1. log4j(具体见log4j文档)
log4j是一个java系统中用于输出日志信息的工具。log4j可以将日志定义成多种级别:ERROR / WARN / INFO / DEBUG
log4j通过获取到一个logger对象来输出日志:
val logger = Logger.getLogger("logger名称"); logger.info("日志内容")
所拿到的这些logger对象之间是有“父子”关系的,所有logger都是rootLogger的子!
"org.apache" 这个名字的logger是 "org"这个名字的logger的子!
log4j的日志输出格式和目的地,都是可以通过参数配置的;
-
目的地的控制用Appender输出组件
常用的Appender组件:
log4j.appender.xx=org.apache.log4j.ConsoleAppender
log4j.appender.rollingFile=org.apache.log4j.RollingFileAppender
-
格式的控制用LayOut布局组件
log4j.appender.xx.layout=org.apache.log4j.PatternLayout
log4j.appender.xx.layout.ConversionPattern=[%-5p] %d(%r) --> [%t] %l: %m %x %n
2. 父子maven工程
(1)创建一个父工程(如平常创建一样),父工程中不写代码,所以最好将src文件夹删除(比如公司新手会将代码误写入该文件夹)
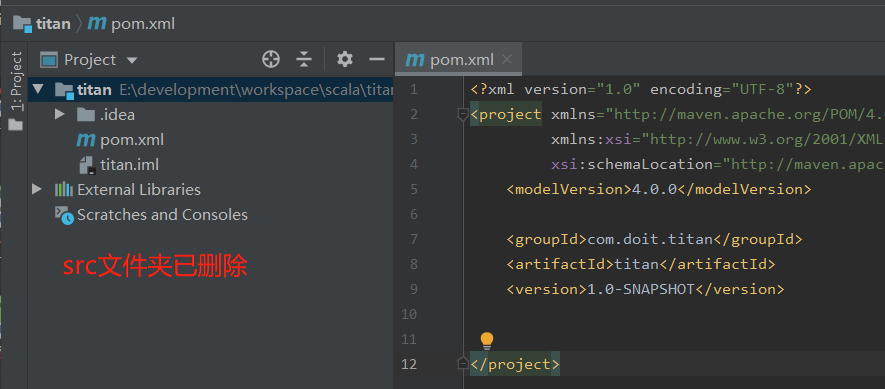
(2)创建子工程
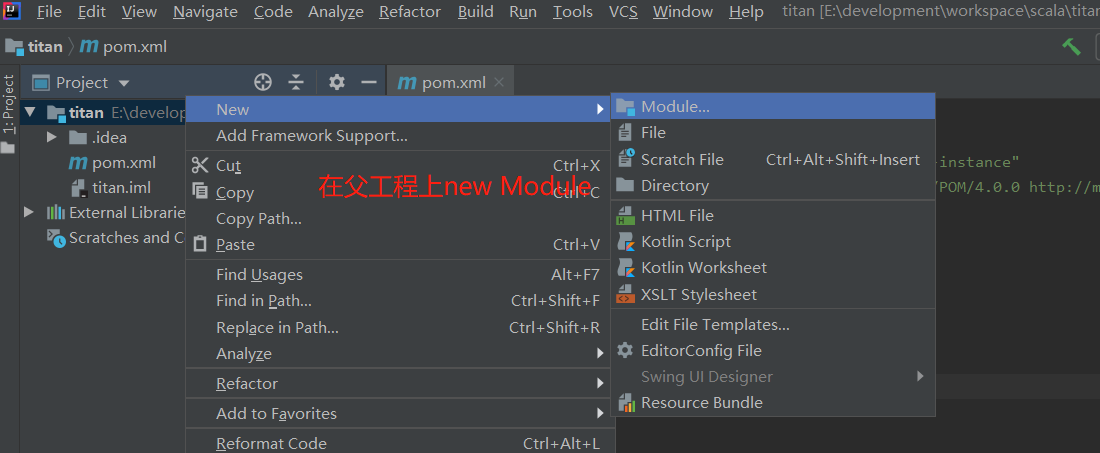
得到如下图
接着如下所示

到此,一个子maven项目dataware即建立成功,子项目的pom文件如下所示
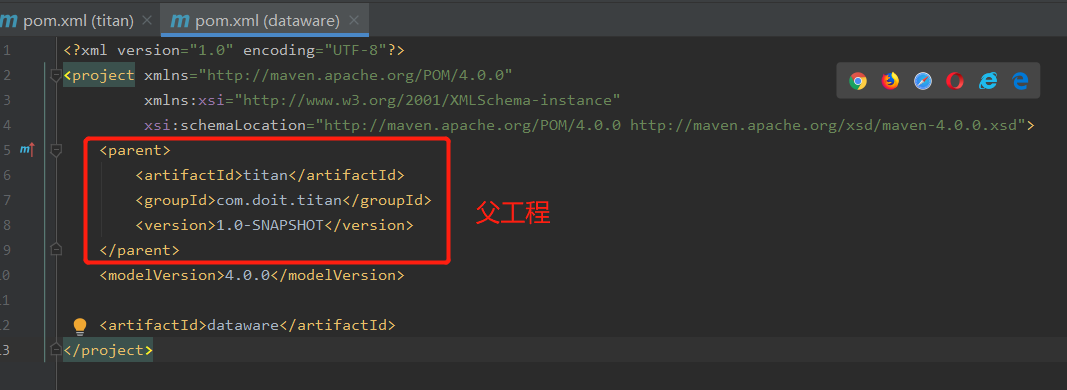
若是子工程中的父工程配置删除后,子工程不认识父工程,但是父工程认识子工程
(3)说明
A. 父工程pom文件中引入公共的依赖和插件(会被子工程pom继承),此处有几处规范
- 依赖定义的管理(不是真正引入依赖) 标签:<dependencyManagement><dependencyManagement>
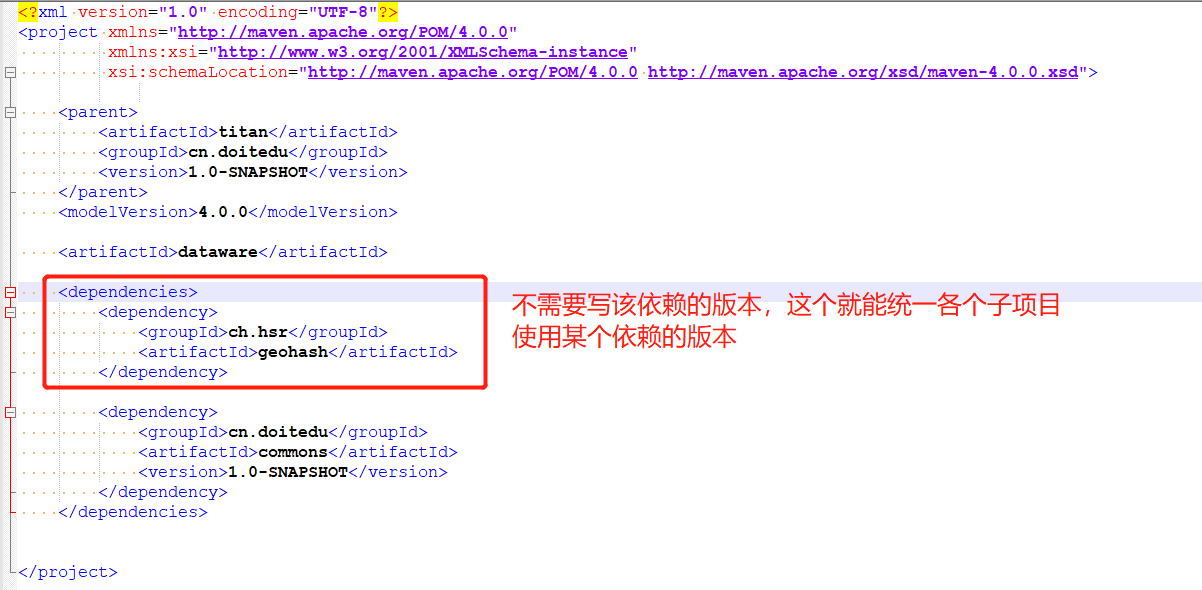
作用:父项目中某个子项目需要用到某个依赖,这个时候若是在子项目的pom文件中定义这个依赖的版本,当另外一个子项目也要这个依赖时,由于需要统一依赖的版本,这时另外一个子项目中也需要定义相同版本的依赖。这样就比较麻烦,这个时候就可以使用依赖定义的管理(在父工程中定义子项目需要依赖的版本,子项目中就不需要写依赖的版本),如下
父工程pom文件(部分)
<dependencyManagement>
<dependency>
<groupId>ch.hsr</groupId>
<artifactId>geohash</artifactId>
<version>1.3.0</version>
</dependency>
</dependencies>
</dependencyManagement>
子工程pom文件
- 属性定义(标签:<properties><properties>)

- 依赖排除(标签:<exclusions><exclusions>): 解决jar包的版本冲突
比如下面的spark使用的hadoop版本就出现依赖的冲突
