原论文标题:Acquisition of Localization Confidence for Accurate Object Detection
1. 前言
Megvii在ECCV 2018上的一篇oral,思路非常清奇,提出了Localization Confidence(定位置信度)这一概念,直接学习预测框与gt框的IoU,用于取代nms中的score。同时,提出了一个基于优化的bbox refinement方法。这些创新可以轻易地嵌入到现有的目标检测系统中。个人感觉,目标检测这一研究方向最近新挖了很多坑,仿佛继kaiming的一系列大作之后焕发了第二春。除这篇文章外,再简单推荐三篇其他文章:
- 旷视ECCV 2018的另一篇DetNet,在目标检测的Backbone上下工夫,认为预训练模型应该往目标任务上靠,譬如目标检测要想达到更好的定位精度,深层的空间分辨率不应该像分类一样缩小32倍,当然对空间分辨率的要求只是检测任务的特点之一,那么是不是有其他特点可以挖掘,进而从其他方向继续改进Backbone,这是一个很值得研究的问题。
- MSRA CVPR 2018的oral,Relation Network,基于Attention,根据object的appearance特征和geometry特征对物体关系进行建模,提高检测效果,并且将关系模块运用在duplicate remove中,进行可学习的nms,实现了第一个完全end-to-end的目标检测系统。个人感觉,这篇文章对关系的建模还有改进的空间,学出来的所谓“关系”并不知道是什么东西,更像是把Attention强行套入目标检测系统中。不过可学习的nms是很大的创新。
- MSRA ECCV 2018的oral,Learning Region Features for Object Detection,给出了各种ROI pooling变体的统一数学描述,并且基于这一数学描述,提出了一种可学习的版本,让网络自适应地学习Region Features,选择合适的pooling方式,抛弃了pooling的手工设计,使得object detection朝着fully learnable的方向又迈进一步。论文的二作Han Hu在一次Talk中提到,给出统一的数学描述之后,他们也只是给出了一种可行的可学习方案,肯定不是最好的方案,所以这也是个很大的坑。
这是我对这几篇文章粗浅的认识,有时间的话再来补笔记,关于这些文章的细节,也欢迎留言探讨。闲话不再扯,正式开始分析这篇文章。
2. Motivation
直接上图说明问题。

在传统的nms中,先根据分类的confidence对每个预测bbox进行排序,confidence最大的bbox必然留下来,计算其他bbox和这个bbox的iou,大于阈值的bbox直接去掉。这是一种贪心算法,很粗暴,也会造成很多问题,比如之前很多文章都提到在crowd的环境中贪心会造成很多问题。但是这篇文章对nms的过程进行了深入思考,提出了另一个问题。nms算法其实有一个重要假设,分类confidence越大,与gt bbox的iou也就越大,想想就有问题!如Fig. 1(a),黄框是gt,红框和绿框是FPN的预测bbox。红框的cls conf都比绿框高,然而与gt的iou并不比绿框高,问题非常严重,譬如最左边那只鸟,如果在评价算法中把iou阈值设成0.7,那就算这只鸟没有检到!简直血亏!所以,nms的confidence应该专门设计一个指标,也就是loc conf。只要有了这个东西,重新设计nms就是很容易的事情了,而且这个东西肯定还可以搞很多别的事情。
