14.1 基本介绍
文件是数据源(保存数据的地方)的一种,,比如大家经常使用的word文档,txt文件都是文件,文件最主要的作用就是保存数据,它既可以保存一张图片,也可以保持声音,视频。。。。
文件在程序中是以流的形式来操作的。

流:数据在数据源(文件)和程序(内存)之间经历的路径
输入流:数据从数据源(文件)到程序(内存)的路径
输出流:数据从程序(内存)到数据源(文件)的路径
os.File封装所有文件相关操作,File是一个结构体
14.2 常用的文件操作函数和方法
使用的函数和方法是
1、打开一个文件进行度操作

2、关闭文件

案例演示
package main
import (
"fmt"
"os"
)
func main() {
// 打开一个文件
// 概念说明:file说明
// file 叫 file对象
// file 叫 file指针
// file 叫 file文件句柄
file , err := os.Open("d:/test.txt") //d:/test.txt 是真实存在的,否则会报错
if err != nil {
fmt.Println("open file err=", err)
}
// 输出文件,看看文件是什么,看出file就是一个指针
fmt.Printf("file=%v", file)
// 关闭文件
err = file.Close()
if err != nil {
fmt.Println("close file err=", err)
}
14.3 读文件操作
1、读取文件的内容并显示在终端(带缓冲区的方式)
package main
import (
"fmt"
"os"
"bufio"
"io"
)
func main() {
// 打开一个文件
// 概念说明:file说明
// file 叫 file对象
// file 叫 file指针
// file 叫 file文件句柄
file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
// 当函数退出时,要及时的关闭file
defer file.Close() //要及时关闭file句柄,否则会有内存泄露
// 创建一个*Reader,是带缓冲的
/*
const (
defaultBufSize = 4096 //默认缓冲区4096
)
*/
reader := bufio.NewReader(file)
// 循环的读取文件的内容
for {
str, err := reader.ReadString('
') //读到一个换行
if err == io.EOF { //io.EOF表示文件的末尾
break
}
// 输出内容
fmt.Println(str)
}
fmt.Println("文件读取结束。")
}
2、读取文件的内容并显示在终端(使用ioutil一次将整个文件读取到内存中),这种方式适用于文件不大的情况。
package main
import (
"fmt"
"io/ioutil"
)
func main() {
// 使用ioutil.ReadFile一次性将文件读取到位
file := "d:/test.txt"
content, err := ioutil.ReadFile(file)
if err != nil {
fmt.Println("read file err=", err)
}
// 把读取到的内容显示在终端
// fmt.Printf("%v", content) //[]byte
fmt.Printf("%v", string(content)) //切片转换为string类型
//因为,我们没有显示的open文件,因此也不需要显示的close文件
// 因为,文件的Open和Close被封装到ReadFile函数内部
}
14.4 写文件
基本介绍
func OpenFile(name string, flag int, perm FileMode) (file *File,err error)
说明:os.OpenFile是一个一般性的文件打开函数,它会使用指定的选项如(O_RDONLY),指定的模式(如0666) 打开指定名称的文件,如果操作成功,返回的文件对象可用于I/O,如果出错,错误底层类型是*PsthError.第二个参数:文件打开模式(可以组合)

第三个参数:控制权限(linux)

基本应用实例
1、创建一个新文件,写入内容5句"hello,golang"
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
// 创建一个新文件,写入内容5句"hello,golang"
// 1、打开文件 d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v", err)
return
}
// 及时关闭文件
defer file.Close()
// 2、准备写入5句 hello,golang
str := "hello,golang
"
// 写入时,使用带缓存的*Write
write := bufio.NewWriter(file)
for i :=0; i < 5; i++ {
write.WriteString(str)
}
// 因为write是带缓存的,因此在调用WriteString,其实内容是先写入到缓存,所以需要调用flush方法,
// 将缓存的数据真正写入到文件中,否则文件中会没有数据
write.Flush()
}
2、打开一个存在的文件中,将原来的内容覆盖成新的内容10句 “你好,Golang”
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
// 1、打开一个已经存在的文件 d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_TRUNC, 0666)
if err != nil {
fmt.Printf("open file err=%v", err)
return
}
// 及时关闭文件
defer file.Close()
// 2、准备写入5句 hello,golang
str := "你好,Golang
"
// 写入时,使用带缓存的*Write
write := bufio.NewWriter(file)
for i :=0; i < 10; i++ {
write.WriteString(str)
}
// 因为write是带缓存的,因此在调用WriteString,其实内容是先写入到缓存,所以需要调用flush方法,
// 将缓存的数据真正写入到文件中,否则文件中会没有数据
write.Flush()
}

