3_ZFIT684_tmp groupby actual_pymnt_dt
ON > WHERE > HAVING
为了提交性能,INNER JOIN时,非连接条件放置的位置应该按照 ON > WHERE > HAVING的顺序优先放置,因为SQL条件的的执行一般是按这个顺序来执行的,将条件放在最开始执行,则可过滤掉大部数据;
如果是LEFT JOIN,非连接条件放在WHERE还是ON中是有所不同的,请参考后面
ON非连接字段条件问题
1、 ON条件中不支持OR连接,只能使用AND
2、 在外连接中,不要轻易的将Where中的条件移到ON连接语句中(虽然不报错),因为在HIVE的外连接ON语句中,会忽略(严格来讲不是忽略,而是只拿满足条件的记录去与另一表进行关联,左表没关联上的还是会显示出来,请看后面实验)掉所有除连接字段条件所有条件:
droptable test1;
CREATETABLE test1 AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,2 as f3;
droptable test2;
CREATETABLE test2 AS
SELECT'a' f1,nullas f2,3 as f3
unionall
SELECT'd' f1,'d'as f2,4 as f3;


select * from test1 a leftjoin test2 b on a.f1=b.f1;
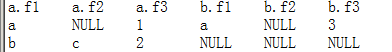
select * from test1 a leftjoin test2 b on a.f1=b.f1 and a.f1='a';

select * from test1 a leftjoin test2 b on a.f1=b.f1 where a.f1='a';

严格为讲,ON中的非连接条件还是起一定作用的:如下面的a记录所对应的右表记录为NULL,因为条件a.f1='b'只会拿满足条件的左表记录b去与右表去关联,但未关联上,所以对应的右表显示为NULL;不满足条件的左表记录a不会去做关联(虽然在右表中存在),但还是会显示出来,只是所以对应的右表也显示为NULL:
select * from test1 a leftjoin test2 b on a.f1 = b.f1 and a.f1 = 'b';

思考下面的结果?
select * from test1 a leftjoin test2 b on a.f1=b.f1 and b.f1='d';
对于INNER JOIN,ON语中中的非连接条件是起做用的:
select * from test1 a innerjoin test2 b on a.f1=b.f1 and a.f1='a';

总结:
1、 如果是INNER JOIN,为了提高性能,非连接字段条件最好放置在ON从句中
2、 如果是LEFT JOIN,非连接字段条件最好放在Where从句中,但若想放在ON从句中,可以使用嵌套子查询来解决不必要的麻烦:
在外联连中,如果要想Where语句中的条件移到ON语句中,可以使用如下的嵌套语句来实现,这样即在联接前过滤了不必要的数据,提高效率的同时又没有丢掉数据:
select * from (select * from test1 where f1='a') a leftjoin test2 b on a.f1=b.f1;

NULL值条件问题
如果某字段存为NULL的值,则用该字段进行过滤时,NULL需要单独处理:
droptable test1;
CREATETABLE test1 AS
SELECT'a' f1,nullas f2,1 as f3
unionall
SELECT'b' f1,'c'as f2,2 as f3
unionall
SELECT'd' f1,'d'as f2,3 as f3;

select * from test1 where f2 <> 'c';--NULL值的没有查出来(标准SQL也是这样的)

