1.1 在centos6.5中安装Redis
1. 到官网下载Redis:https://redis.io/download
2. 或者直在Linux下运行下面命令
$ wget http://download.redis.io/releases/redis-3.2.8.tar.gz
$ tar xzf redis-3.2.8.tar.gz
$ cd redis-3.2.8
$ make
3. 先启动Redis服务器端:redis-server
4. 然后再启动Redis客户端:redis-cli redis-cli --raw(可以在命令行中显示中文)
5. 安装完成在centos中克隆会话输入redis-cli就可以进行操作
6. python操作Redis需要安装Redis模块( pip install redis )


# redis-cli #启动Redis客户端 # redis> set foo bar #设置字典key=foo value=bar # OK # redis> get foo #获取字典中key foo的值bar # "bar"
7. 远程客户端无法登录Redis服务器报错,解除保护模式
1)修改redis服务器的配置文件(否则redis默认本机启动无法远程连接操作)
注:源码安装的redies配置文件默认在当前文件夹下( vim /bbb/redis-3.2.8/redis.conf 这里以在/bbb文件夹下安装redis)
vi redis.conf
注释以下绑定的主机地址 : # bind 127.0.0.1 (将绑定修改成:bind 0.0.0.0 )
关闭保护模式:protected-mode no
2)修改redis服务器的参数配置
a. 修改redis的守护进程为no ,不启用
127.0.0.1:6379> config set daemonize "no" #可能无法执行
b.修改redis的保护模式为no,不启用 #上一步执行报错,就只执行这条命令,就可行了
127.0.0.1:6379> config set protected-mode "no"
8. yum安装redis: https://www.linuxidc.com/Linux/2018-02/150956.htm
9、修改配置文件让redis后台启动
1) 修改配置文件
vim /bbb/redis-3.2.8/redis.conf
daemonize yes # 将daemonize配置修改成yes
2)启动命令
cd /bbb/redis-3.2.8/src
./redis-server ../redis.conf
3) 确认redis已启动(并根据进程号杀死进程)
(env)[root@op-dev-xiaonaiqiang src]# ps -ef|grep redis root 31416 1 0 18:51 ? 00:00:00 ./redis-server 127.0.0.1:6379
10、将redis加入环境变量
1)# vi /etc/profile 在最后添加以下内容
## Redis env
export PATH=$PATH:/aaa/redis-3.2.8/src
2)使配置生效:
# source /etc/profile 现在就可以直接使用 redis-cli 等 redis 命令了
1.2 Redis的简介及两种基本操作
1、Redis简介
1. redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多
2. 包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)
3. 这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,且这些操作都是原子性的
4. 与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入
磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步
2、Redis支持以下两种操作方法
1. 第一种操作方法: 操作模式
import redis r = redis.Redis(host='1.1.1.3', port=6379) r.set('foo', 'Bar') print(r.get('foo'))
2. 第二种操作方法:连接池
1)redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销
2)默认,每个Redis实例都会维护一个自己的连接池
3)可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池
import redis pool = redis.ConnectionPool(host='1.1.1.3', port=6379) r = redis.Redis(connection_pool=pool) r.set('foo', 'Bar') print(r.get('foo'))
3、Redis的操作可以分为以下几类
1. String 操作
2. Hash 操作
3. List 操作
4. Set 操作
5. Sort Set 操作
1.3 Redis对string操作(第一类)
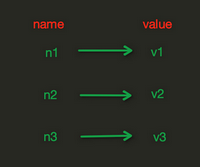
1、redis中的String在内存存储样式
注:String操作,redis中的String在在内存中按照一个name对应一个value字典形式来存储
2、set(name, value, ex=None, px=None, nx=False, xx=False)
1) ex,过期时间(秒)
2) px,过期时间(毫秒)
3) nx,如果设置为True,则只有name不存在时,当前set操作才执行
4) xx,如果设置为True,则只有name存在时,当前set操作才执行