缺失定位confidence的另一个问题是bbox回归的可解释性较差。作者举了个例子,在Cascade RCNN(CVPR 2018 spotlight,直接搜索标题就能查到)中提出了bbox迭代回归的非单调问题,如图Fig 1(b),如果多次使用(同一个)bbox回归器,定位精度反而会下降。(文章中此处所说的input bbox是指RPN或selective search得到的前景bbox)
3. 深入思考object loc
这一节对物体定位中的两个关键缺陷作探讨:(1)cls conf与loc acc的misalignment问题。(我就不加说明地直接用缩写了,应该都能看懂,如果有疑问可以直接向我提)(2)bbox回归的不单调问题。实验用标准的FPN在COCO trainval35k上训练作为baseline,在minival上测试。

解释一下图(a),横坐标是nms之前的预测bbox与各自匹配上的gt bbox的iou,纵坐标是预测bbox的cls conf,可以看到它们的相关性不够大,定量来看,两者的Pearson相关系数仅为0.217。其实这个问题我在第二节分析过了,如此弱的相关系数直接证明了nms的基本假设是有问题的,至少在COCO上有问题。图(b)纵坐标换成了loc conf,是作者提出的改进,具体做法下面再说,可以看到改进后相关系数达到了0.617。
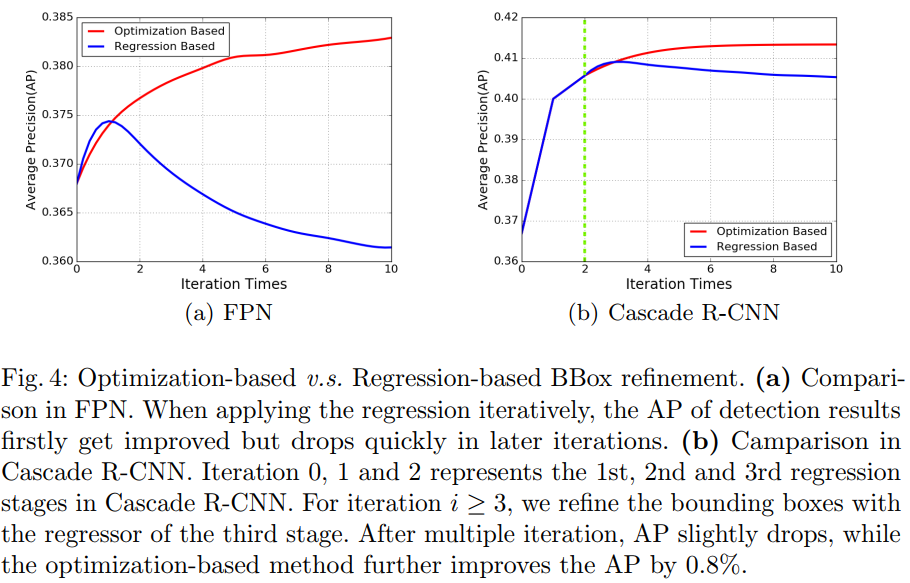
再看这张图,Cascade R-CNN就是用了多个回归器进行迭代bbox回归,可以看出,基于迭代回归的方法,在一定的迭代次数之后AP都会被伤害,而使用作者提出的基于优化的方法,AP不会下降,至少是随着迭代次数单调不减的。
3. IoU-Net
重点开始,先摆上算法结构图。
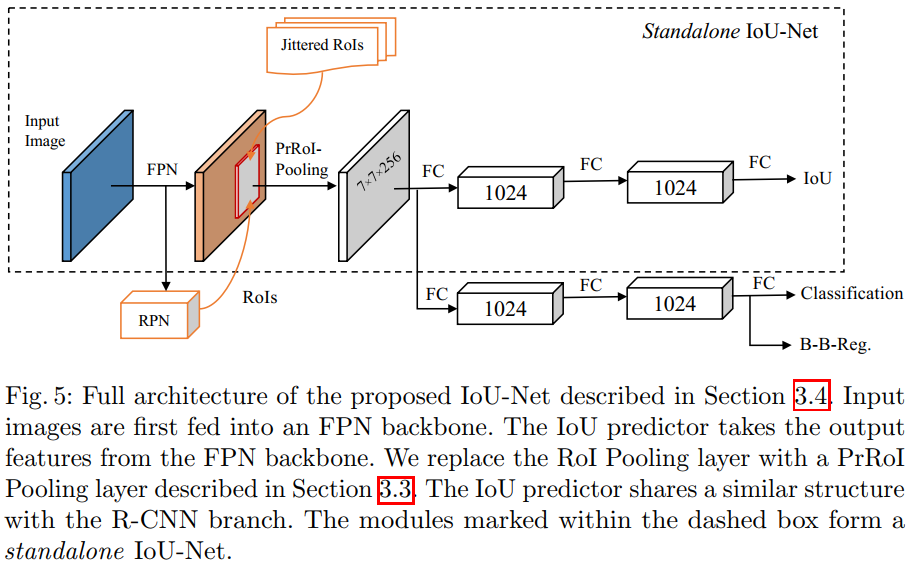
结构很清楚,跟FPN不同的地方有两个,一是RoI pooling改成了PrRoI pooling,这应该是旷厂内部的一个工作;而是除了cls和reg头,加上了IoU头,结构也是三层全连接。文章专门设计了IoU头的训练方法,这个我就不写了。图中的Jittered RoIs就是为这个训练准备的。IoU头完全可以和其他部分联合端到端训练。
得到预测的IoU之后,就可以做IoU-guided的nms,具体方法前面已经说了好几遍了,只是把排序的key换成了预测的IoU而已。另外加了一个小trick,一旦在nms过程中box i“吞并”了box j,那么box i的cls conf取i和j之大者。也就是说如果有一堆框去预测同一个gt box,那么cls conf取其中最大的一个。(这个说法是我自己加的,不够严谨,不过这样理解基本没问题)
另一个重要创新是基于优化的bbox refinement,
(未完待续)