Seaborn的分类图分为三类,将分类变量每个级别的每个观察结果显示出来,显示每个观察分布的抽象表示,以及应用统计估计显示的权重趋势和置信区间:
- 第一个包括函数swarmplot()和stripplot()
- 第二个包括函数boxplot()和violinplot()
- 第三个包括函数barplot()和pointplt()
导入所需要的库:
import numpy as np import matplotlib.pyplot as plt import seaborn as sns sns.set(style='darkgrid',color_codes=True) import pandas as pd import matplotlib as mpl
导入所需要的数据:
iris=sns.load_dataset('iris') tips=sns.load_dataset('tips') titanic=sns.load_dataset('titanic') tips.head()
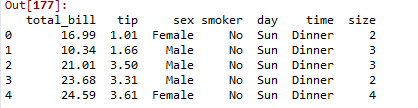
一.Other变量&类别变量(striplot和searmplot)
当我们的数据中有两个变量,其中包含一个类别变量.另外一个可以是类别,也可以是其他的变量,这个时候我们常常会用stripplot()函数来绘制二者的关系.
常见于用来分析label为连续型变量(回归问题中的label),而我们特征中出现了分类l数据.
而针对这些问题,在seaborn中最常用的函数有striplot和searmplot函数.
sns.stripplot(x='day',y='total_bill',data=tips) #
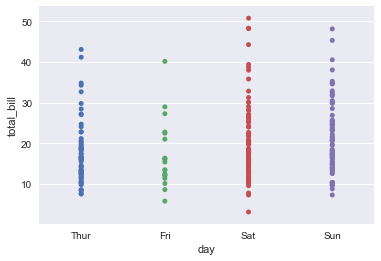
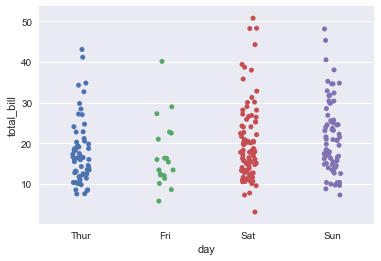
但是我们很快便发现一个较为严重的问题,就是这样无法很好体现我们label在某个点的分布情况,可能一个点附近有大量的点,但上面那个图我们却是很难发现的(覆盖太严重),为了解决这个问题,我们采用random jitter,将同一个地方的点随机的分开,因为是随机的,所以每次运行都会不一样,具体的结果如下所示,这样我们就很容易的看到分类变量对于label的影响.
sns.stripplot(x='day',y='total_bill',data=tips,jitter=True)
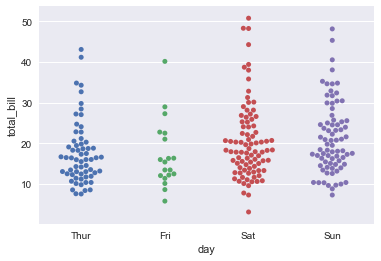
虽然stripplot的jitter = True在一定程度上缓解了该问题,但是还有一个更好的函数swarmplot,该函数利用一种特定算法使得我们的能更好的看到数据的分布情况.