import redis r = redis.Redis(host='1.1.1.3', port=6379) #1、打印这个Redis缓存所有key以列表形式返回:[b'name222', b'foo'] print( r.keys() ) # keys * #2、清空redis r.flushall() #3、设置存在时间: ex=1指这个变量只会存在1秒,1秒后就不存在了 r.set('name', 'Alex') # ssetex name Alex r.set('name', 'Alex',ex=1) # ssetex name 1 Alex #4、获取对应key的value print(r.get('name')) # get name #5、删除指定的key r.delete('name') # del 'name' #6、避免覆盖已有的值: nx=True指只有当字典中没有name这个key才会执行 r.set('name', 'Tom',nx=True) # setnx name alex #7、重新赋值: xx=True只有当字典中已经有key值name才会执行 r.set('name', 'Fly',xx=True) # set name alex xx #8、psetex(name, time_ms, value) time_ms,过期时间(数字毫秒 或 timedelta对象) r.psetex('name',10,'Tom') # psetex name 10000 alex #10、mset 批量设置值; mget 批量获取 r.mset(key1='value1', key2='value2') # mset k1 v1 k2 v2 k3 v3 print(r.mget({'key1', 'key2'})) # mget k1 k2 k3 #11、getset(name, value) 设置新值并获取原来的值 print(r.getset('age','100')) # getset name tom #12、getrange(key, start, end) 下面例子就是获取name值abcdef切片的0-2间的字符(b'abc') r.set('name','abcdef') print(r.getrange('name',0,2)) #13、setbit(name, offset, value) #对name对应值的二进制表示的位进行操作 r.set('name','abcdef') r.setbit('name',6,1) #将a(1100001)的第二位值改成1,就变成了c(1100011) print(r.get('name')) #最后打印结果:b'cbcdef' #14、bitcount(key, start=None, end=None) 获取name对应的值的二进制表示中 1 的个数 #15、incr(self,name,amount=1) 自增 name对应的值,当name不存在时,则创建name=amount,否则自增 #16、derc 自动减1:利用incr和derc可以简单统计用户在线数量 #如果以前有count就在以前基础加1,没有就第一次就是1,以后每运行一次就自动加1 num = r.incr('count') #17、num = r.decr('count') #每运行一次就自动减1 #每运行一次incr('count')num值加1每运行一次decr后num值减1 print(num) #18、append(key, value) 在redis name对应的值后面追加内容 r.set('name','aaaa') r.append('name','bbbb') print(r.get('name')) #运行结果: b'aaaabbbb'
3、使用setbit()和bitcount()实现最高效的统计大数量用户在线
1. setbit()和bitcount()各自作用
1. setbit()可以任意指定一个key的第多少位是1或者0(比如:setbit n 1 1 设置n的第一位是1)
2. bitcount() 可以统计某个key中共有多少个1 (比如: bitcount n 就会返回n中二进制1的个数)
3. 每个用户都会存储在数据库中,并且每个条目都会对应一个id值
2. 原理:(这里是在Redis命令行中做的测试)
1) 根据上面三条特点可以高效统计用户在线数量以及确定某个用户是否在线
2) 方法是当用户登录后就将其对应的id位设置成1
比如:tom用户在数据库中id=100,那么tom登录后就可以设置键的第一百位为1(setbit n 100 1)
3) 统计在线数量: bitcount n (可以后取到key值n中以的数量)
4) 确定某用户是否在线:比如用户在数据库中id=100getbit n 100
就可以返回n的第一百位是1就是在线,是0就是不在线
import redis r = redis.Redis(host='10.1.0.51', port=6379) r.setbit('n',10,1) #设置n的第十位是二进制的1 print(r.getbit('n',10)) #获取n的第十位是1还是0(id=10用户是否在线) print(r.bitcount('n')) #统计那种共有多上个1(用户在线数量)
1.4 redis对Hash操作,字典格式(第二类)
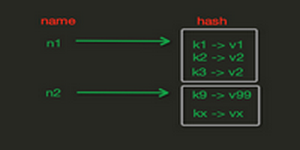
1、redis中的Hash在内存存储样式
注: hash在内存中存储可以不像string中那样必须是字典,可以一个键对应一个字典
2、Redis对Hash字典操作举例
import redis pool = redis.ConnectionPool(host='1.1.1.3', port=6379) r = redis.Redis(connection_pool=pool) #1 hset(name, key, value) name=字典名字,key=字典key,value=对应key的值 r.hset('info','name','tom') # hset info name tom r.hset('info','age','100') print(r.hgetall('info')) # hgetall info {b'name': b'tom', b'age': b'100'} print(r.hget('info','name')) # hget info name b'tom' print(r.hkeys('info')) #打印出”info”对应的字典中的所有key [b'name', b'age'] print(r.hvals('info')) #打印出”info”对应的字典中的所有value [b'tom', b'100'] #2 hmset(name, mapping) 在name对应的hash中批量设置键值对 r.hmset('info2', {'k1':'v1', 'k2': 'v2','k3':'v3'}) #一次性设置多个值 print(r.hgetall('info2')) #hgetall() 一次性打印出字典中所有内容 print(r.hget('info2','k1')) #打印出‘info2’对应字典中k1对应的value print(r.hlen('info2')) # 获取name对应的hash中键值对的个数 print(r.hexists('info2','k1')) # 检查name对应的hash是否存在当前传入的key r.hdel('info2','k1') # 将name对应的hash中指定key的键值对删除 print(r.hgetall('info2')) #3 hincrby(name, key, amount=1)自增name对应的hash中的指定key的值,不存在则创建key=amount