只有满怀自信的人,能在任何地方都怀有自信,沉浸在生活中,并认识自己的意志。
前言
最近公司有一个生产的小集群,专门用于运行spark作业。但是偶尔会因为nn或dn压力过大而导致作业checkpoint操作失败进而导致spark 流任务失败。本篇记录从应用层面对spark作业进行优化,进而达到优化集群的作用。
集群使用情况
有数据的目录以及使用情况如下:
|
目录
|
说明
|
大小
|
文件数量
|
数据数量占比
|
数据大小占比
|
|---|---|---|---|---|---|
| /user/root/.sparkStaging/applicationIdxxx | spark任务配置以及所需jar包 | 5G | 约1k | 约20% | 约100% |
| /tmp/checkpoint/xxx/{commits|metadata|offsets|sources} | checkpoint文件,其中commits和offsets频繁变动 | 2M | 约4k | 约80% | 约0% |
对于.sparkStaging目录,不经常变动,只需要优化其大小即可。
对于 checkpoint目录,频繁性增删,从生成周期和保留策略两方面去考虑。
.sparkStaging目录优化
对于/user/root/.sparkStaging下文件,是spark任务依赖文件,可以将jar包上传到指定目录下,避免或减少了jar包的重复上传,进而减少任务的等待时间。
可以在spark的配置文件spark-defaults.conf配置如下内容:
spark.yarn.archive=hdfs://hdfscluster/user/hadoop/jars spark.yarn.preserve.staging.files=false
参数说明
|
Property Name
|
Default
|
Meaning
|
|---|---|---|
| spark.yarn.archive | (none) | An archive containing needed Spark jars for distribution to the YARN cache. If set, this configuration replaces spark.yarn.jars and the archive is used in all the application's containers. The archive should contain jar files in its root directory. Like with the previous option, the archive can also be hosted on HDFS to speed up file distribution. |
| spark.yarn.preserve.staging.files | false | Set to true to preserve the staged files (Spark jar, app jar, distributed cache files) at the end of the job rather than delete them. |
checkpoint优化
首先了解一下 checkpoint文件代表的含义。
checkpoint文件说明
-
offsets 目录 - 预先记录日志,记录每个批次中存在的偏移量。为了确保给定的批次将始终包含相同的数据,我们在进行任何处理之前将其写入此日志。因此,该日志中的第N个记录指示当前正在处理的数据,第N-1个条目指示哪些偏移已持久地提交给sink。
-
commits 目录 - 记录已完成的批次ID的日志。这用于检查批处理是否已完全处理,并且其输出已提交给接收器,因此无需再次处理。(例如)在重新启动过程中使用,以帮助识别接下来要运行的批处理。
-
metadata 文件 - 与整个查询关联的元数据,只有一个 StreamingQuery 唯一ID
-
sources目录 - 保存起始offset信息
下面从两个方面来优化checkpoint。
第一,从触发checkpoint机制方面考虑
trigger的机制
Trigger是用于指示 StreamingQuery 多久生成一次结果的策略。
Trigger有三个实现类,分别为:
-
OneTimeTrigger - A Trigger that processes only one batch of data in a streaming query then terminates the query.
-
ProcessingTime - A trigger that runs a query periodically based on the processing time. If
intervalis 0, the query will run as fast as possible.by default,trigger isProcessingTime, andinterval=0
-
ContinuousTrigger - A Trigger that continuously processes streaming data, asynchronously checkpointing at the specified interval.