函数swarmplot(),它使用避免重叠点的算法将分类轴上的每个散点图点定位
sns.swarmplot(x='day',y='total_bill',data=tips)
还可以传入hue参数添加多个嵌套的分类变量。高于分类轴上的颜色和位置时冗余的,现在每个都提供有两个变量之一的信息:
sns.swarmplot(x='day',y='total_bill',hue='sex',data=tips)
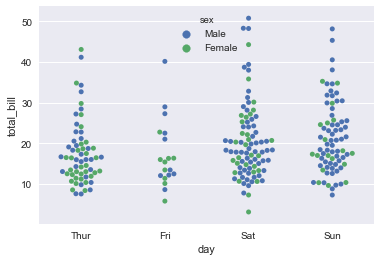
使用这些图,将分类变量放在垂直轴上是非常有用的(当类别名称相对较长或有很多类别时,这一点特别有用)。 您可以使用orient关键字强制定向,但通常可以从传递给x和/或y的变量的数据类型推断绘图方向:
sns.swarmplot(x='total_bill',y='day',hue='sex',data=tips)
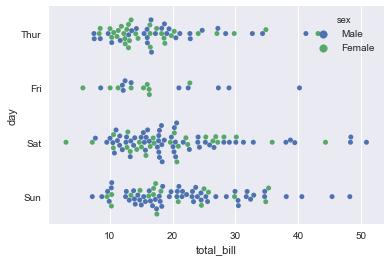
Stripplot VS Swarmplot
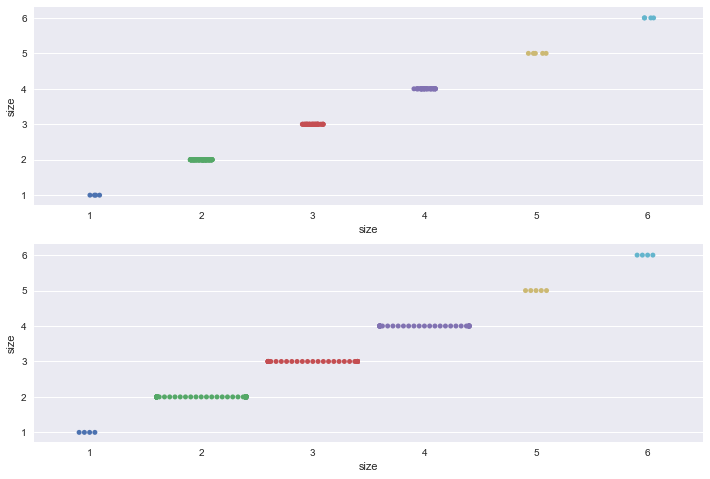
① swarmplot的优势在当我们的两个变量都是分类变量的时候更加明显.具体的参考下图即可.
② swarmplot的缺点则是非常耗时,当数据量非常大的时候并不适用.
sns.stripplot(x='size',y='size',data=tips,jitter=True,ax=ax1) sns.swarmplot(x='size',y='size',data=tips,ax=ax2) plt.show()
二.类别特征对应的特征分布(boxplot和violinplot)
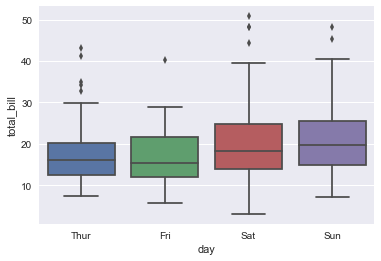
在某种程度上,类别型数据的可视化可能会无法反应某类中信息的一个分布情况,例如上面的day和total_bill的情况,在很多情况下较难看出究竟哪一天total_bill的好一点,尤其在两个类别中total都相近的时候(Sta,Sun),那此时我们就需要另外一些更好的可视化工具来帮助我们完成这些任务.
而针对这些问题,在seaborn中最常见的函数有Boxplots和Violinplot函数.
sns.boxplot(x='day',y='total_bill',data=tips)
注意: 因为hue是和x,y变量嵌套的,当我们使用hue变量的时候,它会被分割出来并产生"位移",也就是我们看到的下面的一条线被分割成为多条线的情况. 有时为了防止位移,我们可以设置dodge=False可以抵消位移.
具体实例:
sns.boxplot(x="day", y="total_bill", hue="size", data=tips, dodge=False);
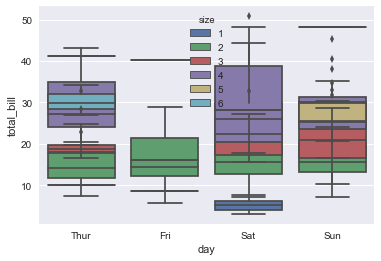
sns.boxplot(x="day", y="total_bill", hue="size", data=tips);
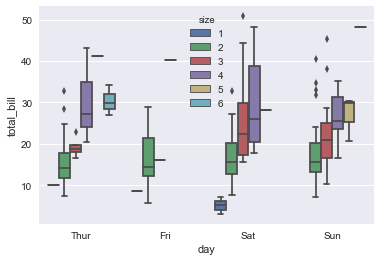
如上图所示,选择将dodge设置为False,每个变量都没有位移,即每个分类x轴对应的y都只有一个类型,那么此时的位移反而会使得我们的图变得很难看.
