selenium元素定位
- selenium定位有八种方式,id、name、class、tag、link_text、partial_link_text、css、xpath
- 八种定位方式各有两个方法
- find_element_by_方式,定位单个元素的。
- find_elements_by_方式,定位多个元素的
一、id定位
HTML页面中id是唯一的,所以当要定位的元素有id时,定位十分方便
find_element_by_id()
例:

#!/usr/bin/python3
# -*- condig:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com/')
chrome.find_element_by_id('kw').send_keys('selenium') #使用id属性定位到百度输入框框,并输入’selenium‘
chrome.find_element_by_id('su').click() #使用id属性到百度一下按钮,点击
time.sleep(30)
二、name定位
HTML页面中元素的名称可以不是唯一的,如果在页面中要定位的元素元素名称唯一则可以使用name定位,如果不唯一,需要配合其它因素定位定位或使用其它定位方法
find_element_by_name()
例:
#!/usr/bin/python3
# -*- condig:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com/')
chrome.find_element_by_name('wd').send_keys('selenium') #使用name属性定位到百度输入框框,并输入’selenium‘
chrome.find_element_by_id('su').click() #‘百度一下’按钮没有name属性
time.sleep(30)
三、class定位
classs定位与name定位相同,在HTML页面可以不唯一
例:
find_element_by_class_name()
#!/usr/bin/python3
# -*- condig:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com/')
chrome.find_element_by_class_name('s_ipt').send_keys('selenium') #定位到百度输入框框,并输入’selenium‘
# chrome.find_element_by_class_name("bg s_btn").click() #无法用class定位到’百度一下‘按钮
chrome.find_element_by_id('su').click()
time.sleep(30)
四、tag定位
根据标签名定位
因为一个html页面中相同的标签名太多了,所以不常用
五、link_text定位
用来定位文本超链接,一般为(href="********************")
例:
find_element_by_link_text()
# -*- condig:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com/')
chrome.find_element_by_link_text('贴吧').click() #定位到’贴吧‘超链接
time.sleep(30)
六、partial link text定位
用文本链接中的一部分定位
例:通过“贴”字 定位到’贴吧‘超链接
#!/usr/bin/python3
# -*- condig:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com/')
chrome.find_element_by_partial_link_text('贴').click() #通过“贴”字 定位到’贴吧‘超链接
time.sleep(30)
七、xpath定位
selenium定位元素众多方法中,像是通过id、name、class_name、tag_name、link_text等等这些方法局限性太大,拿id属性来说,首先一定不会每个元素都有id属性,其次元素的id属性也不一定是固定不变的。所以这些方法了解一下即可,我们真正需要熟练掌握的是通过xpath和css定位,一般只要掌握一种就可以应对大部分定位工作了。
xpath菜鸟教程
python+selenium基础之XPATH定位(第一篇)
python+selenium基础之XPATH轴定位(第二篇)
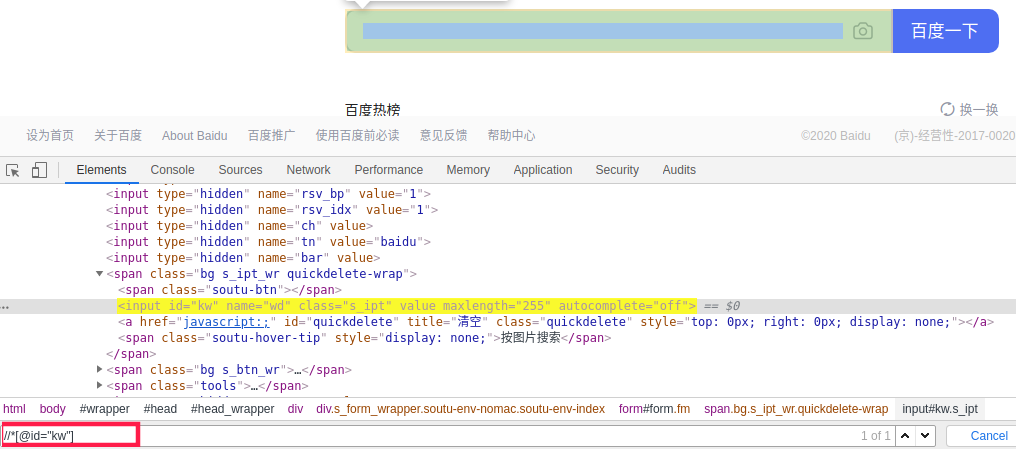
在浏览器可以直接获取到元素的xpath
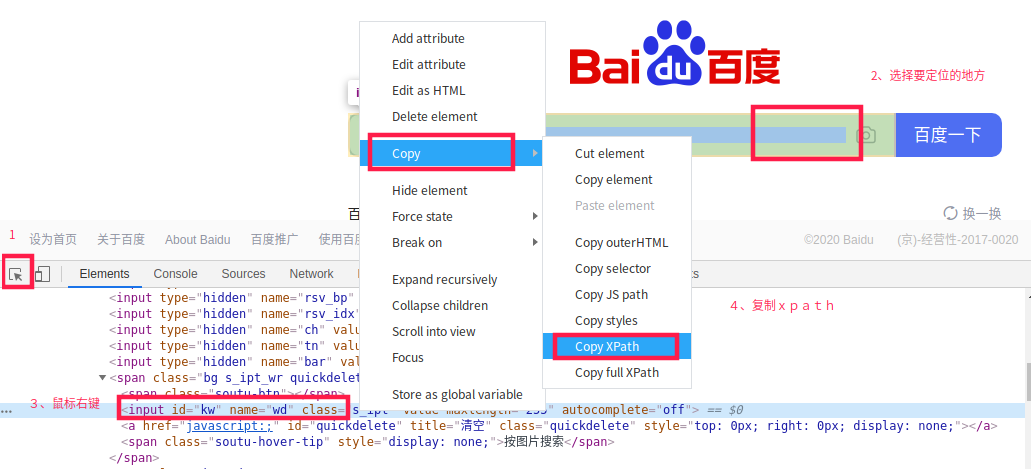
验证自己洗的xpath是否正确
有时从浏览器复制到的xpath是绝对路径会很长,需要自己改写为相对路径后要验证一下自己写的xpath是否能准确定位到目标元素
在目标页面按下"F12"
鼠标在浏览器控制台"CTRL+F"
在左下角的搜索框输入xpath看是否能定位到目标元素
八、css定位
由于xpath基本能解决各种定位需求,所有css未深入学习(后续会补充学习)
参考