3、存在的文件,在原来的内容追加内容'ABC! ENGLISH!'
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
// 1、打开一个已经存在的文件 d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err=%v", err)
return
}
// 及时关闭文件
defer file.Close()
// 2、准备写入
str := "ABC,ENGLISH
"
// 写入时,使用带缓存的*Write
write := bufio.NewWriter(file)
for i :=0; i < 10; i++ {
write.WriteString(str)
}
// 因为write是带缓存的,因此在调用WriteString,其实内容是先写入到缓存,所以需要调用flush方法,
// 将缓存的数据真正写入到文件中,否则文件中会没有数据
write.Flush()
}

4、打开一个存在的文件,将原来的内容读出显示在终端,并且追加5句“hello,北京!"
package main
import (
"fmt"
"bufio"
"os"
"io"
)
func main() {
// 1、打开一个已经存在的文件 d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_RDWR | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err=%v", err)
return
}
// 及时关闭文件
defer file.Close()
// 2、先读取原来文件的内容,显示在终端
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('
')
if err == io.EOF { //如果读取到文件的末尾
break
}
// 显示到终端
fmt.Printf(str)
}
// 3、准备写入
str := "你好!北京
"
// 写入时,使用带缓存的*Write
write := bufio.NewWriter(file)
for i :=0; i < 5; i++ {
write.WriteString(str)
}
// 因为write是带缓存的,因此在调用WriteString,其实内容是先写入到缓存,所以需要调用flush方法,
// 将缓存的数据真正写入到文件中,否则文件中会没有数据
write.Flush()
}

5、将一个文件的内容,写入到另一个文件中,注意:这两个文件已经存在
package main
import (
"fmt"
"io/ioutil"
)
func main() {
// 将d:abc.txt文件中的内容追导入到d:/kkk.txt中
// 1、首先将 d:/abc.txt内容读取到内存
// 2、将读取到的内容,写入d:/kkk.ttx
file1Path := "d:/abc.txt"
file2Path := "d:/kkk.txt"
data, err := ioutil.ReadFile(file1Path)
if err != nil {
// 读取文件错误
fmt.Printf("read file err=%v
", err)
return
}
err = ioutil.WriteFile(file2Path, data, 0666)
if err != nil {
fmt.Printf("write file error=%v", err)
}
}
14.5 判断文件是否存在
Golang判断文件或文件夹是否存在的方法为使用os.Stat()函数的错误值进行判断:
1、如果返回的错误为nil,说明文件或文件夹存在
2、如果返回的错误类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在
3、如果返回的错误为其他类型,则不确定是否存在
//自己写的一个函数
func PathExists(path string)(bool, error) {
_, err := Stat(path)
if err == nil { //文件或目录存在
return true, nil
}
if os.IsNotExist(err){
return false, nil
}
return false, err
}
14.6 文件编程实例
拷贝文件
将一张图片/电影/MP3拷贝到另外一个文件d:/test/
注意:Copy函数是io包提供的
代码实现:
package main
import (
"fmt"
"io"
"os"
"bufio"
)
// 自己编写一个函数,接收两个文件路径
// 源文件srcFileName 目标文件dstFileName
func CopyFile(dstFileName string, srcFileName string) (written int64, err error) {
srcFile, err := os.Open(srcFileName)
if err != nil {
fmt.Printf("open file err=%v", err)
}
// 通过srcfile,获取到 Reader
reader := bufio.NewReader(srcFile)
defer srcFile.Close()
// 打开dstFileName
dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v
", err)
return
}
// 通过dstFile,获取到Write
writer := bufio.NewWriter(dstFile)
defer dstFile.Close()
return io.Copy(writer, reader)
}
func main() {
// 将d:/Github.jpg 文件拷贝到d:/test/abc.jpg
// 调用CopyFile完成拷贝
srcFile := "d:/Github.jpg" //d:/Github.jpg真实存在
dstFile := "d:/test/abc.jpg"
_, err := CopyFile(dstFile, srcFile)
if err == nil {
fmt.Println("拷贝完成")
} else {
fmt.Printf("拷贝失败 err=%v", err)
}
}
统计英文、数字、空格、和其他字符数量
说明:统计英文、数字、空格、和其他字符数量
package main
import (
"fmt"
"io"
"os"
"bufio"
)
// 定义一个结构体, 用于保存统计结果
type CharCount struct {
ChCount int //记录英文个数
NumCount int //记录数字的个数
SpaceCount int //记录空格的个数
OtherCount int //记录其他字符的个数
}
func main() {
// 思路:打开一个文件,创建一个reader
// 每读取一行,就去统计有多少个英文、数字、空格和其他字符
// 然后将结果保存到一个结构体中
fileName := "d:/abc.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("open file err=%v
", err)
return
}
defer file.Close()
// 定义一个CharCount 实例
var count CharCount
// 创建一个reader
reader := bufio.NewReader(file)
// 开始循环的 读取fileName文件的内容
for {
str, err := reader.ReadString('
')
if err == io.EOF { //读到文件的末尾就退出
break
}
// 为了兼容中文,可以将str转换成[]rune
str = []run(str)
// 遍历str ,进行统计
for _, v := range str {
switch {
case v >= 'a' && v <= 'z':
fallthrough //穿透处理
case v >= 'A' && v <= 'Z':
count.ChCount++
case v == ' ' || v == ' ':
count.SpaceCount++
case v >= '0' && v <= '9':
count.NumCount++
default :
count.OtherCount++
}
}
}
// 输出统计的结果
fmt.Printf("字符的个数为=%v 数字的个数为=%v 空格的个数为=%v 其他字符的个数为=%v",
count.ChCount, count.NumCount, count.SpaceCount, count.OtherCount)
}

