参考资料:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html
关联规则:两个不相交的非空集合X、Y,如果有X-->Y,就说X-->Y是一条关联规则。
支持度(support):support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。
自信度(confidence):confidence(X-->Y) = |X交Y|/|X| = 集合X与集合Y中的项在一条记录中同时出现的次数/集合X出现的个数 。
绝对支持度abs_support = 数据记录数N*support
关联规则挖掘:给定一个交易数据集T,找出其中所有支持度support >= min_support、自信度confidence >= min_confidence的关联规则。简单过程为:
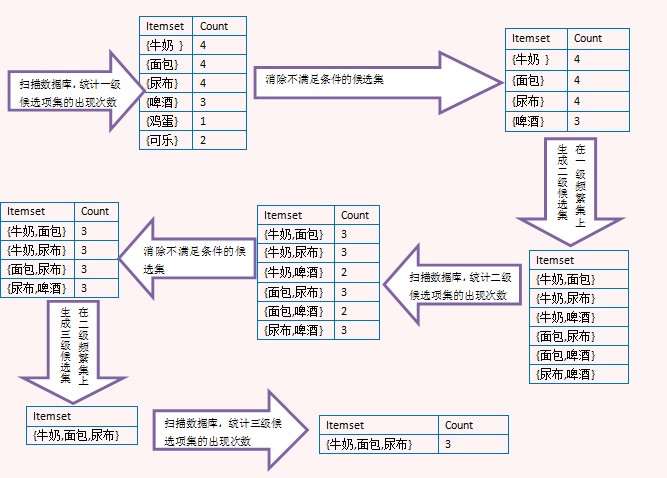
1)生成频繁项集(时间开销较大)
这一阶段找出所有支持度大于最小支持度的项集,找出的这些项集称为频繁项集。
2)生成规则
在上一步产生的频繁项集的基础上生成满足最小自信度的规则,产生的规则称为强规则。
优化算法:Apriori算法
Apriori定律1):如果一个集合是频繁项集,则它的所有子集都是频繁项集。
举例:假设一个集合{A,B}是频繁项集,即A、B同时出现在一条记录的次数大于等于最小支持度min_support,则它的子集{A},{B}出现次数必定大于等于min_support,即它的子集都是频繁项集。
Apriori定律2):如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
举例:假设集合{A}不是频繁项集,即A出现的次数小于min_support,则它的任何超集如{A,B}出现的次数必定小于min_support,因此其超集必定也不是频繁项集。
Apriori算法:Apriori算法属于候选消除算法,是一个生成候选集、消除不满足条件的候选集、并不断循环直到不再产生候选集的过程。