r.hincrby('info2','k1',amount=10) #第一次赋值k1=10以后每执行一次值都会自动增加10 print(r.hget('info2','k1')) #4 hscan(name, cursor=0, match=None, count=None)对于数据大的数据非常有用,hscan可以实现分片的获取数据 # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 print(r.hscan('info2',cursor=0,match='k*')) #打印出所有key中以k开头的 print(r.hscan('info2',cursor=0,match='*2*')) #打印出所有key中包含2的 #5 hscan_iter(name, match=None, count=None) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 for item in r.hscan_iter('info2'): print(item)
1.5 redis对List操作(第三类)
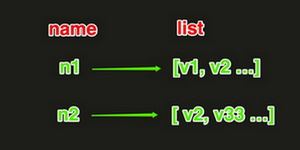
1、redis中的List在在内存中按照一个name对应一个List来存储
2、redis对列表操作举例
import redis pool = redis.ConnectionPool(host='10.1.0.51', port=6379) r = redis.Redis(connection_pool=pool) #1 lpush:反向存放 rpush正向存放数据 r.lpush('names','alex','tom','jack') # 从右向左放数据比如:3,2,1(反着放) print(r.lrange('names',0,-1)) # 结果:[b'jack', b'tom'] r.rpush('names','zhangsan','lisi') #从左向右放数据如:1,2,3(正着放) print(r.lrange('names',0,-1)) #结果:b'zhangsan', b'lisi'] #2.1 lpushx(name,value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表最左边 #2.2 rpushx(name, value) 表示从右向左操作 #3 llen(name) name对应的list元素的个数 print(r.llen('names')) #4 linsert(name, where, refvalue, value)) 在name对应的列表的某一个值前或后插入一个新值 # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据 r.rpush('name2','zhangsan','lisi') #先创建列表[zhangsan,lisi] print(r.lrange('name2',0,-1)) r.linsert('name2','before','zhangsan','wangwu') #在张三前插入值wangwu r.linsert('name2','after','zhangsan','zhaoliu') #在张三前插入值zhaoliu print(r.lrange('name2',0,-1)) #5 r.lset(name, index, value) 对name对应的list中的某一个索引位置重新赋值 r.rpush('name3','zhangsan','lisi') #先创建列表[zhangsan,lisi] r.lset('name3',0,'ZHANGSAN') #将索引为0的位置值改成'ZHANGSAN' print(r.lrange('name3',0,-1)) #最后结果:[b'ZHANGSAN', b'lisi'] #6 r.lrem(name, value, num) 在name对应的list中删除指定的值 # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个 r.rpush('name4','zhangsan','zhangsan','zhangsan','lisi') r.lrem('name4','zhangsan',1) print(r.lrange('name4',0,-1)) #7 lpop(name) 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 r.rpush('name5','zhangsan','lisi') r.rpop('name5') print(r.lrange('name5',0,-1)) #8 lindex(name, index) 在name对应的列表中根据索引获取列表元素 r.rpush('name6','zhangsan','lisi') print(r.lindex('name6',1)) #9 lrange(name, start, end) 在name对应的列表分片获取数据 r.rpush('num',0,1,2,3,4,5,6) print(r.lrange('num',1,3)) #10 ltrim(name, start, end) 在name对应的列表中移除没有在start-end索引之间的值 r.rpush('num1',0,1,2,3,4,5,6) r.ltrim('num1',1,2) print(r.lrange('num1',0,-1)) #11 rpoplpush(src, dst) 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 r.rpush('num2',0,1,2,3) r.rpush('num3',100) r.rpoplpush('num2','num3') print(r.lrange('num3',0,-1)) #运行结果:[b'3', b'100'] #12 blpop(keys, timeout) 将多个列表排列,按照从左到右去pop对应列表的元素 #timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 r.rpush('num4',0,1,2,3) r.blpop('num4',10) print(r.lrange('num4',0,-1))
1.6 redis对Set集合操作,Set集合就是不允许重复的列表(第四类)