14.7 命令行参数
我们希望能够获取到命令行输入的种参数,该如何处理? ==》命令行参数
基本介绍
os.Args是一个string的切片,用来存储所有的命令行参数
案例

flag包来解析命令行参数
前面的代码对解析参数不是特别的方便,特别是带有指定参数形式的命令行,go设计者给提供了flag包,可以方便解析命令行参数,而且参数顺序可以随意

14.8 json
14.8.1 基本介绍
JSON是一种轻量级的数据交换格式,易于人阅读和编写。同时也易于机器解析和生成。
JSON易于机器解析和生成,并有效地提升网络传输效率,通常程序在网络传输时会先将数据(结构体、map等)序列化成json字符串,到接收方得到json字符串时,在反序列化恢复成原来的数据类型(结构体、map等),这种方式已然成为各个语言的标准

应用场景
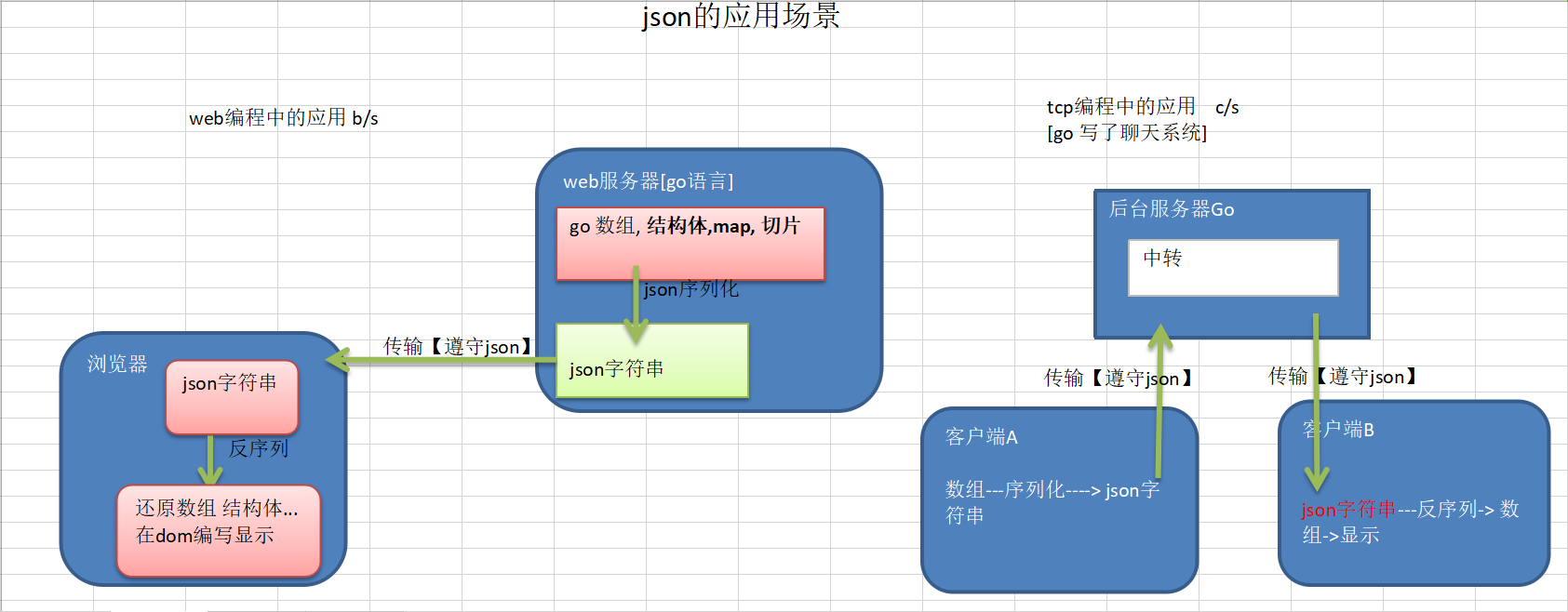
json数据格式说明
在js语言中,一切都是对象。因此,任何支持的类型都可以通过json来表示,如:字符串、数字、对象、数组等
json键值对是用来保存数据的一种方式,键/值对组合中的键名写在前面并用双引号 "" 包括,使用冒号 : 分割,然后紧跟着值。{"key1":"val1","key2":"val2"}
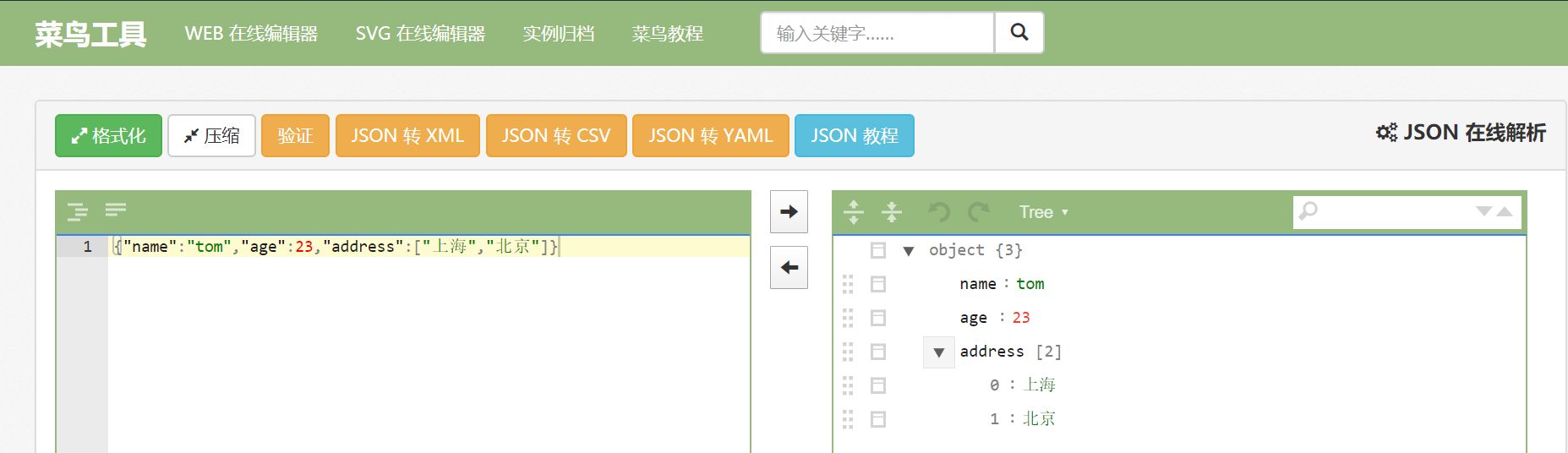
14.8.2 json的序列化
介绍
json序列化是指:将key-value结构的数据类型(比如结构体、map、切片)序列化成json字符串的操作
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string `json:"name"` //反射机制,指定反序列化后name为小写而不是Name,下面的亦可以
Age int
Birthday string
Sal float64
Skill string
}
// 结构体序列化
func testStruct() {
// 演示
monster := Monster {
Name : "牛魔王",
Age : 500,
Birthday : "100-11-1",
Sal : 9999.7696,
Skill : "牛魔头",
}
// 将monster序列化
data, err := json.Marshal(&monster)
if err != nil {
fmt.Printf("序列化失败 err=%v
", err)
}
// 输出序列化后的结果
fmt.Printf("monster序列化后的结果=%v
", string(data))
}
// 将map序列化
func testMap() {
// 定义一个map
