分析目的(或者说要达到的效果)
实现一个小说下载器,输入小说的名字然后抓取小说的全部章节,制作成文档。
需要的知识:使用BeautifulSoup或正则解析网页,使用requests下载网页。
搜索小说
直接用小说的站内搜索
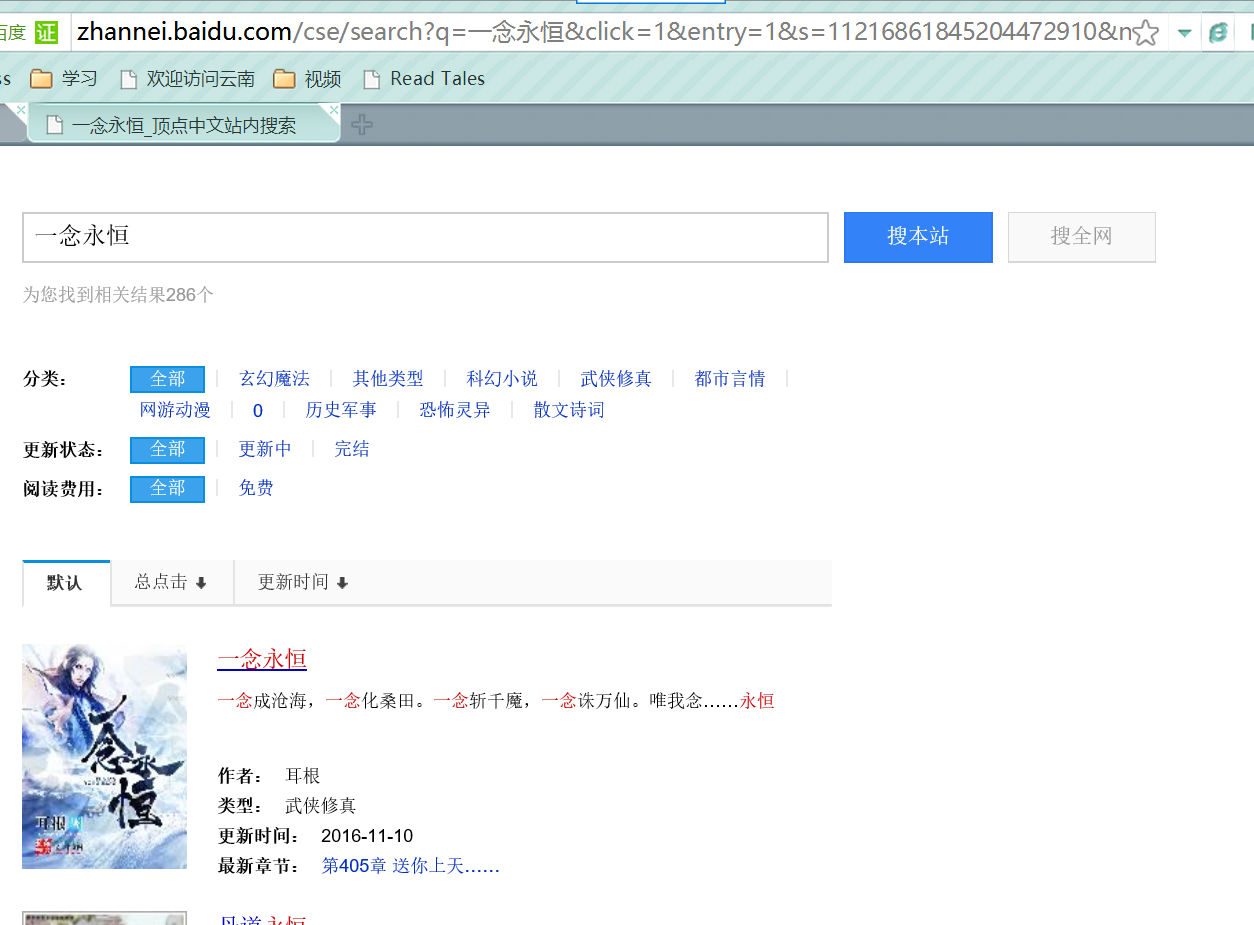
使用小说网站的搜索页面:http://so.sanjiangge.com/cse/search 这个网站用的是百度的站内搜索
需要提交的数据有q:我们要搜索的文字,clik和entry顾名思义,而s应该是百度站内搜索的用户码吧。
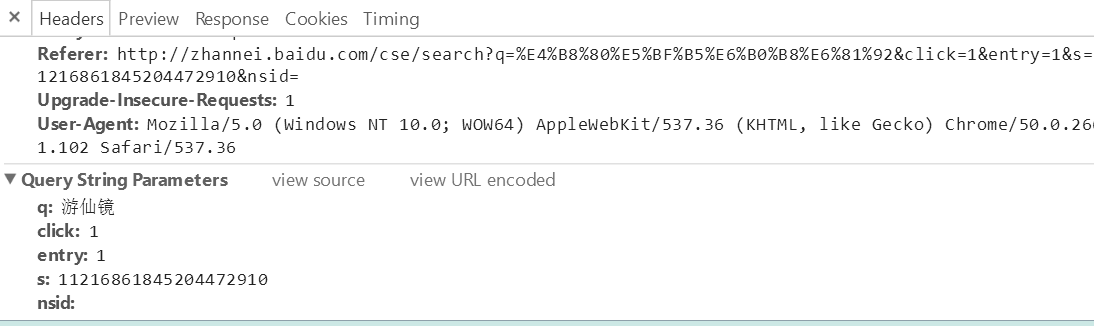
import requests
def directory(name):
params = {"q":name, "click":1, "entry":1, "s":781863708123447302, "nsid":""}
url = "http://so.sanjiangge.com/cse/search"
print(url)
r = requests.get(url,params=params)
r.encoding = "utf-8"
return r.text
返回的是一个HTML文件。注意必须把网页的编码方式改为utf-8。
解析网页

先把第一步的网页搜索结果提取出来,使用BeautifulSoup模块找到我们要找到书的链接。
先看看网页的结构
<div class="result-item result-game-item">
<div class="result-game-item-pic">
<a cpos="img" href="http://www.dingdianzw.com/book/2430.html" class="result-game-item-pic-link" target="_blank" style="110px;height:150px;">
<img src="http://www.dingdianzw.com/files/article/image/2/2430/2430s.jpg" alt="<em>一念</em><em>永恒</em>" class="result-game-item-pic-link-img"
onerror="$(this).attr('src', '/static/img/novel-noimg.jpg')" >
</a>
</div>
<div class="result-game-item-detail">
<h3 class="result-item-title result-game-item-title">
<a cpos="title" href="http://www.dingdianzw.com/book/2430.html" title="一念永恒" class="result-game-item-title-link" target="_blank">
<em>一念</em><em>永恒</em>
</a>
</h3>
<p class="result-game-item-desc"><em>一念</em>成沧海,<em>一念</em>化桑田。<em>一念</em>斩千魔,<em>一念</em>诛万仙。唯我念……<em>永恒</em></p>
<div class="result-game-item-info">
<p class="result-game-item-info-tag">
<span class="result-game-item-info-tag-title preBold">作者:</span>
<span>
耳根
</span>
</p>
<p class="result-game-item-info-tag">
<span class="result-game-item-info-tag-title preBold">类型:</span>
<span class="result-game-item-info-tag-title">武侠修真</span>
</p>
<p class="result-game-item-info-tag">
<span class="result-game-item-info-tag-title preBold">更新时间:</span>
<span class="result-game-item-info-tag-title">2016-11-10</span>
</p>
<p class="result-game-item-info-tag">
<span class="result-game-item-info-tag-title preBold">最新章节:</span>