import redis r = redis.Redis(host='10.1.0.51', port=6379) #1 sadd(name,values) name对应的集合中添加元素 #2 scard(name) 获取name对应的集合中元素个数 r.sadd('name0','alex','tom','jack') print(r.scard('name0')) #3 sdiff(keys, *args) 在第一个name对应的集合中且不在其他name对应的集合的元素集合 r.sadd('num6',1,2,3,4) r.sadd('num7',3,4,5,6) #在num6中有且在num7中没有的元素 print(r.sdiff('num6','num7')) #运行结果:{b'1', b'2'} #4 sdiffstore(dest, keys, *args) #获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中 # 将在num7中不在num8中的元素添加到num9 r.sadd('num7',1,2,3,4) r.sadd('num8',3,4,5,6) r.sdiffstore('num9','num7','num8') print(r.smembers('num9')) #运行结果: {b'1', b'2'} #5 sinter(keys, *args) 获取多一个name对应集合的交集 r.sadd('num10',4,5,6,7,8) r.sadd('num11',1,2,3,4,5,6) print(r.sinter('num10','num11')) #运行结果: {b'4', b'6', b'5'} #6 sinterstore(dest, keys, *args) 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中 r.sadd('num12',1,2,3,4) r.sadd('num13',3,4,5,6) r.sdiffstore('num14','num12','num13') print(r.smembers('num14')) #运行结果: {b'1', b'2'} #7 sismember(name, value) 检查value是否是name对应的集合的成员 r.sadd('name22','tom','jack') print(r.sismember('name22','tom')) #8 smove(src, dst, value) 将某个成员从一个集合中移动到另外一个集合 r.sadd('num15',1,2,3,4) r.sadd('num16',5,6) r.smove('num15','num16',1) print(r.smembers('num16')) #运行结果: {b'1', b'5', b'6'} #9 spop(name) 从集合的右侧(尾部)移除一个成员,并将其返回 r.sadd('num17',4,5,6) print(r.spop('num17')) #10 srandmember(name, numbers) 从name对应的集合中随机获取 numbers 个元素 r.sadd('num18',4,5,6) print(r.srandmember('num18',2)) #11 srem(name, values) 在name对应的集合中删除某些值 r.sadd('num19',4,5,6) r.srem('num19',4) print(r.smembers('num19')) #运行结果: {b'5', b'6'} #12 sunion(keys, *args) 获取多一个name对应的集合的并集 r.sadd('num20',3,4,5,6) r.sadd('num21',5,6,7,8) print(r.sunion('num20','num21')) #运行结果: {b'4', b'5', b'7', b'6', b'8', b'3'} #13 sunionstore(dest,keys, *args) # 获取多个name对应的集合的并集,并将结果保存到dest对应的集合中 r.sunionstore('num22','num20','num21') print(r.smembers('num22')) #运行结果: {b'5', b'7', b'3', b'8', b'6', b'4'} #14 sscan(name, cursor=0, match=None, count=None) # sscan_iter(name, match=None, count=None) #同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
1.7 redis对有序集合操作(第五类)
1、对有序集合使用介绍
1. 有序集合,在集合的基础上,为每元素排序
2. 元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序
2、redis操作有序集合举例
import redis pool = redis.ConnectionPool(host='10.1.0.51', port=6379) r = redis.Redis(connection_pool=pool) #1 zadd(name, *args, **kwargs) 在name对应的有序集合中添加元素 r.zadd('zz', n1=11, n2=22,n3=15) print(r.zrange('zz',0,-1)) #[b'n1', b'n3', b'n2'] print(r.zrange('zz',0,-1,withscores=True)) #[(b'n1', 11.0), (b'n3', 15.0), (b'n2', 22.0)] #2 zcard(name) 获取name对应的有序集合元素的数量 #3 zcount(name, min, max) 获取name对应的有序集合中分数 在 [min,max] 之间的个数 r.zadd('name01', tom=11,jack=22,fly=15) print(r.zcount('name01',1,20)) #4 zincrby(name, value, amount) 自增name对应的有序集合的 name 对应的分数 #5 zrank(name, value) 获取某个值在 name对应的有序集合中的排行(从 0 开始) r.zadd('name02', tom=11,jack=22,fly=15) print(r.zrank('name02','fly')) #6 zrem(name, values) 删除name对应的有序集合中值是values的成员 r.zadd('name03', tom=11,jack=22,fly=15) r.zrem('name03','fly') print(r.zrange('name03',0,-1)) # [b'tom', b'jack'] #7 zremrangebyrank(name, min, max)根据排行范围删除 