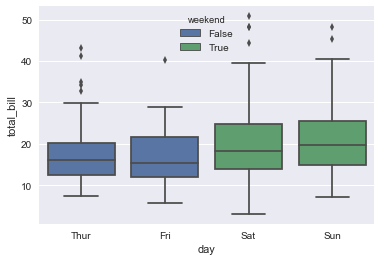
tips["weekend"] = tips["day"].isin(["Sat", "Sun"]) sns.boxplot(x="day", y="total_bill", hue="weekend", data=tips, dodge=False);
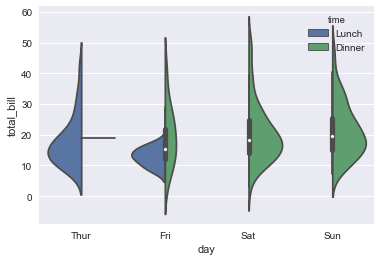
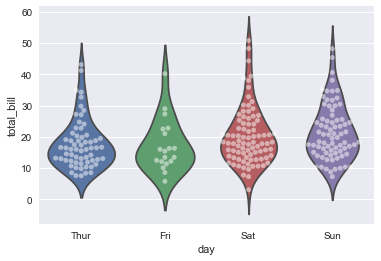
Violinplot(提琴图)
violinplot(),它结合了箱体图和分布教程中描述的核心密度估计过程.
sns.violinplot(x="day", y="total_bill", hue="time", split=True, data=tips);
将swarmplot()或者swarmplot()与violinplot()或boxplot()结合使用可以显示每个观察结果以及分布的摘要:
sns.violinplot(x="day", y="total_bill", data=tips, inner=None) sns.swarmplot(x="day", y="total_bill", data=tips, color="w", alpha=.5);
三.类别特征的统计信息
上面的几种关于分类l特征的可视化技术主要用以观察数据的分布的情况,但是却总感觉缺了一些东西,究竟是什么呢?作为做过一些数据分析的我们很容易就明白,我们不能仅仅只看数据的一个外在的表现,我们需要一些工具将它的一些内在信息(主要是统计信息)反应出来,例如某类数据的总的个数,均值等情况.
此处主要介绍barplot(条形图)、countplot与piontplot(点图)
3.1. barplot(条形图)
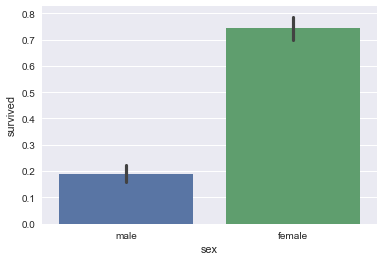
barplot需要注意的是纵轴y默认的是计算的对应cate的均值
sns.barplot(x="sex", y="survived", data=titanic);
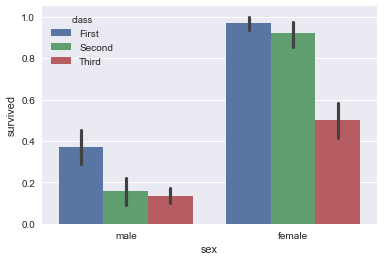
sns.barplot(x='sex',y='survived',hue='class',data=titanic)
3.2 countplot(计数图)
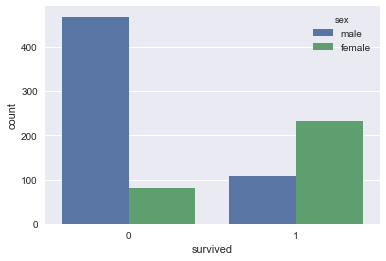
barplot会默认将纵轴计算为均值,这在二分类的时候非常有帮助,因为均值就是为1的概率,但是是不是具有统计意义,我们不能只看概率还得看个数,这个时候我们就得用到countplot函数了,coutplot函数不能同时使用x,y所以如果想要统计某个cate变量对应的变量的个数最好用hue进行分开.例子如下:
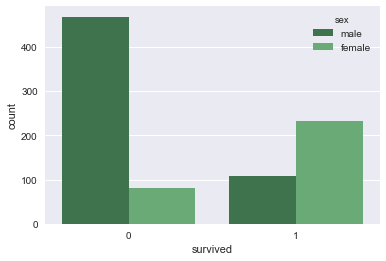
sns.countplot(hue='sex',x='survived',data=titanic)
sns.countplot(hue='sex',x='survived',data=titanic,palette='Greens_d')
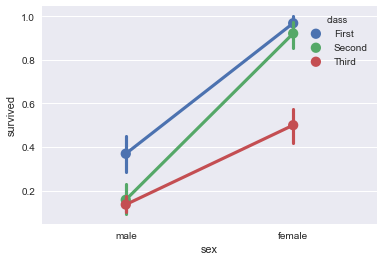
3.3. Pointplot
pointplot()函数提供了可视化相同信息的另一种风格。该函数还对另一轴的高度估计值进行编码,而不是显示一个完整的柱型,它只绘制点估计和置信区间。另外,这个函数和Barplot很相似,y特征都是计算对应的概率,不同的是该函数更加丰富,它还会对相同的hue特征进行连接,得到特征的变化曲线.
