zookeeper简介
一、什么是zookeeper
Apache ZooKeeper致力于开发和维护可实现高度可靠的分布式协调的开源服务器。
ZooKeeper是一种集中式服务,用于维护配置信息,命名,提供分布式同步和提供组服务。所有这些类型的服务都以分布式应用程序的某种形式使用。每次实施它们都需要做很多工作来修复不可避免的错误和竞争条件。由于难以实现这些类型的服务,应用程序最初通常会跳过它们,这使得它们在变化的情况下变得脆弱并且难以管理。即使正确完成,这些服务的不同实现也会在部署应用程序时导致管理复杂性。
zookeeper官网:https://zookeeper.apache.org/
二、zookeeper的应用场景
zookeepe作为一个经典的分布式数据一致性解决方案,致力于为分布式提供一个高性能,高可用,且具有严格顺序访问控制能力的分布式协调存储服务。
- 维护配置信息
- 分布式锁服务
- 集群管理
- 生成分布式唯一id
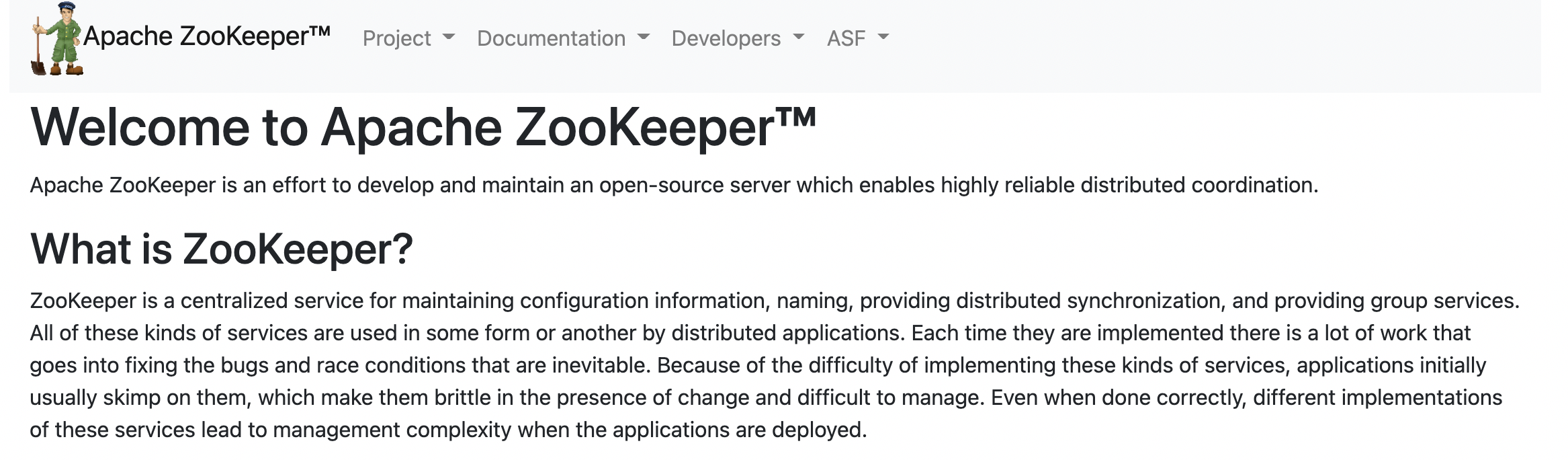
1、维护配置信息
java编程经常遇到配置项,比如数据库的url、 passoword、user、 schema等。通常我们把这些配置项放到文件中,将配置文件放到服务器上。当配置需要更改时,就必须去服务器上修改对应的配置文件。但是随着分布式系统的兴起,许多服务都需要用的该配置文件。因此有必须保证该配置服务的高可用性和各台服务器上配置数据的一致性,通常会将配置文件部署再一个集群上,如果集群存在上百甚至更多台服务器。如果涉及到配置文件的修改那么就需要一台台修改配置文件,这是一个非常繁琐且危险的操作。因此就需要一种服务,能勾快速高效且可靠的完成配置项的更改等操作,并且保证各配置项在每台服务器上的数据一致性。
zookeeper就是这样一种服务,使用zab协议保证数据的一致性。现在许多开软项目使用zookeeper来维护配置,比如hbase,客户端连接就是一个zookeeper,获取必要的hbase配置信息,然后才可以进一步操作。在开源的消息队列kafka中,使用zookeeper来维护broker信息。
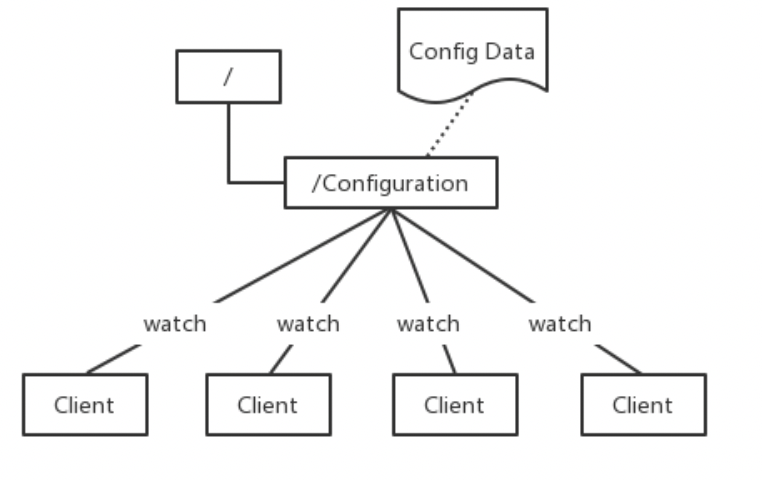
2、分布式锁服务
一个集群是一个分布式系统,由多台服务器组成。为了提高并发度和可靠性,多台服务器运行同一种服务。当多个服务在运行时就需要协调个服务的进度,有时候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作进行加锁。如果当前机器挂掉,释放锁并fail over到其他机器继续执行该服务。
3、集群管理
一个集群有时会因为各种软硬件故障或者网络故障,出现某些服务器挂掉而被移出集群。而某些服务器加入到集群的情况,zookeeper会将这些服务器加入/移出的情况通知给集群中其他正常工作的服务器,以及时调整存储和计算等任务的分配和执行等。此外zookeeper还会对故障服务器做出诊断并尝试恢复。