r.zadd('name04', tom=11,jack=22,fly=15) r.zremrangebyrank('name04',1,2) print(r.zrange('name04',0,-1)) # [b'tom'] #8 zremrangebyscore(name, min, max) 根据分数范围删除 r.zadd('name05', tom=11,jack=22,fly=15) r.zremrangebyscore('name05',1,20) print(r.zrange('name05',0,-1)) #9 zremrangebylex(name, min, max) 根据值返回删除 #10 zscore(name, value) 获取name对应有序集合中 value 对应的分数 #11 zinterstore(dest, keys, aggregate=None) #11测试过代码报错,未解决 #获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX r.zadd('name09', tom=11,jack=22,fly=15) r.zadd('name10', tom=12,jack=23,fly=15) r.zinterstore('name11',2,'name09','name10') print(r.zrange('name11',0,-1))
# 127.0.0.1:6379> zadd name222 11 zhangsan 12 lisi (integer) 2 # 127.0.0.1:6379> zrange name222 0 -1 1) "zhangsan" 2) "lisi" # 127.0.0.1:6379> zadd name333 11 zhangsan 12 lisi (integer) 2 # 127.0.0.1:6379> zrange name333 0 -1 1) "zhangsan" 2) "lisi" # 127.0.0.1:6379> zinterstore name444 2 name222 name333 (integer) 2 # 127.0.0.1:6379> zrange name444 0 -1 withscores 1) "zhangsan" 2) "22" 3) "lisi" 4) "24"
1.8 redis其他常用操作
1、redis其它命令
import redis pool = redis.ConnectionPool(host='1.1.1.3', port=6379) r = redis.Redis(connection_pool=pool) #1 查看当前Redis所有key print(r.keys('*')) #2 delete(*names) 删除Redis对应的key的值 r.delete('num16') #3 exists(name) 检测redis的name是否存在 print(r.exists('name09')) #4 keys(pattern='*') 根据模型获取redis的name # KEYS * 匹配数据库中所有 key 。 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo print(r.keys(pattern='name*')) #打印出Redis中所有以name开通的key #5 expire(name ,time) 为某个redis的某个name设置超时时间 r.expire('name09',1) # 1秒后就会删除这个key值name09 #6 rename(src, dst) 对redis的name重命名为 r.rename('num13','num13new')
2、redis中切换数据库操作
# redis 127.0.0.1:6379> SET db_number 0 # 默认使用 0 号数据库 # redis 127.0.0.1:6379> SELECT 1 # 使用 1 号数据库 # redis 127.0.0.1:6379[1]> GET db_number # 已经切换到 1 号数据库,注意 Redis 现在的命令提符多了个 [1] # redis 127.0.0.1:6379[1]> SET db_number 1 # 设置默认使用 1 号数据库 # redis 127.0.0.1:6379[1]> GET db_number # 获取当前默认使用的数据库号 #1 move(name, db)) 将redis的某个值移动到指定的db下(对方库中有就不移动) 127.0.0.1:6379> move name0 4 #2 type(name) 获取name对应值的类型 127.0.0.1:6379[4]> type name0
1.9 redis的管道使用(通过管道向指定db传送数据)
1、管道作用
1. redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作
2. 如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令
2、通过管道向指定db传送数据
import redis,time pool = redis.ConnectionPool(host='10.1.0.51', port=6379,db=5) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) pipe.set('name', 'alex') time.sleep(4) pipe.set('role', 'sb') pipe.execute() #只有执行这里上面两条才会一起执行,才能到db5中看到这两个值 # 127.0.0.1:6379[5]> select 5 # OK # 127.0.0.1:6379[5]> keys * # 1) "name" # 2) "role"
1.10 发布订阅(一对多的广播)
1、作用图解
作用:发布订阅的作用就是在发布者(publish)中发送数据,可以在所有接收者(sub)中都可以接收到相同数据

2、发布订阅实例各文件讲解
1)这里的实例发布订阅包含以下三个文件:
redisHelper.py : 定义了一个类,在类例规定了如何发布,如何订阅,和频道是多少
RedisSub.py : Redis接收端,在这里直接导入redisHelper.py中定义的类,调用类中的接收数据的方法
RedisPub.py : Redis发送端,在这里直接导入redisHelper.py中定义的类,调用类中的发送数据的方法
2)实验效果时,直接运行RedisSub.py,会卡在接收数据的地方,等待发送方发送数据
3)然后运行RedisPub.py进行发送数据,可以看到所有在运行的接收者RedisSub.py都可以接收到这个消息