<a cpos="newchapter" href="http://www.dingdianzw.com/chapter/2430_5101830.html" class="result-game-item-info-tag-item" target="_blank">第405章 送你上天……</a>
</p>
</div>
</div>
</div>
上面就包含了我们需要的所有信息(封面,书名,书的地址,最近章节等等)我们只需要排第一的搜索选项中的书名和书的地址,使用BeautfulSoup或正则表达式提取出来。
if r.url == "http://www.baidu.com/search/error.html":
return False
else:
bsObj = BeautifulSoup(r.text, "lxml").findAll("a", {"cpos":"title"})[0]
return (bsObj["href"],bsObj.get_text()[1:-1])
加入搜索错误的检测,如果错误页面将会重定向到百度的错误页面。并且把书的链接提取出来。
接着再来看看书页面的源代码
<dd><a href="23410363.html" title="外传1 柯父。">外传1 柯父。</a></dd><dd><a href="23410364.html" title="外传2 楚玉嫣。">外传2 楚玉嫣。</a></dd><dd><a href="23410365.html" title="外传3 鹦鹉与皮冻。">外传3 鹦鹉与皮冻。</a></dd><dd><a href="23410366.html" title="第一章 他叫白小纯">第一章 他叫白小纯</a></dd>
<dd><a href="23410367.html" title="第二章 火灶房">第二章 火灶房</a></dd><dd><a href="23410369.html" title="第三章 六句真言">第三章 六句真言</a></dd><dd><a href="23410370.html" title="第四章 炼灵">第四章 炼灵</a></dd><dd><a href="23410371.html" title="第五章 万一丢了小命咋办">第五章 万一丢了小命咋办</a></dd>
<dd><a href="23410372.html" title="第六章 灵气上头">第六章 灵气上头</a></dd><dd><a href="23410373.html" title="第七章 龟纹认主">第七章 龟纹认主</a></dd><dd><a href="23410374.html" title="第八章 我和你拼了!">第八章 我和你拼了!</a></dd><dd><a href="23410375.html" title="第九章 延年益寿丹">第九章 延年益寿丹</a></dd>
<dd><a href="23410376.html" title="第十章 师兄别走">第十章 师兄别走</a></dd><dd><a href="23410377.html" title="第十一章 侯小妹">第十一章 侯小妹</a></dd><dd><a href="23410379.html" title="第十二章 篱笆墙上">第十二章 篱笆墙上</a></dd><dd><a href="23410380.html" title="第十三章 你也来吧!">第十三章 你也来吧!</a></dd>
<dd><a href="23410382.html" title="第十四章 三师兄?三师姐?">第十四章 三师兄?三师姐?</a></dd><dd><a href="23411581.html" title="第十五章 不死长生功!">第十五章 不死长生功!</a></dd><dd><a href="23411582.html" title="第十六章 心细入微">第十六章 心细入微</a></dd><dd><a href="23411583.html" title="第十七章 小乌龟">第十七章 小乌龟</a></dd>
<dd><a href="23411584.html" title="第十八章 引领气氛!">第十八章 引领气氛!</a></dd><dd><a href="23411585.html" title="第十九章 白鼠狼的传说">第十九章 白鼠狼的传说</a></dd><dd><a href="23411586.html" title="第二十章 一地鸡毛">第二十章 一地鸡毛</a></dd><dd><a href="23411587.html" title="第二十一章 小纯哥哥……">第二十一章 小纯哥哥……</a></dd>