var a map[string]interface{}
// 使用map之前make
a = make(map[string]interface{})
a["name"] = "红孩儿"
a["age"] = "400"
a["address"] = "洪崖洞"
// 将a这个map序列化
data1, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化失败 err=%v
", err)
}
// 输出序列化后的结果
fmt.Printf("a map序列化后的结果=%v
", string(data1))
}
// 切片序列化,切片类型是map[string]interface{}
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
m1["name"] = "钢铁侠"
m1["age"] = "45"
m1["address"] = "美国"
slice = append(slice, m1)
var m2 map[string]interface{}
m2 = make(map[string]interface{})
m2["name"] = "绿巨人"
m2["age"] = "34"
m2["address"] = [2]string{"美国","纽约"}
slice = append(slice, m2)
// 将切片进行序列化
data3, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化失败 err=%v
", err)
}
// 输出序列化后的结果
fmt.Printf("切片序列化后的结果=%v
", string(data3))
}
// 对基本数据类型序列化意义不大
func testInt() {
var num1 float64 =23456.5432
data4, err := json.Marshal(num1)
if err != nil {
fmt.Printf("序列化失败 err=%v
", err)
}
// 输出序列化后的结果
fmt.Printf("切片序列化后的结果=%v
", string(data4))
}
func main() {
// 演示将结构体、map、切片进行序列化
testStruct()
testMap()
testSlice()
testInt()
}
注意事项
对于结构体的序列化,如果我们希望序列化后的key的名字,是我们自己重新制定,那么可以给struct指定一个tag标签
代码变动
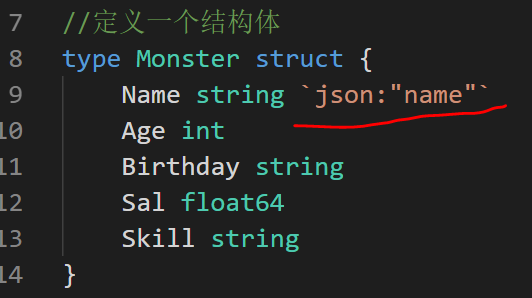
结果为