sns.pointplot(x="sex", y="survived", hue="class", data=titanic);
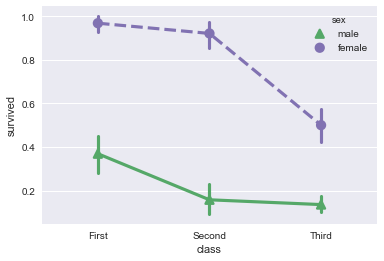
为了使能够在黑白中重现的图形,可以使用不同的标记和线条样式来展示不同hue类别的层次:
sns.pointplot(x="class", y="survived", hue="sex", data=titanic, palette={"male": "g", "female": "m"}, markers=["^", "o"], linestyles=["-", "--"]);
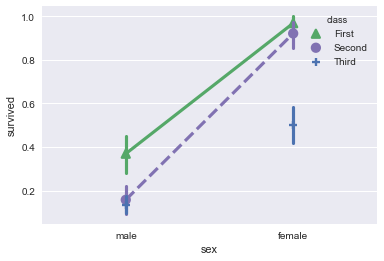
sns.pointplot(x="sex", y="survived", hue="class", data=titanic, palette={"First": "g", "Second": "m", "Third":'b'}, markers=["^", "o","+"], linestyles=["-", "--",""]);
绘制“宽格式”数据
虽然使用“长格式”或“整洁”数据是优选的,但是这些功能也可以应用于各种格式的“宽格式”数据,包括pandas DataFrame或二维numpy数组阵列。这些对象应该直接传递给数据参数:
sns.boxplot(data=iris,orient="h");
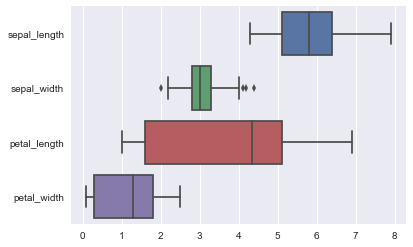
此外,这些函数接受Pandas或numpy对象的向量,而不是DataFrame中的变量
sns.violinplot(x=iris.species, y=iris.sepal_length);
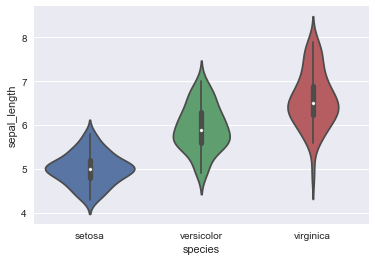
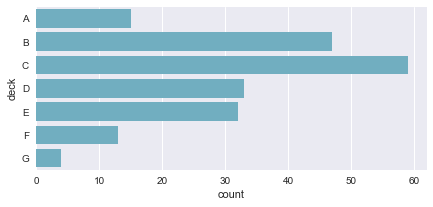
为了控制由上述功能制作的图形的大小和形状,您必须使用matplotlib命令自己设置图形。 当然,这也意味着这些图块可以和其他种类的图块一起在一个多面板的绘制中共存:
f, ax = plt.subplots(figsize=(7, 3)) sns.countplot(y="deck", data=titanic, color="c");
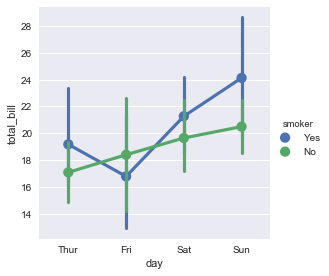
四. 绘制多层面板分类图
此处我们介绍两个更加高级的方法.这些方法将上面的方法集中在一起,可是随时调用.上述的方法可以通过kind = ""进行随时的切换.
