0、首先创建三台虚拟机,在此基础上搭建分布式集群
创建虚拟机:Mac上安装VMware&搭载CentOS7
三台设备:
ip hostname
192.168.77.100 server001
192.168.77.110 server002
192.168.77.120 server003
版本:zookeeper-3.4.9,hadoop-2.7.6,hbase-1.7.1
1、关闭防火墙,否则集群间无法通信
systemctl status firewalld //查看防火墙状态 systemctl stop firewalld //关闭防火墙 systemctl disable firewalld //禁用防火墙
2、这里我们是从网上将资源下载到Mac主机上,然后再将资源拷贝到虚拟机上
scp -p 22 ware/hadoop-2.7.6.tar.gz root@192.168.77.120:/var/opt
3、设置主机名和配置主机hosts
设置主机名:
hostnamectl set-hostname server001
查看 vi /etc/hostname
配置主机hosts:
vi /etc/hosts
添加如下内容
192.168.77.100 server001 192.168.77.110 server002 192.168.77.120 server003
4、三台设置间设置ssh免密登录
首先确保开启了ssh,开启后会在/root目录下有.ssh文件夹
每台分别执行ssh-keygen -t rsa,连续按3个回车,在.ssh目录下生成id_rsa和id_rsa.pub
然后分发秘钥:
在server001上执行 ssh-copy-id server002和ssh-copy-id server003,其他两台上同理。
至此三台之间就可以通过 ssh server001/002/003进行免密登录了。
5、安装zookeeper
下载地址:http://archive.apache.org/dist/zookeeper/(下载3.4.9)
注意:有的高版本执行会报:找不到或无法加载主类 org.apache.zookeeper.ZooKeeperMain
解压文件:
tar –zxf zookeeper-3.4.7.tar.gz
(1)修改zoo.cfg配置
cd /zookeeper/conf cp zoo_sample.cfg zoo.cfg vi zoo.cfg 修改:dataDir=/var/opt/zookeeper/data
末尾添加:
server.1=192.168.77.100:2555:3555 server.2=192.168.77.110:2555:3555 server.3=192.168.77.120:2555:3555
2555是leader端口,3555是follower端口,可以修改。
(2)将server001上的zookeeper文件拷贝到server002和server002上
scp -r /var/opt/zookeeper root@server002:/var/opt
(3)在每台设备上创建id
创建data目录:mkdir data
cd data
vi myid(server001上是1,server002上是2,server003上是3)
(4)分别在三台机器上启动zk
./zkServer.sh start
查看启动状态:
./zkServer.sh status
6、部署Hadoop集群
(1)下载的Hadoop文件解压:(1-7都在一个节点上操作)
tar -zxf hadoop-2.7.6.tar.gz
(2)编辑hadoop-env.sh
cd /var/opt/hadoop-2.7.6/etc/hadoop vi hadoop-env.sh
修改:
export JAVA_HOME=/var/opt/jdk1.8.0_181
