iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
数据的获取:
file=importdata('iris.csv');%读取csv文件中从第R-1行,第C-1列的数据开始的数据 data=file.data; features=data(:,1:4);%特征列表 classlabel=data(:,5);%对应类别 n = randperm(size(features,1));%随机产生训练集和测试集
绘制散点图查看数据:
%% 绘制散点图 class_0 = find(data(:,5)==0); class_1 = find(data(:,5)==1); class_2 = find(data(:,5)==2);%返回类别为2的位置索引 subplot(3,2,1) hold on scatter(features(class_0,1),features(class_0,2),'x','b') scatter(features(class_1,1),features(class_1,2),'+','g') scatter(features(class_2,1),features(class_2,2),'o','r') subplot(3,2,2) hold on scatter(features(class_0,1),features(class_0,3),'x','b') scatter(features(class_1,1),features(class_1,3),'+','g') scatter(features(class_2,1),features(class_2,3),'o','r') subplot(3,2,3) hold on scatter(features(class_0,1),features(class_0,4),'x','b') scatter(features(class_1,1),features(class_1,4),'+','g') scatter(features(class_2,1),features(class_2,4),'o','r') subplot(3,2,4) hold on scatter(features(class_0,2),features(class_0,3),'x','b') scatter(features(class_1,2),features(class_1,3),'+','g') scatter(features(class_2,2),features(class_2,3),'o','r') subplot(3,2,5) hold on scatter(features(class_0,2),features(class_0,4),'x','b') scatter(features(class_1,2),features(class_1,4),'+','g') scatter(features(class_2,2),features(class_2,4),'o','r') subplot(3,2,6) hold on scatter(features(class_0,3),features(class_0,4),'x','b') scatter(features(class_1,3),features(class_1,4),'+','g') scatter(features(class_2,3),features(class_2,4),'o','r')
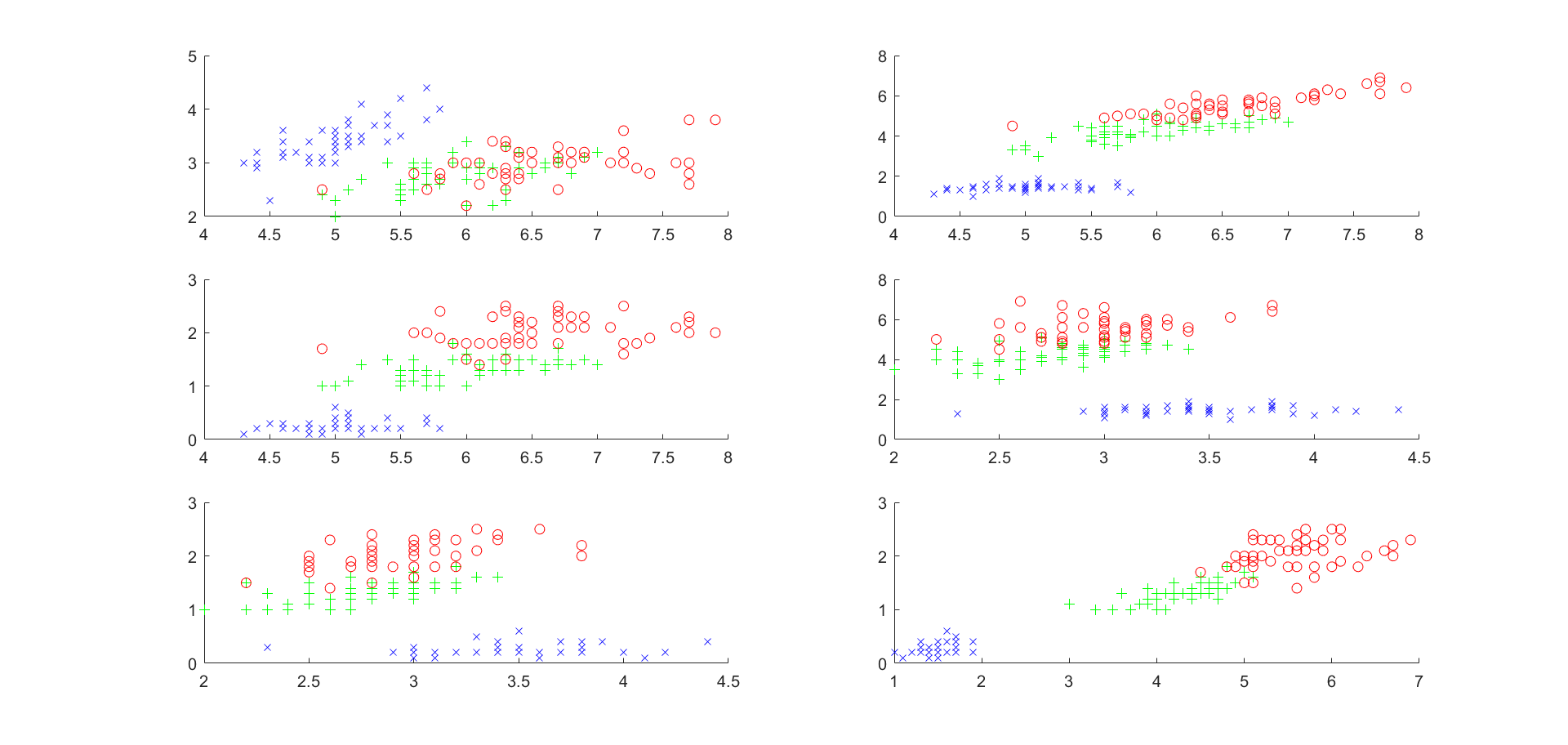
曲线为根据花萼长度、花萼宽度、花瓣长度、花瓣宽度之间的关系绘制的散点图。
训练集与测试集:
%% 训练集--70个样本 train_features=features(n(1:70),:); train_label=classlabel(n(1:70),:); %% 测试集--30个样本 test_features=features(n(71:end),:); test_label=classlabel(n(71:end),:);
数据归一化:
%% 数据归一化 [Train_features,PS] = mapminmax(train_features'); Train_features = Train_features'; Test_features = mapminmax('apply',test_features',PS); Test_features = Test_features';
使用SVM进行分类:
%% 创建/训练SVM模型 model = svmtrain(train_label,Train_features); %% SVM仿真测试 [predict_train_label] = svmpredict(train_label,Train_features,model); [predict_test_label] = svmpredict(test_label,Test_features,model); %% 打印准确率 compare_train = (train_label == predict_train_label); accuracy_train = sum(compare_train)/size(train_label,1)*100; fprintf('训练集准确率:%f ',accuracy_train) compare_test = (test_label == predict_test_label); accuracy_test = sum(compare_test)/size(test_label,1)*100; fprintf('测试集准确率:%f ',accuracy_test)
结果:
*
optimization finished, #iter = 18
nu = 0.668633
obj = -21.678546, rho = 0.380620
nSV = 30, nBSV = 28
*
optimization finished, #iter = 29
nu = 0.145900
obj = -3.676315, rho = -0.010665
nSV = 9, nBSV = 4
*
optimization finished, #iter = 21
nu = 0.088102
obj = -2.256080, rho = -0.133432
nSV = 7, nBSV = 2
Total nSV = 40
Accuracy = 97.1429% (68/70) (classification)
Accuracy = 97.5% (78/80) (classification)
训练集准确率:97.142857
测试集准确率:97.500000