什么是索引?索引就是排好序的数据结构,可以帮助我们快速的查找到数据
推荐一个网站,可以演示各种数据结构:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
---------------------------------------------------------------
图解几种数据结构:
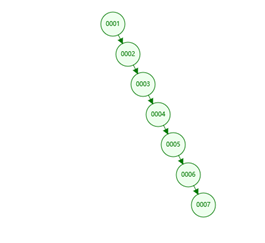
二叉树:如果数据是单边增长的情况 那么出现的就是和链表一样的数据结构了,树高度大
红黑树:在二叉树的基础上多了树平衡,也叫二叉平衡树,不像二叉树那样极端的情况会往一个方向发展。
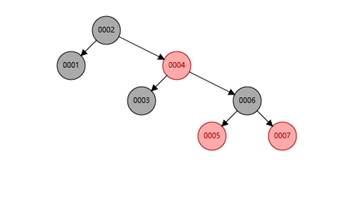
同样我们查找6,在二叉树中我们需要经过6个节点才能找到(1-2-3-4-5-6),红黑树中我们只需要3个节点(2-4-6),但是mysql索引的数据结构并不是红黑树,因为如果数据量大了之后,树的高度就会很大。
B树:在红黑树的基础上,每个节点可以存放多个数据
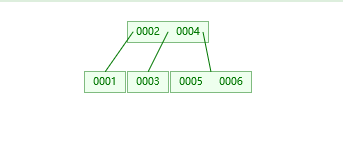
这个时候我们查找6 只需要2个节点就可以了,而且树的高度也比红黑树矮。
B+树:B树的变种
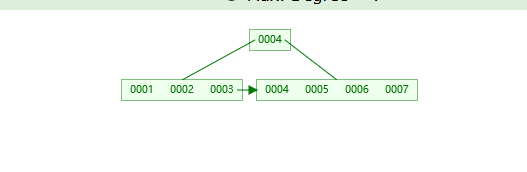
你会发现非叶子节点是会重复的,就像上面4,在叶子节点上面也出现了4,这是为什么呢?因为它需要在叶子上面存放数据。那又是怎么存放数据的呢?
---------------------------------------------------------------
mysql索引为什么用B+树
首先说一点,mysql索引的数据结构就是用到的B+树。
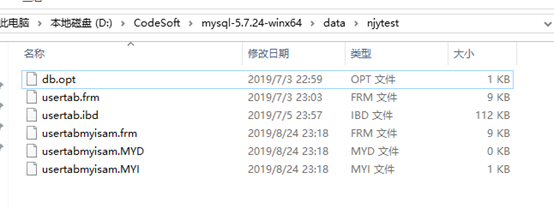
MyISAM存储引擎索引文件和数据文件是分离的
Usertabmyisam表使用的myisam存储引擎,表相关文件有三个,.frm是存放表结构数据,MYD是表数据。MYI是存放索引,索引树上会存储数据在MYD文件里面的位置。
InnoDB存储引擎
Usertab使用的Innodb存储引擎,表相关文件只有两个同样.frm文件是存放表结构数据,.ibd存放的数据和索引。
表数据文件本身就是按B+Tree组织的一个索引结构文件,主键索引叶节点包含了完整的数据记录
以InnoDB为例:
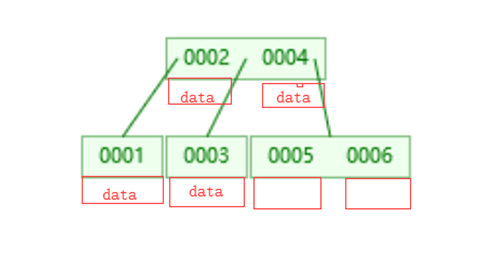
数据是放在主键索引上面,也就是说实际上在每个节点上还会存放所有的数据
使用B树存放数据之后实际是这样子的,会在每个对应的索引列的值上存放上对应的数据
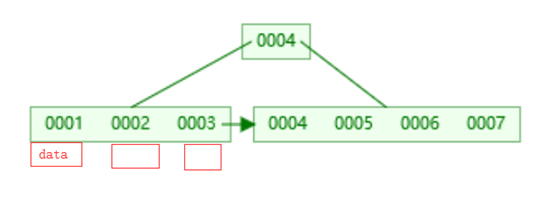
而B+树则不同,它只会在叶子节点上面挂载数据,非叶子节点不会存放数据,数据只会存在叶子节点上面,非叶子节点只存放索引列的数据
这样一个节点就可以存放很多个索引列数据,一次IO就可以拿到很多数据,mysql默认的一个节点16K的大小,可以通过show global status like "Innodb_page_size" 看到该值是16384,每次IO读取16K大小的数据,以索引列是bigInt类型为例,大小8字节,每一条数据还有一个指向下一层的指针6字节,16384/(8+6)=1170,一个节点就大约可以存1170条数据。
以一个层高为3的树为例,叶子节点存放数据之后大小1KB,那么这个树可以存放 1170 *1170 *16 =21,902,400,大约2200万条数据。所以在这种千万级的表中通过主键索引查找一条数据,最多3次IO就可以找到一条数据。而很多时候树的根节点基本都是在内存中,所以多数时候只需要2次IO。
叶子节点之间也有双向指针连接,提高区间范围性能,范围查找。
创建索引的时候,可以选择索引数据类型,一个是btree一个是hash,hash查找当然也快,但是当遇到范围查找的时候hash就尴尬了,所以根据实际业务需求来看是用btree还是hash。
---------------------------------------------------------------
主键索引三问
为什么非主键索引结构叶子节点存储的是主键值?
一是保证一致性,更新数据的时候只需要更新主键索引树,二是节省存储空间。
为什么推荐InnoDB表必须有主键?
保证会有主键索引树的存在(因为数据存放在主键索引树上面),如果没有mysql会自己生成一个rowid作为自增的主键主键索引
为什么推荐使用整型的自增主键?
一是方便查找比较,而是新增数据的时候只需要在最后加入,不会大规模调整树结构,如果是UUID的话,大小不好比较,新增的时候也极有可能在中间插入数据,会导致树结构大规调整,造成插入数据变慢。
---------------------------------------------------------------
联合索引
可以理解成把几个字段拼接起来的一个普通索引
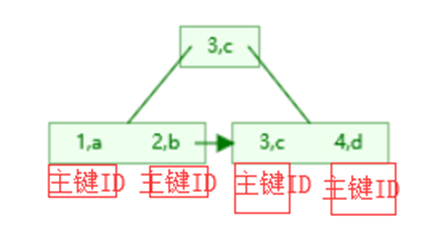
联合索引使用,按照建索引的顺序字段来比较使用,参照左前缀原则。