export HADOOP_CONF_DIR=/var/opt/hadoop-2.7.6/etc/hadoop
生效:source hadoop-env.sh
(3)编辑core-site.xml
<configuration> <!-- 指定namenode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://server001:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/var/opt/hadoop-2.7.6/tmp</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 root --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
(4)编辑hdfs-site.xml
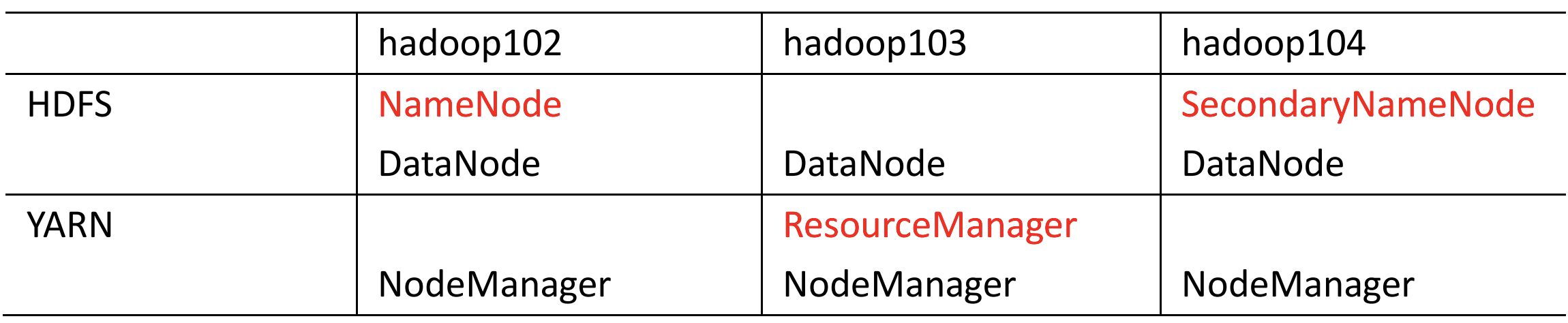
<configuration> <!-- nn web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>server001:9870</value> </property> <!-- 2nn web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>server003:9868</value> </property> </configuration>
(5)编辑mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration> <!-- mapreduce的工作模式:yarn --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
(6)编辑yarn-site.xml
<configuration> <!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>server002</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://server001:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
(7)编辑slaves
vi /var/opt/hadoop-2.7.6/etc/hadoop/slaves
添加:
server001
server002
server003
(8)把配置好的hadoop拷贝到其他节点
scp -r hadoop-2.7.6 root@server002:/var/opt/
scp -r hadoop-2.7.6 root@server003:/var/opt/
(9)配置环境变量
vi /etc/profile
末尾添加:
export HADOOP_HOME=/var/opt/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效:source /etc/profile
(10)群起集群
vi /var/opt/hadoop-2.7.6/etc/hadoop/workers
添加:
server001
server002
server003
(11)启动Hadoop集群
hdfs namenode -format
start-dfs.sh
• 在配置了 ResourceManager 的节点()启动 YARN
start-yarn.sh
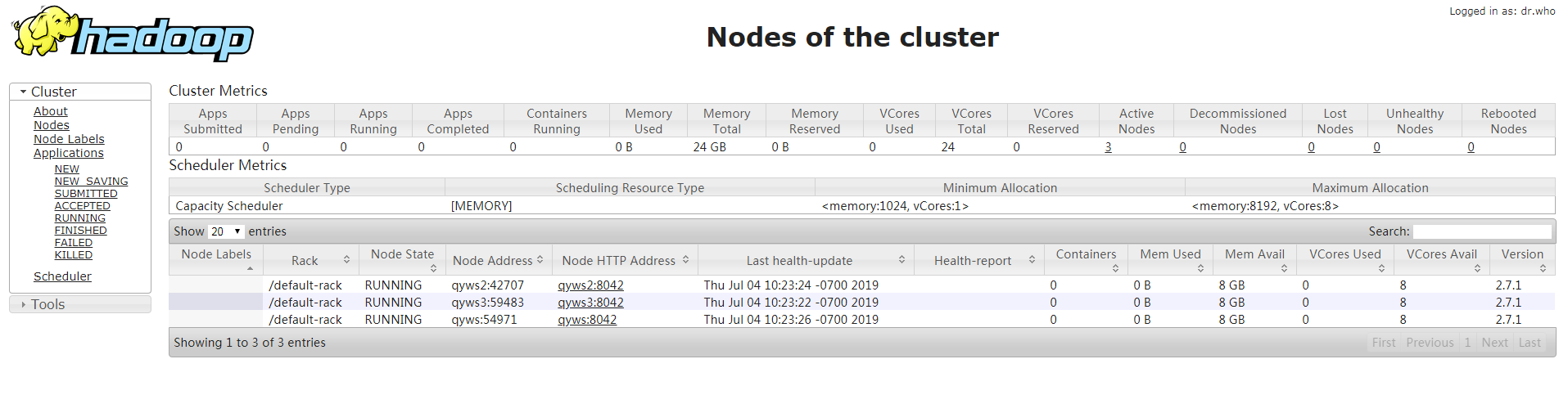
• web端查看
查看HDFS的namenode:http://192.168.77.100:9870
7、部署HBase
先解压文件:
(1)hbase-env.sh 修改内容:
export JAVA_HOME=/var/opt/jdk_1.8.1_144
export HBASE_MANAGES_ZK=false
(2)hbase-site.xml 修改内容:
<configuration> <!-- 这个目录是 RegionServer 的共享目录,用来持久化 HBase。特别注意的是 hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致 --> <property> <name>hbase.rootdir</name> <value>hdfs://server001:8020/hbase</value> </property> <!-- 指定是分布式模式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定master端口,默认也是16000 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <!-- 本地文件系统的临时文件夹。可以修改到一个更为持久的目录上。(/tmp会在重启时清除) --> <property> <name>hbase.tmp.dir</name> <value>/var/opt/hbase-1.7.1/tmp</value> </property> <!-- 列出全部的 ZooKeeper 的主机,用逗号隔开 --> <property> <name>hbase.zookeeper.quorum</name> <value>server001,server002,server003</value> </property> <!-- ZooKeeper 快照的存储位置,默认值为 /tmp --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/var/opt/zookeeper/zkData</value> </property> </configuration>
(3)配置regionservers
server001
server002
server003
(4)软连接 hadoop 配置文件到 HBase(当然也可以拷贝过来)
ln -s /var/opt/hadoop-2.7.6/etc/hadoop/core-site.xml /var/opt/hbase-1.7.1/conf/core-site.xml
ln -s /var/opt/hadoop-2.7.6/etc/hadoop/hdfs-site.xml /var/opt/hbase-1.7.1/conf/hdfs-site.xml
(5)将配置好的hbase拷贝到其他两台机器
scp -r hbase-1.7.1 root@server002:/var/opt
scp -r hbase-1.7.1 root@server003:/var/opt
(6)启动Hbase集群
先启动三台zookeeper
sh /var/opt/zookeeper/bin/zkServer.sh start
然后在server001上启动HDFS
start-dfs.sh
在server002上启动yarn(也可以不启动)
start-yarn.sh
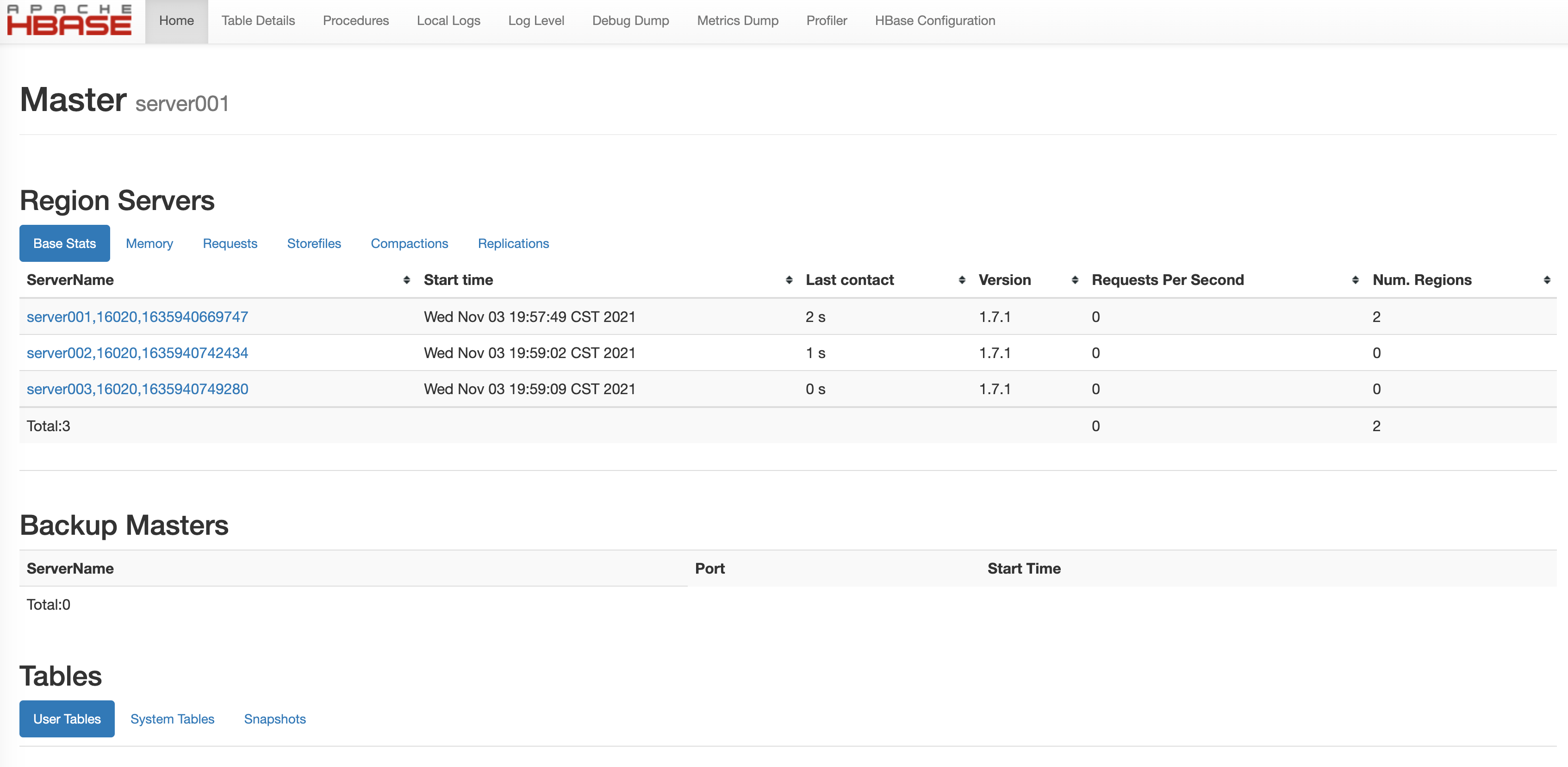
查看启动状态,jps或是浏览器访问:192.168.77.100:9870

最后在server001上启动hbase,先启动HMaster,再启动HRegionServer
sh /var/opt/hbase-1.7.1/bin/hbase-daemon.sh start master
sh /var/opt/hbase-1.7.1/bin/hbase-daemon.sh start regionserver
查看启动状态,jps或是浏览器访问:192.168.77.100:16010