14.8.3 json的反序列化
json反序列化是指:将json字符串反序列化成对应的数据类型(结构体、map、切片)的操作
将json字符串反序列化成结构体、map和切片
package main
import (
"fmt"
"encoding/json"
)
// 定义一个结构体
type Monster struct {
Name string
Age int
Birthday string
Sal float64
Skill string
}
// 演示将json字符串,反序列化成struct
func unmarshalStruct() {
str := "{"Name":"牛魔王","Age":500,"Birthday":"2018-08-15","Sal":5000,"Skill":"牛魔拳"}"
// 定义一个Monster实例
var monster Monster
err := json.Unmarshal([]byte(str),&monster)
if err != nil {
fmt.Printf("unmarshal err=%v
", err)
}
fmt.Printf("结构体struct反序列化后 monster=%v
", monster)
}
// 演示将json字符串,反序列化成map
func unmarshalMap() {
str := "{"address":"火焰山","age":30,"name":"红孩儿"}"
//定义一个map
var a map[string]interface{}
// 反序列化
// 注意:反序列化map,不需要make,因为make操作被封装到 Unmarshal函数
err := json.Unmarshal([]byte(str),&a)
if err != nil {
fmt.Printf("unmarshal err=%v
", err)
}
fmt.Printf("Map反序列化后 a=%v
", a)
}
// 演示将json字符串,反序列化成切片
func unmarshalSlice() {
str := "[{"address":"北京","age":"7","name":"jack"}," +
"{"address":["墨西哥","夏威夷"],"age":"20","name":"tom"}]"
var slice []map[string]interface{}
// 反序列化
err := json.Unmarshal([]byte(str),&slice)
if err != nil {
fmt.Printf("unmarshal err=%v
", err)
}
fmt.Printf("切片反序列化后 slice=%v
", slice)
}
func main() {
unmarshalStruct()
unmarshalMap()
unmarshalSlice()
}
对上面代码说明
1、在反序列化一个json字符串时,要确保反序列的数据类型和原来序列化前的数据类型一致
2、如果json字符串是通过程序获取的,则不要在对"转义处理。