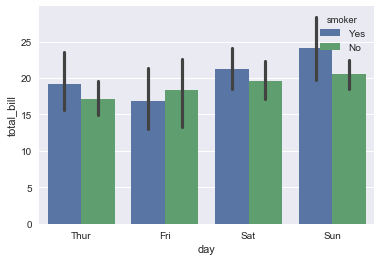
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips);
如果我们希望barplot的形式的话,将kind设置为bar即可.为了对比,此处我们也绘制barplot的形式,是不是发现和barplot一样的结果.
sns.factorplot(x="day", y="total_bill", hue="smoker", kind = 'bar', data=tips);
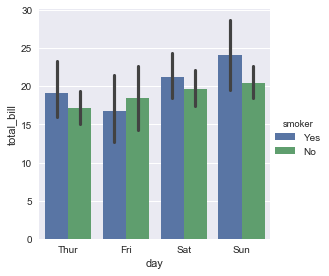
sns.barplot(x="day", y="total_bill", hue="smoker", data=tips)
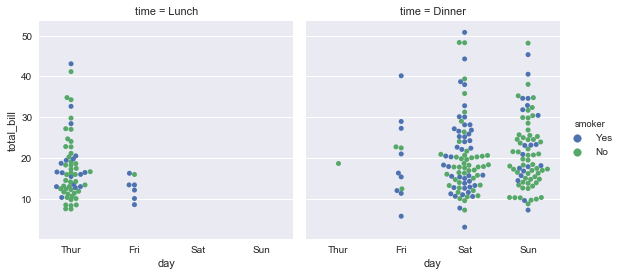
使用factorplot()的主要优点是很容易调用"facet"展开更多其他分类变量:
sns.factorplot(x="day", y="total_bill", hue="smoker", col="time", data=tips, kind="swarm");
sns.factorplot(x="time", y="total_bill", hue="smoker", col="day", data=tips, kind="box", size=4, aspect=.5);
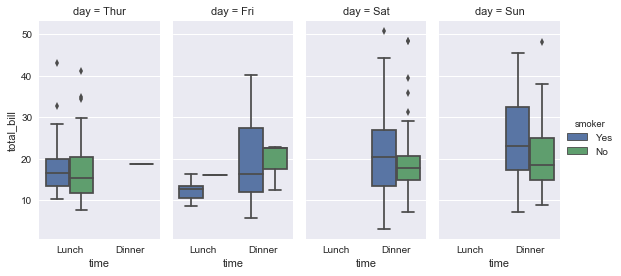
任何一种图形都可以画出来。基于FacetGrid的工作原理,要更改图形的大小和形状,需要指定适用于每个方面的size和aspect参数:
sns.factorplot(x="time", y="total_bill", hue="smoker", col="day", data=tips, kind="box", size=4, aspect=.5);
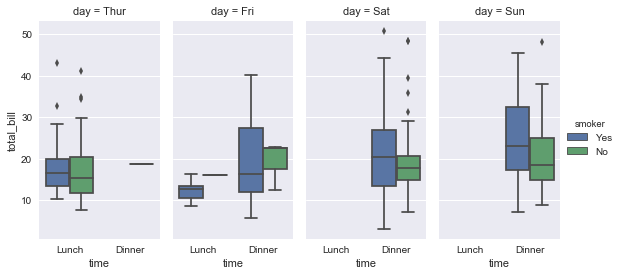
重要的是要注意,你也可以直接使用boxplot()和FacetGrid来制作这个图。但是,必须特别注意确保分类变量的顺序在每个方面实施,方法是使用具有Categorical数据类型的数据或通过命令和hue_order。
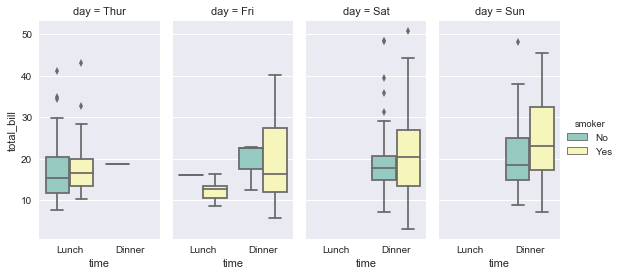
sns.factorplot(x="time", y="total_bill", hue="smoker",hue_order=["No","Yes"] ,col="day", data=tips, kind="box", size=4, aspect=.5, palette="Set3");
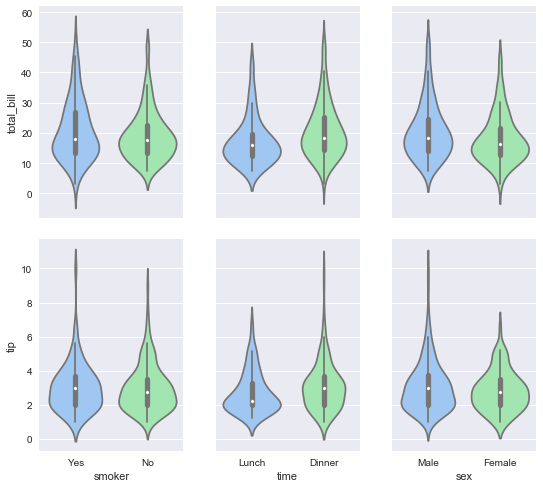
g = sns.PairGrid(tips, x_vars=["smoker", "time", "sex"], y_vars=["total_bill", "tip"], aspect=.75, size=3.5) g.map(sns.violinplot, palette="pastel");
plt.show()
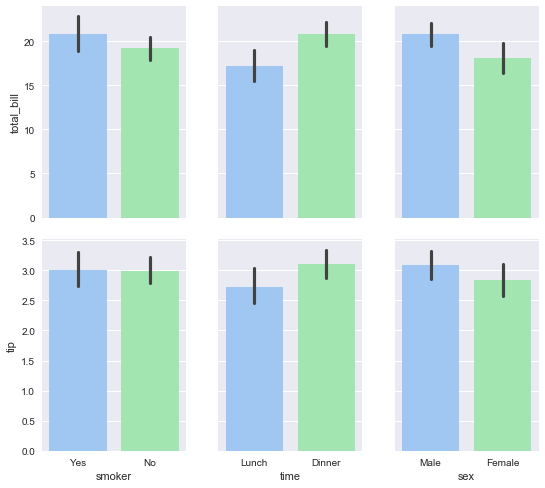
g = sns.PairGrid(tips,x_vars=["smoker", "time", "sex"],y_vars=["total_bill", "tip"],aspect=.75, size=3.5) g.map(sns.barplot, palette="pastel");