import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='10.1.0.51') #连接Redis服务器 self.chan_sub = 'fm104.5' #发布频道'fm104.5' self.chan_pub = 'fm104.5' #接收频道也是'fm104.5' #发消息 def public(self, msg): self.__conn.publish(self.chan_pub, msg) #直接调用Redis的chan_pub方法发消息 print('pub') return True #收消息 def subscribe(self): print('sub') pub = self.__conn.pubsub() #开始订阅,仅仅相当于打开收音机 pub.subscribe(self.chan_sub) #调频道 pub.parse_response() #准备接收 return pub #再调用一次pub.parse_response()才会接收
from redisHelper import RedisHelper #这里的RedisHelper()就是redisHelper中定义的类 obj = RedisHelper() #实例化一个对象RedisHelper redis_sub = obj.subscribe() while True: msg= redis_sub.parse_response() #如果Public发送有数据就打印,没有就卡住 print(msg)
from redisHelper import RedisHelper obj = RedisHelper() obj.public('hello')
1.11 redis持久化
1、redis持久化介绍
1. 由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了
2. redis提供两种方式进行持久化:
第一种:RDB (将Redis中数据定时dump到硬盘)
第二种:AOF (将Reids的操作日志以追加的方式写入文件)
2、二者原理
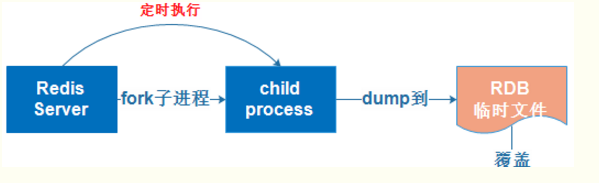
1. RDB持久化原理
1. RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘
2. 实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储
2. AOF持久化原理
1. AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

3、RDB优缺点介绍(快照)
1. RDB优点
1. 整个Redis数据库将只包含一个文件,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2. 性能最大化,它仅需要fork出子进程,由子进程完成持久化工作,极大的避免服务进程执行IO操作了。
3. 相比于AOF机制,如果数据集很大,RDB的启动效率会更高
2. RDB缺点
1. RDB容易丢数据,因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失
2. RDB通过fork子进程来完成持久化的,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
4、AOF优缺点介绍(镜像)
1. AOF优点
1. 数据安全性高,Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步
2. 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容
3. 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中
4. AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建
2. AOF缺点
1. 对于相同数量的数据集而言,AOF文件通常要大于RDB文件,RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
2. AOF在运行效率上往往会慢于RDB
1.12 在/etc/redis.conf文件中配置持久化
1、在 /etc/redis.conf 中配置使用RDP
1. RDP配置选项(这3个选项都屏蔽,则rdb禁用))
# save 900 1 // 900内,有1条写入,则产生快照 # save 300 1000 // 如果300秒内有1000次写入,则产生快照 # save 60 10000 // 如果60秒内有10000次写入,则产生快照
2. RDP其他配置
# stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入? 主进程不停止 容易造成数据不一致 # rdbcompression yes // 导出的rdb文件是否压缩 如果rdb的大小很大的话建议这么做 # Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性 验证版本是不是一致 # dbfilename dump.rdb //导出来的rdb文件名 # dir ./ //rdb的放置路径
2、在 /etc/redis.conf 中配置使用AOF
# appendonly no // 是否打开aof日志功能 aof跟 rdb都打开的情况下 # appendfsync always // 每1个命令,都立即同步到aof. 安全,速度慢 # appendfsync everysec // 折衷方案,每秒写1次 # appendfsync no // 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快, # no-appendfsync-on-rewrite yes: // 正在导出rdb快照的过程中,要不要停止同步aof # auto-aof-rewrite-percentage 100 //aof文件大小比起上次重写时的大小,增长率100%时,重写 缺点 刚开始的时候重复重写多次 # auto-aof-rewrite-min-size 64mb //aof文件,至少超过64M时,重写 测试使用: redis-benchmark -n 10000 表示 执行请求10000次,执行ls 发现出现 rdb 跟 aof文件。appendonly.aof dump.rdb
3、注意的事项
注: 在dump rdb过程中,aof如果停止同步,会不会丢失?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
注: aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里,以解决aof日志过大的问题.