<dd><a href="23411588.html" title="第二十二章 师姐放心!">第二十二章 师姐放心!</a></dd><dd><a href="23411589.html" title="第二十三章 偷鸡狂魔">第二十三章 偷鸡狂魔</a></dd><dd><a href="23411590.html" title="第二十四章 你是谁">第二十四章 你是谁</a></dd><dd><a href="23411591.html" title="第二十五章 不死铁皮!">第二十五章 不死铁皮!</a></dd>
<dd><a href="23411592.html" title="第二十六章 灵尾鸡好吃么?">第二十六章 灵尾鸡好吃么?</a></dd><dd><a href="23411593.html" title="第二十七章 这……这是竹子?">第二十七章 这……这是竹子?</a></dd><dd><a href="23411594.html" title="第二十八章 压力才是动力">第二十八章 压力才是动力</a></dd><dd><a href="23411595.html" title="第二十九章 举重若轻">第二十九章 举重若轻</a></dd>
<dd><a href="23411596.html" title="第三十章 来吧!">第三十章 来吧!</a></dd><dd><a href="23411597.html" title="第三十一章 耻辱啊!">第三十一章 耻辱啊!</a></dd><dd><a href="23411598.html" title="第三十二章 运气逆天">第三十二章 运气逆天</a></dd><dd><a href="23411599.html" title="第三十三章 打倒白小纯!">第三十三章 打倒白小纯!</a></dd>
<dd><a href="23411600.html" title="第三十四章 草木碾压">第三十四章 草木碾压</a></dd><dd><a href="23411601.html" title="第三十五章 又见许宝财">第三十五章 又见许宝财</a></dd><dd><a href="23411602.html" title="第三十六章 小乌龟称霸!">第三十六章 小乌龟称霸!</a></dd><dd><a href="23411603.html" title="第三十七章 举轻若重">第三十七章 举轻若重</a></dd>
目标是把书的章节名和章节链接提取出来
def contents(url, b_name):
link = url[:-10]
print (link)
links = []
r = requests.get(url)
r.encoding = "utf-8"
bsObj = BeautifulSoup(r.text, "lxml").findAll("dd")
for i in bsObj:
i = link + i.a["href"] #把内链合并成完整的链接。
links.append(i)
现在让我们来看看章节页面的源代码是怎样的吧
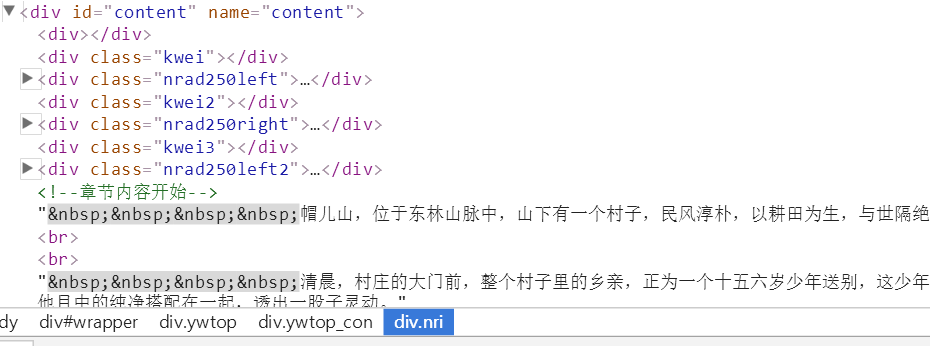
<div class="kwei"></div><div class="nrad250left"><script>show_kw1();</script></div>
<div class="kwei2"></div><div class="nrad250right"><script>show_kw2();</script></div>
<div class="kwei3"></div><div class="nrad250left2"><script>show_kw3();</script></div>
<!--章节内容开始--> 帽儿山,位于东林山脉中,山下有一个村子,民风淳朴,以耕田为生,与世隔绝。<br /><br /> 清晨,村庄的大门前,整个村子里的乡亲,正为一个十五六岁少年送别,这少年瘦弱,但却白白净净,看起来很是乖巧,衣着尽管是寻常的青衫,可却洗的泛白,穿在这少年的身上,与他目中的纯净搭配在一起,透出一股子灵动。<br /><br /> 他叫白小纯。<br /><br />
提取出一个章节的全部文字,返回一个包含全部文字的字符串
def section(url):
r = requests.get(url)
r.encoding = "gbk"
bsObj = BeautifulSoup(r.text, "lxml").find(id="content")
print (bsObj)
结果:
<div id="content" name="content">