plt.show()
五. 总结
本文介绍了一些用于查看categorical变量与其他变量(一般是label)之间关系的一些可视化技巧,其中主要涉及的包有:
- 查看cate变量与一些其他变量(连续或者cate):Stripplot,Swarmplot(一般是cate对应变量出现overlap比较严重的时候使用)
- 查看cate变量对应的其他变量分布:Boxplot,Violinplot
- 查看cate变量对应变量(含一些统计特征):Barplot,Countplot,Pointplot
- 集成的函数:Factorplot和PairGrid.
seaborn.factorplot函数的所有参数说明,方便参考:
seaborn.factorplot(x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=<function mean>, ci=95, n_boot=1000, units=None, order=None, hue_order=None, row_order=None, col_order=None, kind='point', size=4, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs)
Parameters:
- x,y,hue 数据集变量 变量名
- date 数据集 数据集名
- row,col 更多分类变量进行平铺显示 变量名
- col_wrap 每行的最高平铺数 整数
- estimator 在每个分类中进行矢量到标量的映射 矢量
- ci 置信区间 浮点数或None
- n_boot 计算置信区间时使用的引导迭代次数 整数
- units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
- order, hue_order 对应排序列表 字符串列表
- row_order, col_order 对应排序列表 字符串列表
- kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点(具体图形参考文章前部的分类介绍)
- size 每个面的高度(英寸) 标量
- aspect 纵横比 标量
- orient 方向 "v"/"h"
- color 颜色 matplotlib颜色
- palette 调色板 seaborn颜色色板或字典
- legend hue的信息面板 True/False
- legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False
- share{x,y} 共享轴线 True/False
- facet_kws FacetGrid的其他参数 字典
参考:
[1] http://seaborn.pydata.org/tutorial/distributions.html
[2] http://seaborn.pydata.org/tutorial/categorical.html
[3] http://seaborn.pydata.org/tutorial/regression.html
[4] https://zhuanlan.zhihu.com/p/27683042
[5] https://www.kesci.com/apps/home/project/59f687e1c5f3f511952baca0