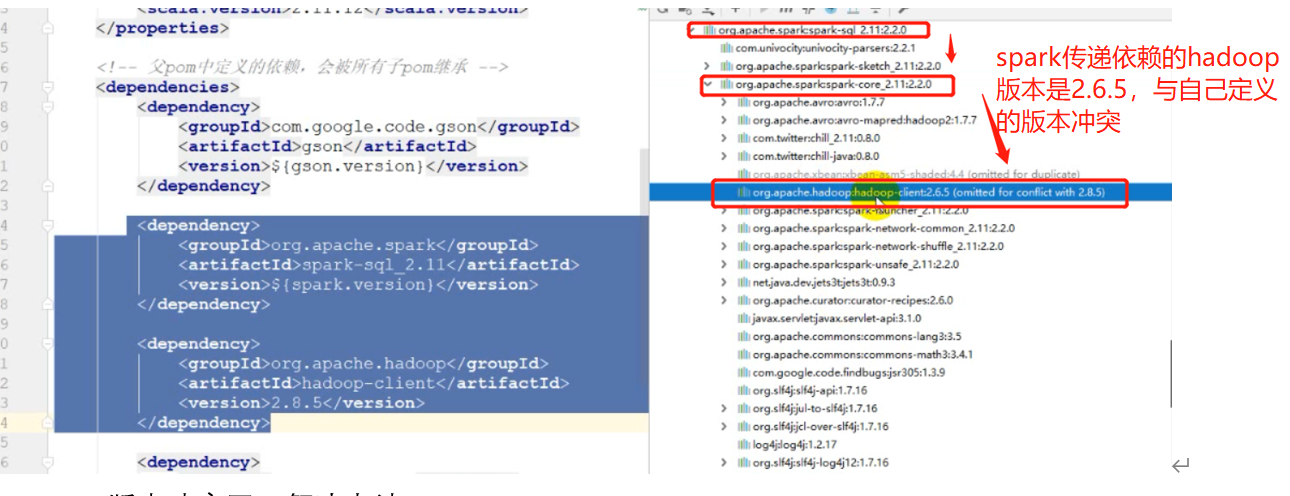
解决办法(排除依赖)
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> <exclusions> <exclusion> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> </exclusion> </exclusions> </dependency>
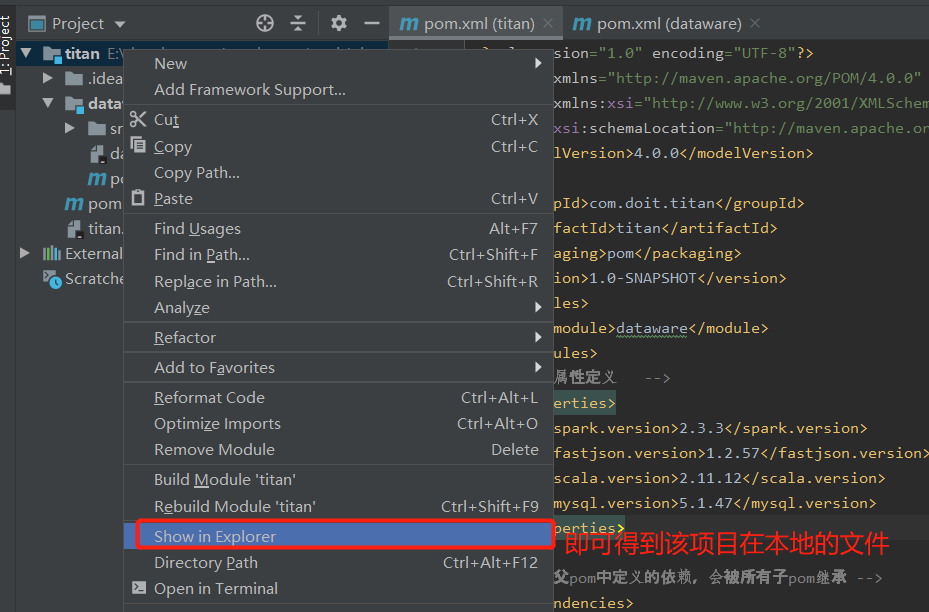
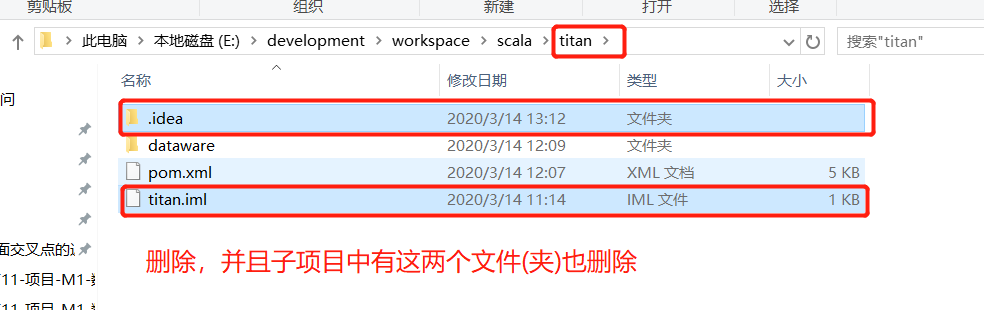
- 当在idea删除某个项目时,再创建一个同名的项目时,会出错(Idea中记录的东西会冲突)
解决办法:
直接到项目的目录中将idea的相关文件删除掉,如下图所示
spring子项目的创建
3.项目开发(埋点日志预处理-json数据解析、清洗过滤、数据集成实现、uid回补)
3.1 json数据格式如下:
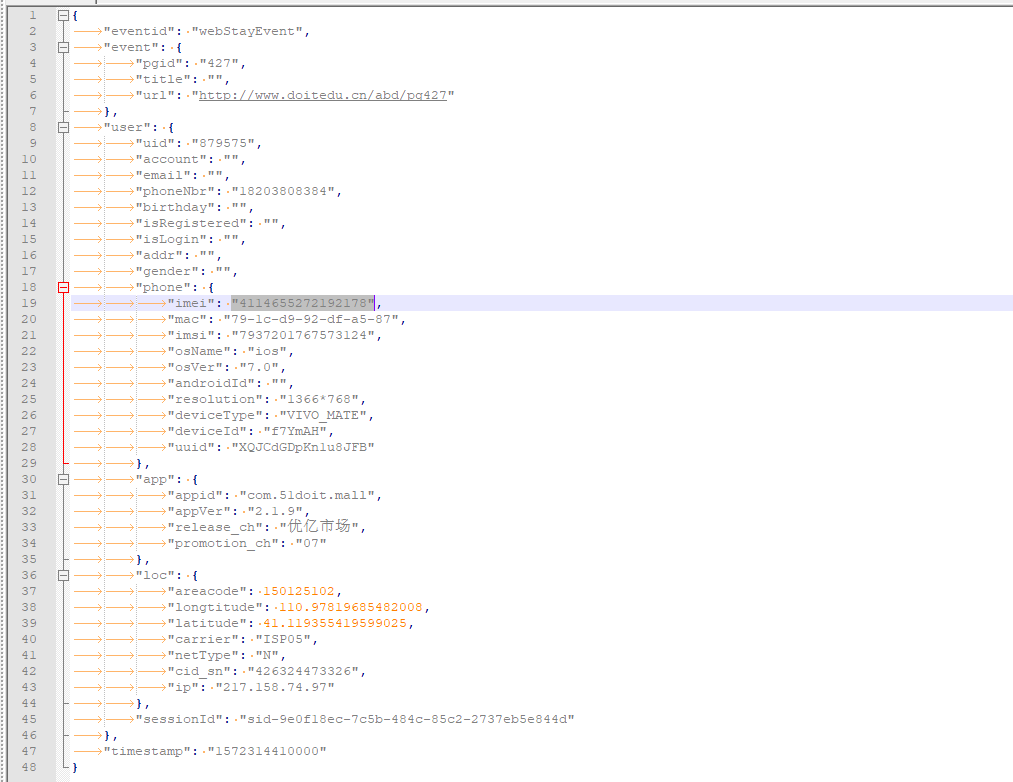
3.2 需求说明
3.2.1 清洗过滤

此处为了记录数据方便,定义一个AppLogBean,该类中定义了两个方法(1.解析json 返回一个case class, 2. 判断一个bean是否有效),并在该类中定义一个case class AppLogBean
AppLogBean代码


package com._51doit.tian.dw.pre import com.alibaba.fastjson.{JSON, JSONObject} import org.apache.commons.lang3.StringUtils import scala.collection.mutable case class AppLogBean( eventid :String , timestamp :Double , event :Map[String,String] , uid :String , phoneNbr :String , sessionId :String , imei :String , mac :String , imsi :String , osName :String , osVer :String , androidId :String , resolution :String , deviceType :String , deviceId :String , uuid :String , appid :String , appVer :String , release_ch :String , promotion_ch :String , longtitude :Double , latitude :Double , carrier :String , netType :String , cid_sn :String , ip :String, var province:String = "", var city:String = "", var district:String = "", var dateStr:String = "", var timeStr:String = "" ) object AppLogBean { /** * 解析app埋点json日志,返回一个case class */ def parseJson2Bean(line:String): AppLogBean ={ try { val obj: JSONObject = JSON.parseObject(line) val eventid: String = obj.getString("eventid") val timestamp = obj.getString("timestamp").toDouble val event: JSONObject = obj.getJSONObject("event") val eventMap: mutable.HashMap[String, String] = new mutable.HashMap[String, String]() import scala.collection.JavaConversions._ for(ent <- event.entrySet()){ eventMap.put(ent.getKey,ent.getValue.toString) } val user = obj.getJSONObject("user") val uid = user.getString("uid") val phoneNbr = user.getString("phoneNbr") val sessionId = user.getString("sessionId") val phone = user.getJSONObject("phone") val imei = phone.getString("imei") val mac = phone.getString("mac") val imsi = phone.getString("imsi") val osName = phone.getString("osName") val osVer = phone.getString("osVer") val androidId = phone.getString("androidId") val resolution = phone.getString("resolution") val deviceType = phone.getString("deviceType") val deviceId = phone.getString("deviceId") val uuid = phone.getString("uuid") val app = user.getJSONObject("app") val appid = app.getString("appid") val appVer = app.getString("appVer") val release_ch = app.getString("release_ch") val promotion_ch = app.getString("promotion_ch") val loc = user.getJSONObject("loc") val longtitude = loc.getDouble("longtitude") val latitude = loc.getDouble("latitude") val carrier = loc.getString("carrier") val netType = loc.getString("netType") val cid_sn = loc.getString("cid_sn") val ip = loc.getString("ip") AppLogBean( eventid , timestamp, eventMap.toMap, uid , phoneNbr , sessionId , imei , mac , imsi , osName , osVer , androidId , resolution , deviceType , deviceId , uuid , appid , appVer , release_ch , promotion_ch , longtitude , latitude , carrier , netType , cid_sn , ip ) } catch { case e: Exception => null case _: Throwable => null } } /** * 判断一条bean是否有效 */ def isValidBean(bean:AppLogBean): Boolean ={ val uid: String = bean.uid val imei: String = bean.imei val uuid: String = bean.uuid val mac: String = bean.mac val androidId: String = bean.androidId val ip: String = bean.ip // 以上参数不能全为空 var flag1 = StringUtils.isNotBlank((uid + imei + uuid + mac + androidId + ip).replaceAll("null", "")) val event: Map[String, String] = bean.event val eventid: String = bean.eventid val sessionId = bean.sessionId var flag2 = (event != null) && (StringUtils.isNotBlank(eventid) ) && (StringUtils.isNotBlank(sessionId)) flag1 && flag2 } }
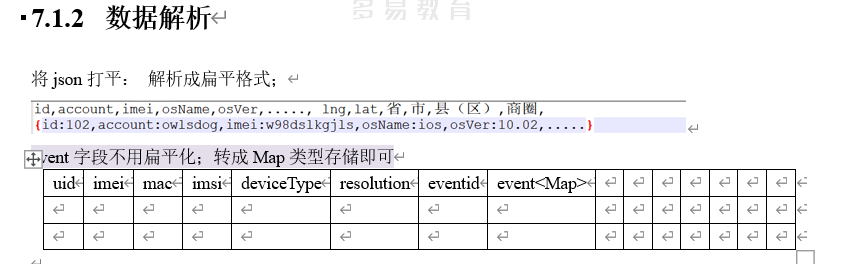
3.2.2 数据解析
此处event数据不用扁平化的原因是,event内的数据类型也不一样
3.2.3 数据集成

3.2.4 数据修正

思路图

注意:此处手机标识 比如imei为空时,作为join on相等的条件时会出错,一定要判断非空,由于sql语句很麻烦(如下),所以开发一个自定义函数,用来判断两个字符串在非空情况下是否相等

每一个手机识别方式都要这样写,很麻烦,以下是自定义的函数
// 开发一个自定义函数,用来判断两个字符串在非空情况下是否相等 val is_equal = (x: String, y: String) => { if (x != y || StringUtils.isBlank(x) || StringUtils.isBlank(y)) false else true } spark.udf.register("is_equal",is_equal)
业务代码
AppEventLogPreprocess
package com._51doit.tian.dw.pre import java.text.SimpleDateFormat import ch.hsr.geohash.GeoHash import com._51doit.tian.commons.utils.