4、生成分布式唯一id
在单库单表型系统中,通常可以使用数据库字段的auto_increment属性来自动为每条记录生成一个唯一的id。但是分库分表后,就无法依靠数据库的auto_increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一id。做法如下:每次要生成一个新的id时,创建一个持久顺序节点,创建操作返回的节点序号,即为新id。然后把比自己节点小的删除即可。
三、zookeeper的设计目标
致力于为分布式提供一个高性能,高可用,且具有严格顺序访问控制能力的分布式协调存储服务。
1、高性能
zookeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求。尤其适用于以读为主的应用场景。
2、高可用
zookeeper一般以集群的方式对外提供服务,一般3~5台机器就可以组成一个可用的zookeeper集群了。每台服务器都会在内存中维护当前的服务器状态,并且每台机器之间都相互保持着通信。只要集群中超过一半的机器都能够正常工作,那么整个集群就可以对外正常服务。
3、严格的顺序访问
对于来自客户端的每个更新请求,zookeeper都会分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序。
四、zookeeper的数据模型
zookkeeper提供的名称空间非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。每个节点被称为znode,一个znode可以有多个子节点。
znode兼具文件和目录两种特点,既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。
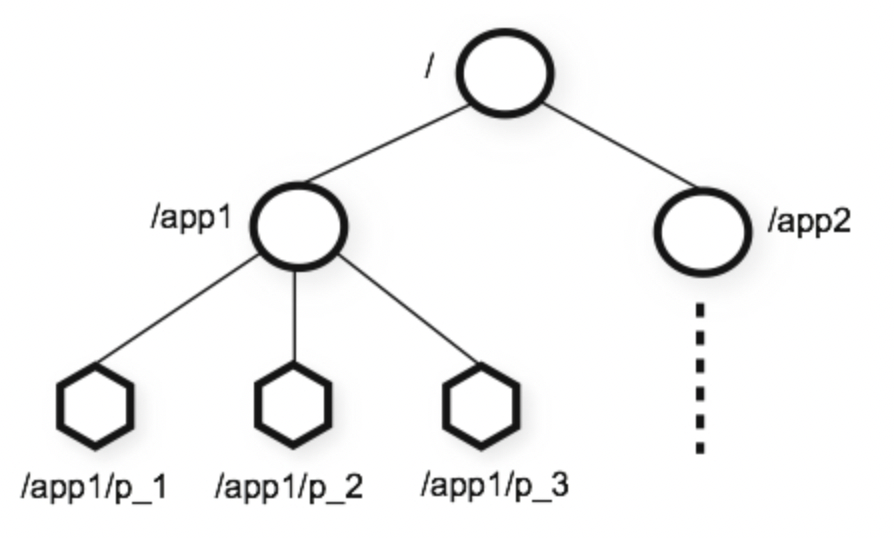
那么如何描述一个znode呢? 一个znode大体分为3个部分:
1、节点的数据:即znode data(节点path 节点data)的关系就像key value的关系
2、节点的子节点children
3、节点的状态stat: 用来描述当前节点的创建、修改记录等信息。
节点的stat属性
在zookeeper shell中通过get命令查看指定路径节点的data、stat信息:(新的zookeeper通过get获取data,stat获取节点信息)
[zk: localhost:2181(CONNECTED) 3] stat /wfj cZxid = 0xa ctime = Tue Apr 20 13:20:06 UTC 2021 mZxid = 0xa mtime = Tue Apr 20 13:20:06 UTC 2021 pZxid = 0xa cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 9 numChildren = 0
属性说明:
- cZxid:数据节点创建时的事务ID
- ctime: 数据节点创建时的时间
- mZxid: 数据节点最后一次更新时的事务ID
- mtime: 数据节点最后一次更新时的时间
- pZxid: 数据节点的子节点最后一次被修改时的事务ID
- cversion: 子节点的更改次数
- dataVersion: 节点数据的更改次数
- aclVersion: 节点的ACL更改次数
- ephemeralOwner: 如果节点时临时节点,则表示创建该节点的SessionID;如果是持久节点,则该属性为0
- dataLength: 数据内容的长度
- numChildren: 数据节点当前的子节点个数
节点类型
zookeeper的节点类型有六种,节点的类型在创建时即被锁定,不能修改。
- 持久化目录节点(PERSISTENT), 创建好之后就永久存在
- 持久化顺序编号节点(PERSISTENT_SEQUENTIAL),创建好节点后还可以默认带个自增的编号
- 临时目录节点(EPHEMERAL),和sessionId绑定的,当客户端被关闭之后,对于的临时目录节点会被删除
- 历史顺序编号目录节点(EPHEMERAL_SEQUENTIAL),临时节点带个自增的编号
- 容器节点(Container),3.5.3新增的特性,没有子节点的容器节点会被清除掉。
- TTL节点,3.5.3新增的特性,位节点设定了失效时间。具体失效时间却决于后台检测失效线程的轮询频率。
五、知识拓展
相关 CAP 理论
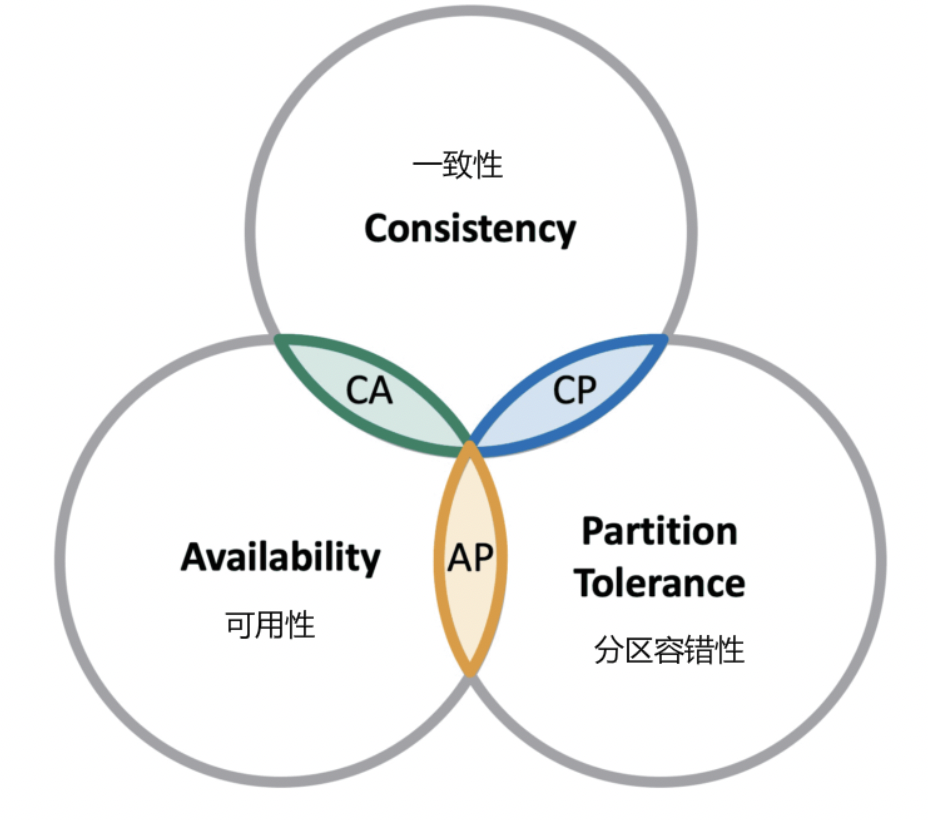
CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
-
可用性:每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
-
分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择,zookeeper 保证的是 CP,对比 spring cloud 系统中的注册中心 eruka 实现的是 AP。
BASE 理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态) 和 Eventually Consistent(最终一致性) 三个短语的缩写。
-
基本可用:在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)。
-
软状态:允许分布式系统出现中间状态。而且中间状态不影响系统的可用性。这里的中间状态是指不同的 data replication(数据备份节点)之间的数据更新可以出现延时的最终一致性。
- 最终一致性:data replications 经过一段时间达到一致性。
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性