一.使用VMvare创建两个虚拟机,我使用的是ubuntu17版本的,并关闭全部虚拟机的防火墙
1.我们把用于主节点的虚拟机名称设为master(按自己的喜好创建),把用于从节点的虚拟机名称设为slave1
- 修改主机名的命令:sudo vim /etc/hostname
- 把原主机名ubuntu改为master(在从主机上则改为slave1)
2.为了虚拟机之间能ping通,需要修改虚拟机的ip地址(这里以在master机器操作为例子,从节点的虚拟机也要进行一致的操作)
- 命令:sudo vim /etc/hosts
把/etc/hosts中yangcx-virtual-machine修改为刚刚改过的主机名master,同时将前面的ip地址改为实际的ip地址
怎么知道自己虚拟机的ip地址?
命令:ifconfig -a
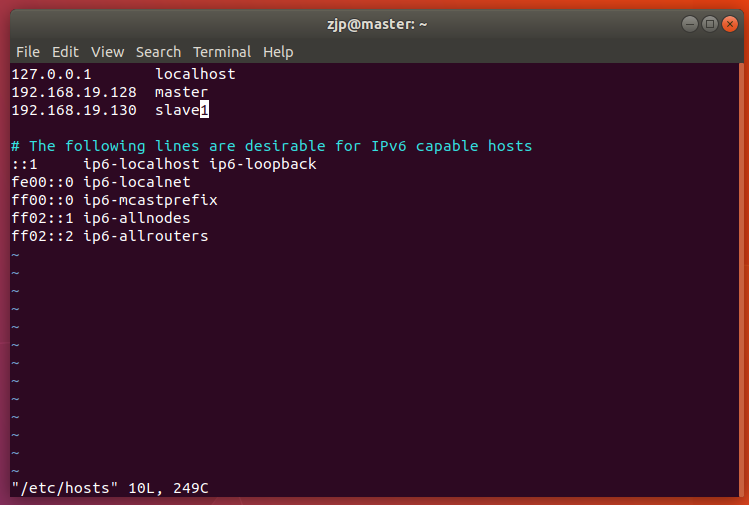
slave1的ip地址就是从虚拟机slave1的真实ip地址。同样,我们在slave1虚拟机上也要进行这一步操作。
二、建立ssh无密码登录本机
1、创建ssh-key,,这里我们采用rsa方式
- ssh-keygen -t rsa -P "" //(P是要大写的,后面跟"")(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2. 进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的
- cd ~/.ssh
- cat id_rsa.pub >> authorized_keys
完成后就可以无密码登录本机了。
3、登录localhost
ssh localhost ( 注:当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。)
4、执行退出命令
- exit
1~4步在master和slave1两台虚拟机上都要配置
5.配置master无密码登陆slave1
mater主机中输入命令复制一份公钥到home中:
cp .ssh/id_rsa.pub ~/id_rsa_master.pub
把master的home目录下的id_rsa_master.pub拷到slave1的home下(我的做法是先拖到windows桌面上,在拖进slave1虚拟机中)
slave1的home目录下分别输入命令
cat id_rsa_master.pub >> .ssh/authorized_keys
至此实现了mater对slave1的无密码登陆
三. 配置 hadoop的配置文件
以下的步骤只在master上进行(除了hadoop的环境变量配置在slave1上也要进行之外)
1.core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/zjp/hadoop-2.7.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
2.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zjp/hadoop-2.7.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zjp/hadoop-2.7.7/tmp/dfs/data</value>
</property>
</configuration>
3.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
4.yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<!-- 会遇到资源不足的问题。出于测试目的,禁用内存检查如下两条配置语句-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
5.配置slaves 文件
sudo vim slaves
把原本的localhost删掉,改为slave1
6.接下来,将hadoop传到slave1虚拟机上面去:
scp -r hadoop-2.7.7 zjp@slave1:~/
注意:hadoop是虚拟机的用户名,创建slave1时设定的
7.初始化hadoop
bin/hdfs namenode -format
8.开启hadoop
两种方法:
- sbin/start-all.sh
- 先start-dfs.sh,再start-yarn.sh
如果在mater上面键入jps后看到
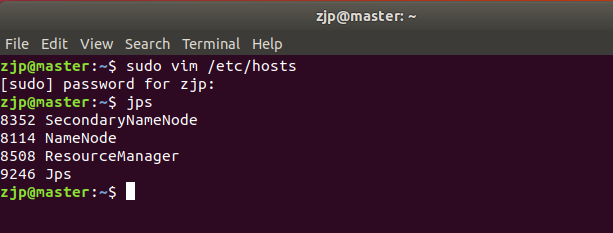
在slave1上键入jps后看到
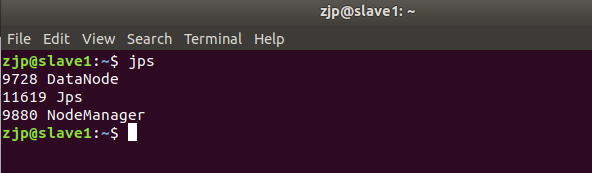
则说明集群搭建成功
四.最后用自带的样例测试hadoop集群能不能正常跑任务
使用命令
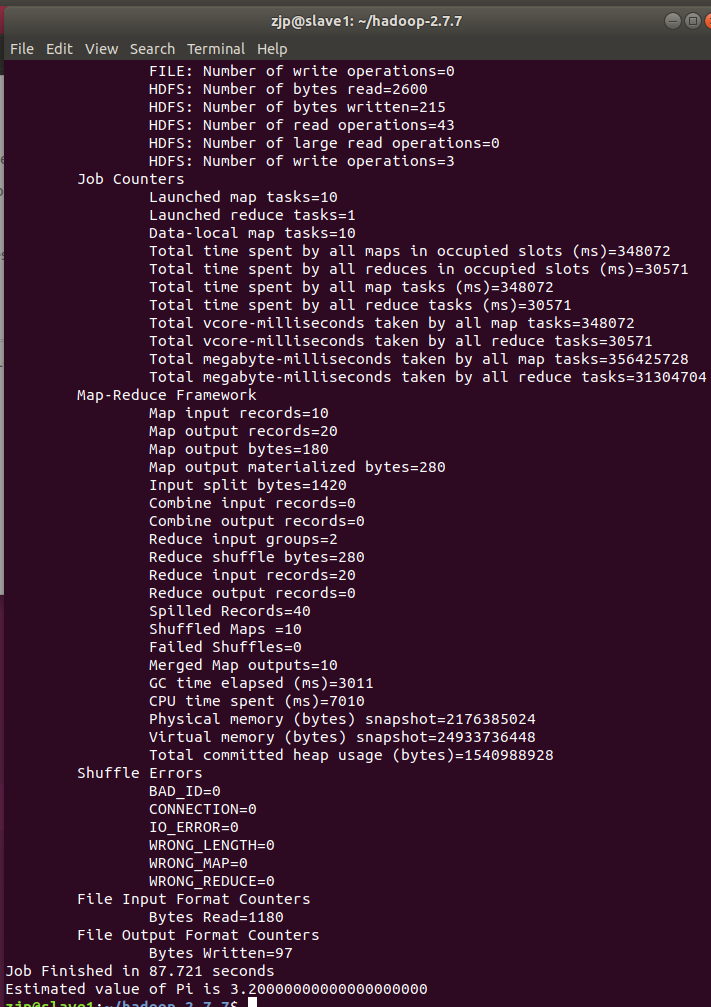
bin/hadoop jar /home/zjp/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10
最后看到结果:
参考:https://blog.csdn.net/fanxin_i/article/details/80425461