{DictLoadUtil, SparkUtils} import org.apache.commons.lang3.StringUtils import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object AppEventLogPreprocess { def main(args: Array[String]): Unit = { Logger.getLogger("org").setLevel(Level.WARN) val spark: SparkSession = SparkUtils.getSpark(this.getClass.getSimpleName) import spark.implicits._ // 加载原始日志文件 val ds: Dataset[String] = spark.read.textFile("E:\javafile\dataware\2019-10-29") // 解析json val beans: Dataset[AppLogBean] = ds.map(AppLogBean.parseJson2Bean) /** * 清洗过滤 */ val validBeans: Dataset[AppLogBean] = beans .filter(_ != null) .filter(AppLogBean.isValidBean(_)) /** * 数据集成 */ val dictDF: DataFrame = spark.read.parquet("E:/javafile/spark/out11") val dictMap: collection.Map[String, (String, String, String)] = DictLoadUtil.loadAreaDict(dictDF) val bc_dict = spark.sparkContext.broadcast(dictMap) // 然后进行集成 val integrated: Dataset[AppLogBean] = validBeans.mapPartitions(iter => { // 取广播变量 val dict: collection.Map[String, (String, String, String)] = bc_dict.value iter.map(bean => { // 处理GPS坐标 val longtitude: Double = bean.longtitude val latitude: Double = bean.latitude // 如果经纬度坐标在中国的经纬度范围之内,才去转geohash编码并从字典中查找省市区 if (longtitude > 0 && longtitude < 120 && latitude > 0 && latitude < 70) { val geo = GeoHash.withCharacterPrecision(latitude, longtitude, 5).toBase32 val area = dict.getOrElse(geo, ("", "", "")) bean.province = area._1 bean.city = area._2 bean.district = area._3 } // 处理时间戳 val sdf: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") val str: Array[String] = sdf.format(bean.timestamp).split(" ") bean.dateStr = str(0) bean.timeStr = str(1) // 返回集成完成的bean bean }) }) // integrated.where("trim(province) != '' ").show(10,false) /** * 数据修正 */ val haveUid = integrated.where("uid is not null and trim(uid) !