<div></div>
<div class="kwei"></div><div class="nrad250left"><script>show_kw1();</script></div>
<div class="kwei2"></div><div class="nrad250right"><script>show_kw2();</script></div>
<div class="kwei3"></div><div class="nrad250left2"><script>show_kw3();</script></div>
<!--章节内容开始--> 帽儿山,位于东林山脉中,山下有一个村子,民风淳朴,以耕田为生,与世隔绝。<br/><br/>。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。略 D410211<!--章节内容结束-->
<div>
</div>
<script src="/js/cpc2.js" type="text/javascript"></script>
<div class="bottem">
<div class="adhtml"><script>show_htm2();</script></div>
<p>小技巧:按 回车[Enter]键 返回章节目录,按 ←键 回到上一章,按 →键 进入下一章。</p>
<a href="23410365.html">上一章 </a>← <a href="index.html" title="一念永恒最新章节目录">章节目录</a> →
<a href="23410367.html">下一章</a>
<p> </p>
<div class="adhtml"><script>show_htm3();</script></div>
</div>
</div>
这里有一个问题,返回的内容包含太多不需要的东西,接下来配合使用正则表达式我觉得会容易一些
def section(url):
r = requests.get(url)
r.encoding = "gbk"
bsObj = BeautifulSoup(r.text, "lxml").find(id="content")
print (str(bsObj))
content = re.compile(r"<!--章节内容开始-->(.*)<!--章节内容结束-->").search(str(bsObj))#把章节内容提取出来
content = re.compile("<br/><br/>").sub("
", content.group(1))#把网页的<br/><br/>替换成换行符
return content
然后汇总全部章节内容。写入TXT文件。
def contents_load(books, f_name = "电子书"):
contents = []
contents.append(f_name+"
")
for i in books:
contents.append(i[1]+"
")
contents.append(section(i[0]))
print(i[1], "下载成功")
f = open(f_name+".txt", "w", encoding="utf-8")
f.writelines(contents)
效果:
第一章 一觉醒来整个世界都变了 下载成功
第二章 果然我穿越的方式不对吗? 下载成功
第三章 孙思邈是我“道弟” 下载成功
第四章 原来穿越者也可以被打脸 下载成功
第五章 一觉醒来世界又变了 下载成功
。。。。。
现在爬虫在网络良好的状况下基本可以正常运行了,不过下载速度有点慢,接下来我们使用多线程加快速度,再使用面对对象的程序设计。注意文件编码方式需要指定utf-8。
多线程参看菜鸟教程
import requests
from bs4 import BeautifulSoup
import re
import threading
class load_book(object):
def __init__(self,book_name):
self.b_name = book_name
self.b_link = self.b_link_load()
self.b_directory = self.directory()
self.content = {}
def b_link_load(self):
params = {"q": self.b_name, "click": 1, "entry": 1, "s": 7818637081234473025, "nsid": ""}
url = "http://so.sanjiangge.com/cse/search"