问: 如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: aof
问: 2种是否可以同时用?
答: 可以,而且推荐这么做
问: 恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行
1.13 redis主从复制
参考博客: https://www.cnblogs.com/kevingrace/p/5685332.html
1、介绍
1. 和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。
2. 为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构。
3. Redis主从复制可以根据是否是全量分为全量同步和增量同步。
下图为级联结构:
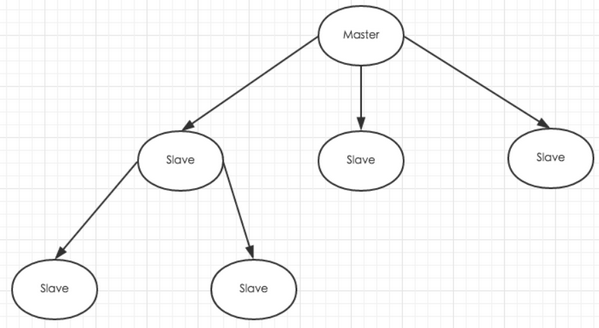
2、全量同步
注:Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
7)完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。

3、增量同步
1. Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
2. 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
4、Redis主从同步策略
1. 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
2. 当然,如果有需要,slave 在任何时候都可以发起全量同步。
3. redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
5、注意点
1. 如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增宕机。
1.14 redis的五大数据类型实现原理
1、string
1. 字符串是Redis最基本的数据类型,不仅所有key都是字符串类型,其它几种数据类型构成的元素也是字符串。
2. 编码:int 编码是用来保存整数值,raw编码是用来保存长字符串,而embstr是用来保存短字符串。
注:字符串的长度不能超过512M。
2、list(列表)
1. list 列表,它是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表结构。
2. 编码: 可以是 ziplist(压缩列表) 和 linkedlist(双端链表)。
3、哈希对象
1. 哈希对象的键是一个字符串类型,值是一个键值对集合。
2. 编码:哈希对象的编码可以是 ziplist 或者 hashtable。
4、集合对象
1. 集合对象 set 是 string 类型(整数也会转换成string类型进行存储)的无序集合。
5、有序集合
1. 与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
2. 编码:有序集合的编码可以是 ziplist 或者 skiplist。
1.15 redis事物与分布式锁
1、redis事物
1. 严格意义来讲,Redis的事务和我们理解的传统数据库(如mysql)的事务是不一样的;
2. Redis的事务实质上是命令的集合,在一个事务中要么所有命令都被执行,要么所有事物都不执行。
需要注意的是:
1.Redis的事务没有关系数据库事务提供的回滚(rollback),所以开发者必须在事务执行失败后进行后续的处理;
2.如果在一个事务中的命令出现错误,那么所有的命令都不会执行;
3.如果在一个事务中出现运行错误,那么正确的命令会被执行。
2、redis原子操作
1. 原子操作是指不会被线程调度机制打断的操作
2. 这种操作一旦开始,就会一直运行到结束,中间不会切换任何进程
3、分布式锁
1. 分布式锁本质是占一个坑,当别的进程也要来占坑时发现已经被占,就会放弃或者稍后重试
2. 占坑一般使用 setnx(set if not exists)指令,只允许一个客户端占坑
3. 先来先占,用完了在调用del指令释放坑
> setnx lock:codehole true .... do something critical .... > del lock:codehole
4. 但是这样有一个问题,如果逻辑执行到中间出现异常,可能导致del指令没有被调用,这样就会陷入死锁,锁永远无法释放
5. 为了解决死锁问题,我们拿到锁时可以加上一个expire过期时间,这样即使出现异常,当到达过期时间也会自动释放锁
> setnx lock:codehole true > expire lock:codehole 5 .... do something critical .... > del lock:codehole
6. 这样又有一个问题,setnx和expire是两天指令而不是原子指令
7. 为了治理上面乱象,在redis 2.8中加入了set指令的扩展参数,使setnx和expire指令可以一起执行
> set lock:codehole true ex 5 nx ''' do something ''' > del lock:codehole