select * from test1 where f2 <> 'c' or f2 is null; --如果需要取出NULL,需要单独加上

正则表达式
regexp_extract(str, regexp[, idx]) - extracts a group that matches regexp抽取匹配到的指定组
SELECT regexp_extract('100\200', '^(\d+).(\d+)$', 0);
100200
SELECT regexp_extract('100-200', '^([0-9]+)-([0-9]+)$', 1);
100
SELECT regexp_extract('100-200', '^([0-9]+)-(\d+)$', 2);
200
注:需要使用转义一下
小数精度问题
不要使用Float类型
在建表时,如果要将金额字段定义成数据类型,请将定义成Double类型,或对数字类型比较时,请先转换成Double再进行比较,否则不准确(早其版本会有精度丢失问题):
cast(a.payAmount as double) = cast(b.payAmount as double)
或者直接通过字符串比较的方式来比较数字,但比较前需要前后对齐(如不补齐会导致9.8 > 10.8),请看下面:
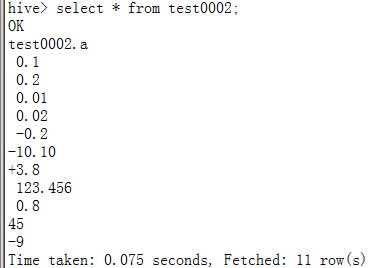
select a as a000000000,
regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',0) c0,--整个匹配
regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',1) c1,--正负号
regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',2) c2,--整数部分
regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',3) c3,--小数点
regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',4) c4,--小数部分
case concat(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',1),'')
when '-'then
concat('-',lpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',2),16,'0'),'.',
rpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',4),4,'0'))
else
concat('0',lpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',2),16,'0'),'.',
rpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',4),4,'0'))
end c500000000000000000000,--整数、小数部分对齐
case concat(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',1),'')
when '-'then
cast(concat('-',lpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',2),16,'0'),'.',
rpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',4),4,'0')) asdouble)
else
cast(concat('0',lpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',2),16,'0'),'.',
rpad(regexp_extract(trim(a),'^([-+]?)([0-9]*)(.?)([0-9]*)$',4),4,'0')) asdouble)
end c6--转换成真正的小数
from test0002;

增量更新表
insert overwrite table erp.tsor_BKPF --要更新此表
SELECT td.* FROM (
select ta.*
from erp.tsor_BKPF ta --先要把原来中未更新的数据捞出来
leftjoin (select tc.MANDT,tc.BUKRS,tc.BELNR,tc.GJAHR from BI_SOR.TSOR_FN_R3_BKPF_D tc --此表为增量表
where tc.STATIS_DATE='${hivevar:statis_date}' )tb on
ta.MANDT=tb.MANDT
and ta.BUKRS=tb.BUKRS
and ta.BELNR=tb.BELNR
and ta.GJAHR=tb.GJAHR
where concat(tb.MANDT,tb.BUKRS,tb.BELNR,tb.GJAHR) isnull
union all
select ta.* --再与发生更新的数据Union
from BI_SOR.TSOR_FN_R3_BKPF_D ta
where ta.STATIS_DATE='${hivevar:statis_date}'
)td;
分区表更新:
insert overwrite table erp.sap_r3_ZFIT684 PARTITION (actual_pymnt_dt)
select e.* from
(
--未更新的数据
select a.* from (
select * from erp.sap_r3_ZFIT684 d --目标表
--CBT平台抛数据任务里不支持 HIVE变量,所以如果要使用 ${hivevar:statis_date}变量的话,需要将后置SQL做成HIVE任务
--where actual_pymnt_dt = '${hivevar:statis_date}'
LEFT SEMI JOIN (select actual_pymnt_dt from sap_r3_ZFIT684_tmp groupby actual_pymnt_dt) dd
ond.actual_pymnt_dt = dd.actual_pymnt_dt--从目标表中只捞出需要处理的分区数据
) a
leftjoin (select
mandt,serial_no,shkzg,xblnr,payee_co_code,biz_categ,biz_sub_categ,zuonr,money,pymnt_amt,
supplier_name,waers,twaers,sgtxt,bukrs3,belnr3,gjahr3,flag3,meg3,belnr2,gjahr2,flag2,meg2,
belnr1,gjahr1,budat1,flag1,meg1,msg,clear,refund_no,file_name,RECIVE_DT,RECIVE_TM,actual_pymnt_dt
from erp.sap_r3_ZFIT684_tmp) b --增量表
on a.MANDT=b.MANDT and a.SERIAL_NO=b.SERIAL_NO and a.SHKZG=b.SHKZG --通过主键进行关联
where b.MANDT isnulland b.SERIAL_NO isnulland b.SHKZG isnull
union all
--已更新的数据(包括新增、修改的数据,删除需要在上面取未更新的数据时过滤掉即可 )
select
mandt,serial_no,shkzg,xblnr,payee_co_code,biz_categ,biz_sub_categ,zuonr,money,pymnt_amt,
supplier_name,waers,twaers,sgtxt,bukrs3,belnr3,gjahr3,flag3,meg3,belnr2,gjahr2,flag2,meg2,
belnr1,gjahr1,budat1,flag1,meg1,msg,clear,refund_no,file_name,RECIVE_DT,RECIVE_TM,actual_pymnt_dt
from erp.sap_r3_ZFIT684_tmp c
) e;
其他
1、 JOIN查询时,尽量将小表放在前面
2、 两个表join的时候,不支持两个表的字段非等值操作,可以将非相等条件提取到where中