='' ") val noUid = integrated.where(" uid is null or trim(uid) ='' ") import org.apache.spark.sql.functions._ val uids = haveUid .groupBy($"uid") .agg( max("imei").as("imei"), max("imsi").as("imsi"), max("mac").as("mac"), max("uuid").as("uuid"), max("androidId").as("androidId"), max("deviceId").as("deviceId") ) noUid.createTempView("nouid") uids.createTempView("uids") // 开发一个自定义函数,用来判断两个字符串在非空情况下是否相等 val is_equal = (x: String, y: String) => { if (x != y || StringUtils.isBlank(x) || StringUtils.isBlank(y)) false else true } spark.udf.register("is_equal",is_equal) // 对没有uid的数据进行回补操作 val part1: DataFrame = spark.sql( """ | |select | |a.eventid , |a.timestamp , |a.event , |if(b.uid is not null,b.uid,a.uid) as uid, |a.phoneNbr , |a.sessionId , |a.imei , |a.mac , |a.imsi , |a.osName , |a.osVer , |a.androidId , |a.resolution , |a.deviceType , |a.deviceId , |a.uuid , |a.appid , |a.appVer , |a.release_ch , |a.promotion_ch , |a.longtitude , |a.latitude , |a.carrier , |a.netType , |a.cid_sn , |a.ip , |a.province, |a.city, |a.district, |a.dateStr, |a.timeStr | |from | |nouid a left join uids b | on is_equal(a.imei,b.imei) | or is_equal(a.imsi,b.imsi) | or is_equal(a.mac,b.mac) | or is_equal(a.uuid,b.uuid) | or is_equal(a.androidId,b.androidId) | or is_equal(a.deviceId,b.deviceId) | """.stripMargin) // 将回补好的数据 union 原来就有uid的数据 val result = haveUid.toDF.union(part1) // 输出结果 result.write.parquet("E:\javafile\dataware1\2019-10-29") spark.close() } }