1、缓存雪崩
缓存雪崩就是Redis 的大量热点数据同时过期(失效),因为设置了相同的过期时间,刚好这个时候Redis请求的并发量又很大,就会导致所有的请求落到数据库。
缓存雪崩的解决方案:
(1)加互斥锁或者使用队列,针对同一个key只允许一个线程到数据库查询
(2)缓存定时预先更新,避免同时失效
(3)通过加随机数,使key在不同的时间过期
(4)缓存永不过期或双缓存
2、缓存穿透
因为每次查询的值都不存在导致的Redis失效的情况,我们就把它叫做缓存穿透。

缓存穿透分为两种情况:
(1)多次重复查询相同的值
这种情况可以缓存空数据或特殊字符,使不存在的数据不必一直查缓存,并发高的情况下可以加分布式锁,避免同一时间点数据库请求打满。
(2)每次都查询不同的值
这个问题的关键在于如何判断要查询的值在不在数据库中,也是一个经典问题:如何在海量元素中(例如10亿无序、不定长、不重复)快速判断一个元素是否存在?
2.1、第一种方案:
使用位图(bitMap),它是一个有序数组,只有0和1,0表示不存在,1表示存在。

要通过有序的位置来标识10亿个元素是否存在,需要将元素值与数组下标做一个映射,通过映射转换成下标的时候,应该在数组中尽可能均匀分布。可以通过哈希函数进行映射,比如MD5、SHA-1等常见的哈希算法。如下6个元素经过哈希算法和位运算得到相
应的下标:

但是会存在一个问题,就是不同元素得到的哈希值一样,这样就会有相同的下标(如上图的Tom和Mic),这种情况也就哈希碰撞。要避免哈希碰撞,可以通过扩大位图容量或是增加哈希计算次数,但是位图容量太大会产生存储空间过大,哈希计算次数太多消
耗时间等问题,所以要对二者进行平衡,这就有了第二种方案。
2.2、第二种方案:基于内存的布隆过滤器
(1)布隆过滤器工作原理
首先,布隆过滤器的本质第一种方案提到的一个位数组,和若干个哈希函数。

如上:集合里面有3个元素,要把它存到布隆过滤器里面去,应该怎么做?首先是a元素,这里我们用3次计算。b、c元素也一样。元素已经存进去之后,现在我要来判断一个元素在这个容器里面是否存在,就要使用同样的三个函数进行计算。比如d元素,我用第
一个函数f1计算,发现这个位置上是1,没问题。第二个位置也是1,第三个位置也是1 。如果经过三次计算得到的下标位置值都是1,这种情况下,能不能确定d 元素一定在这个容器里面呢? 实际上是不能的。比如这张图里面,这三个位置分别是把a,b,c存进去的时
候置成1的,所以即使d元素之前没有存进去,也会得到三个1,判断返回true。所以,这个是布隆过滤器的一个很重要的特性,因为哈希碰撞不可避免,所以它会存在一定的误判率。
布隆过滤器的特点:
1、如果布隆过滤器判断元素在集合中存在,不一定存在
2、如果布隆过滤器判断不存在,一定不存在
(2)Guava中布隆过滤器的实现
谷歌的Guava里面就提供了一个现成的布隆过滤器。
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>21.0</version> </dependency>
创建布隆过滤器:
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),insertions);
布隆过滤器提供的存放元素的方法是put(),判断元素是否存在的方法是mightContain()。
布隆过滤器把误判率默认设置为0.03,也可以在创建的时候指定。
public static<T> BloomFilter<T> create(Funnel<? super T>funnel,long expectedInsertions){
return create(funnel,expectedInsertions,0.03D);
}
位图的容量是基于元素个数和误判率计算出来的:
long numBits = optimalNumOfBits(expectedInsertions,fpp);
根据位数组的大小,进一步计算出了哈希函数的个数:
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions,numBits);
存储100万个元素只占用了0.87M的内存,生成了5个哈希函数。
(3)布隆过滤器在项目中的使用
布隆过滤器的工作位置:
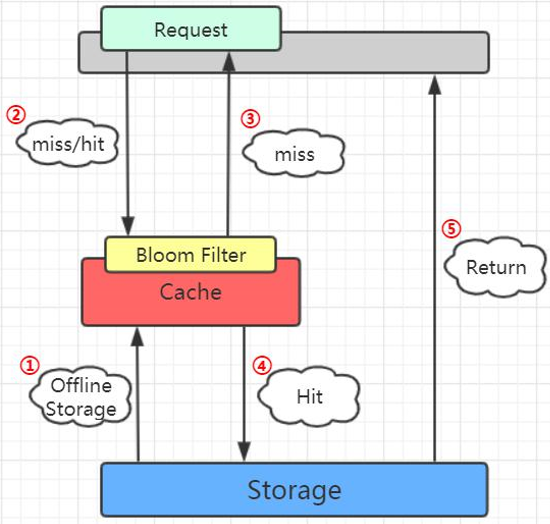
因为要判断数据库的值是否存在,所以第一步是加载数据库所有的数据。在去Redis查询之前,先在布隆过滤器查询,如果bf说没有,那数据库肯定没有,也不用去查了。如果bf说有,才走之前的缓存和数据库查询流程。
(4)布隆过滤器其他应用场景
布隆过滤器解决的问题是:如何在海量元素中快速判断一个元素是否存在。所以除了解决缓存穿透的问题之外,我们还有很多其他的用途。
比如爬数据的爬虫,爬过的url我们不需要重复爬,在几十亿的url里面,判断一个url是不是已经爬过了
还有邮箱服务器,发送垃圾邮件的账号把它们叫做spamer,在这么多的邮箱账号里面,怎么判断一个账号是不是 spamer 等等一些场景,都可以用到布隆过滤器。
3.3、第三种方案: Redis布隆过滤器
基于内存的布隆过滤器不适用于分布式,且无法存储大量数据。
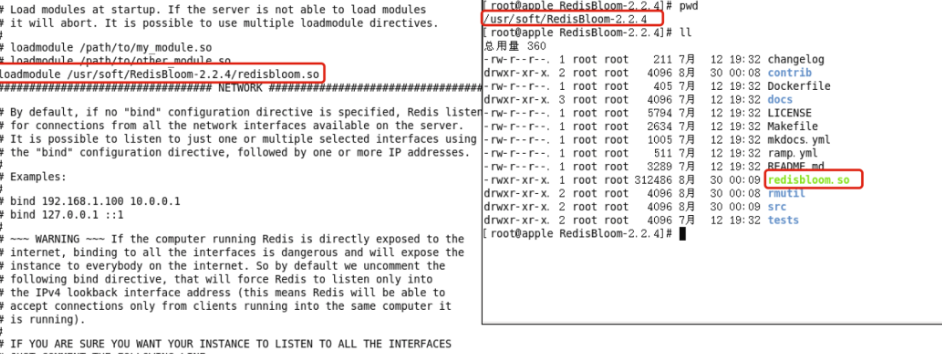
(1)redis布隆过滤器的安装
下载地址github:https://github.com/RedisBloom/RedisBloom
然后编译:

先把 Redis 给停掉,在 redis.conf 里面添加一行命令->加载模块:
(2)使用
布隆过滤器添加和查询命令:

添加的lua脚本:
local bloomName = KEYS[1] local value = KEYS[2] --bloomFilter local result_1 = redis.call('BF.ADD',bloomName,value) return result_1
查询的lua脚本:
local bloomName = KEYS[1] local value = KEYS[2] --bloomFilter local result_1 = redis.call('BF.EXISTS',bloomName,value) return result_1