r = requests.get(url, params=params)
r.encoding = "utf-8"
if r.url == "http://www.baidu.com/search/error.html":
return False
else:
bsObj = BeautifulSoup(r.text, "lxml").findAll("a", {"cpos": "title"})[0]
return bsObj["href"]
def directory(self):
link = self.b_link[:-10]
links = []
r = requests.get(self.b_link)
r.encoding = "gbk"
bsObj = BeautifulSoup(r.text, "lxml").findAll("dd")
for i in bsObj:
url = link + i.a["href"]
links.append((url, i.get_text()))
return links
def section_load(self, links):
for i in links:
r = requests.get(i[0])
r.encoding = "gbk"
bsObj = BeautifulSoup(r.text, "lxml").find(id="content")
content = re.compile(r"<!--章节内容开始-->(.*)<!--章节内容结束-->").search(str(bsObj)) # 把章节内容提取出来
content = re.compile("<br/><br/>").sub("
", content.group(1)) # 把网页的<br/><br/>替换成换行符
self.content[i[1]]=content[:-8]
def contents_load(self,loops=10):
threads = []
nloops = range(loops)
task_list = []
task_size = len(self.b_directory)//loops+1
for i in nloops:#分割任务
try:
task_list.append(self.b_directory[i*task_size:(i+1)*task_size])
except:
task_list.append(self.b_directory[i*task_size:])
for i in nloops:
t = threading.Thread(target=self.section_load, args=([task_list[i]]))
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
def write_txt(self):
f = open(self.b_name, "w",encoding="utf-8")
f.write(" "*20+self.b_name+"
")
for i in self.b_directory:
title = "
"+" "*20+i[1]+"
"
f.write(title)
f.write(self.content[i[1]])
f.close()
if __name__ == '__main__':
book = load_book("游仙镜")
book.contents_load(20)
book.write_txt()
运行效果;
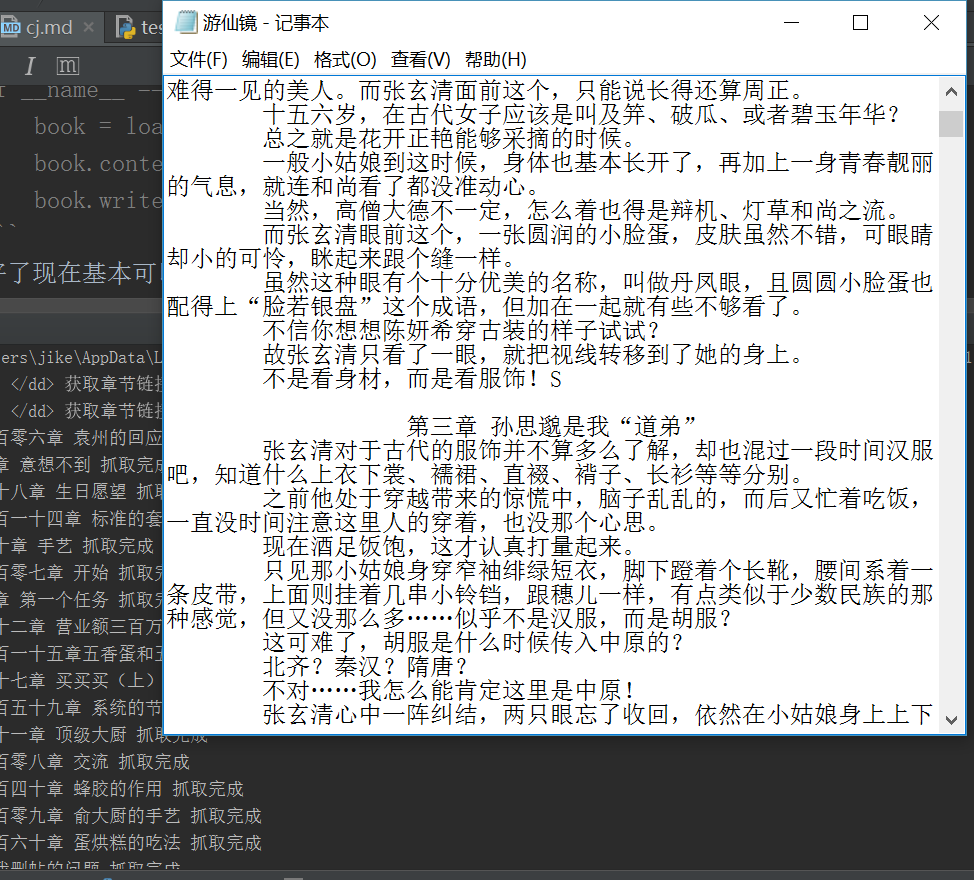
嗯,具体运行过程中hui出现网络异常,以及部分章节为空页的情况,为了使程序正常运行还需要进行错误的处理。
import requests
from bs4 import BeautifulSoup
import re
import threading
import time
class load_book(object):
def __init__(self,book_name):
self.b_name = book_name
self.b_link = self.b_link_load()
self.b_directory = self.directory()
self.content = {}
def b_link_load(self):
params = {"q": self.b_name, "click": 1, "entry": 1, "s": 7818637081234473025, "nsid": ""}
url = "http://so.sanjiangge.com/cse/search"
try:
r = requests.get(url, params=params)
r.encoding = "utf-8"
if r.url == "http://www.baidu.com/search/error.html":
return False
else:
bsObj = BeautifulSoup(r.text, "lxml").findAll("a", {"cpos": "title"})[0]
return bsObj["href"]
except:
print("获取目录失败,一秒后重试,失败链接:",url,params)
time.sleep(1)
self.b_link_load()
def directory(self):
link = self.b_link[:-10]
links = []
r = requests.get(self.b_link)
r.encoding = "gbk"
bsObj = BeautifulSoup(r.text, "lxml").findAll("dd")
for i in bsObj:
try:
url = link + i.a["href"]
links.append((url, i.get_text()))
except TypeError:
print(i,"获取章节链接错误")
return links
def section_load(self, links):
for i in links:
try:
r = requests.get(i[0])
r.encoding = "gbk"
bsObj = BeautifulSoup(r.text, "lxml").find(id="content")
content = re.compile(r"<!--章节内容开始-->(.*)<!--章节内容结束-->").search(str(bsObj)) # 把章节内容提取出来
content = re.compile("<br/><br/>").sub("
", content.group(1)) # 把网页的<br/><br/>替换成换行符
self.content[i[1]] = content[:-8]
print(i[1],"抓取完成")
except (TypeError,AttributeError):
print("*"*10,"%s章节错漏"% i[1])
except :
print("*"*10,"%s抓取错误,重试中"% i[1])
links.insert(0,i)
def contents_load(self,loops=10):
threads = []
nloops = range(loops)
task_list = []
task_size = len(self.b_directory)//loops+1
for i in nloops:#分割任务
try:
task_list.append(self.b_directory[i*task_size:(i+1)*task_size])
except:
task_list.append(self.b_directory[i*task_size:])
for i in nloops:
t = threading.Thread(target=self.section_load, args=([task_list[i]]))
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
def write_txt(self):
print("开始制作txt文档")
f = open(self.b_name+".txt", "w", encoding="utf-8")
f.write(" " * 20 + self.b_name + "
")
for i in self.b_directory:
try:
title = "
" + " " * 20 + i[1] + "
"
f.write(title)
f.write(self.content[i[1]])
except KeyError:
print("*" * 10, "缺失章节为:", i[1])
f.close()
if __name__ == '__main__':
book = load_book("美食供应商")
book.contents_load(10)
book.write_txt()
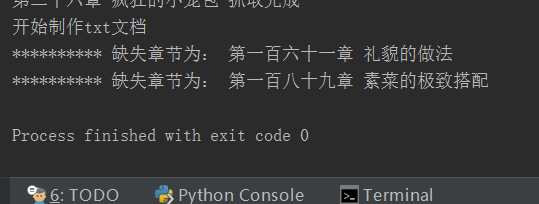
好了现在基本可以正常使用了,不过还有很多不足。希望可以和更多的人交流。
可以改进的功能
- 使用多个站点进行搜索
- 缺失章节使用其他站点数据尝试弥补缺失
- 制作图形界面
- 加入进度条
- 加入发送邮件功能,使制作的电子书可以直接发送到kindle上