可以为 ProcessingTime 指定一个时间 或者使用 指定时间的ContinuousTrigger ,固定生成checkpoint的周期,避免checkpoint生成过于频繁,减轻多任务下小集群的nn的压力
第二,从checkpoint保留机制考虑。
保留机制
spark.sql.streaming.minBatchesToRetain - 必须保留并使其可恢复的最小批次数,默认为 100
可以调小保留的batch的次数,比如调小到 20,这样 checkpoint 小文件数量整体可以减少到原来的 20%
checkpoint 参数验证
主要验证trigger机制和保留机制
验证trigger机制
未设置trigger效果
未设置trigger前,spark structured streaming 的查询batch提交的周期截图如下:
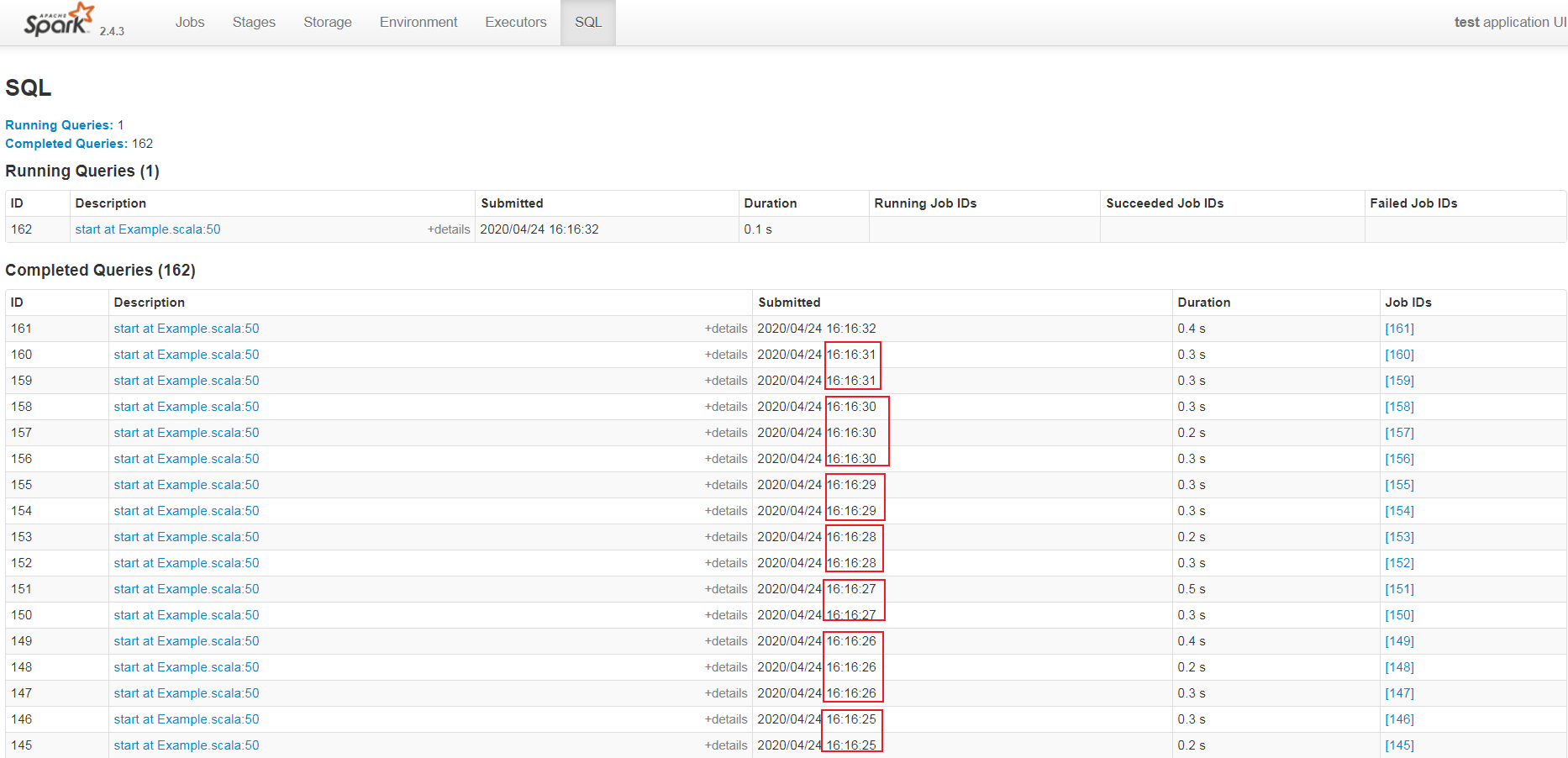
每一个batch的query任务的提交是毫无周期规律可寻。
设置trigger代码
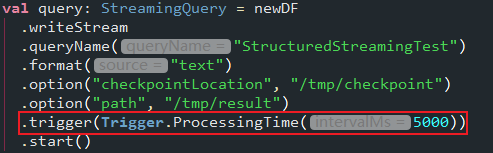
trigger效果
设置trigger代码后效果截图如下:
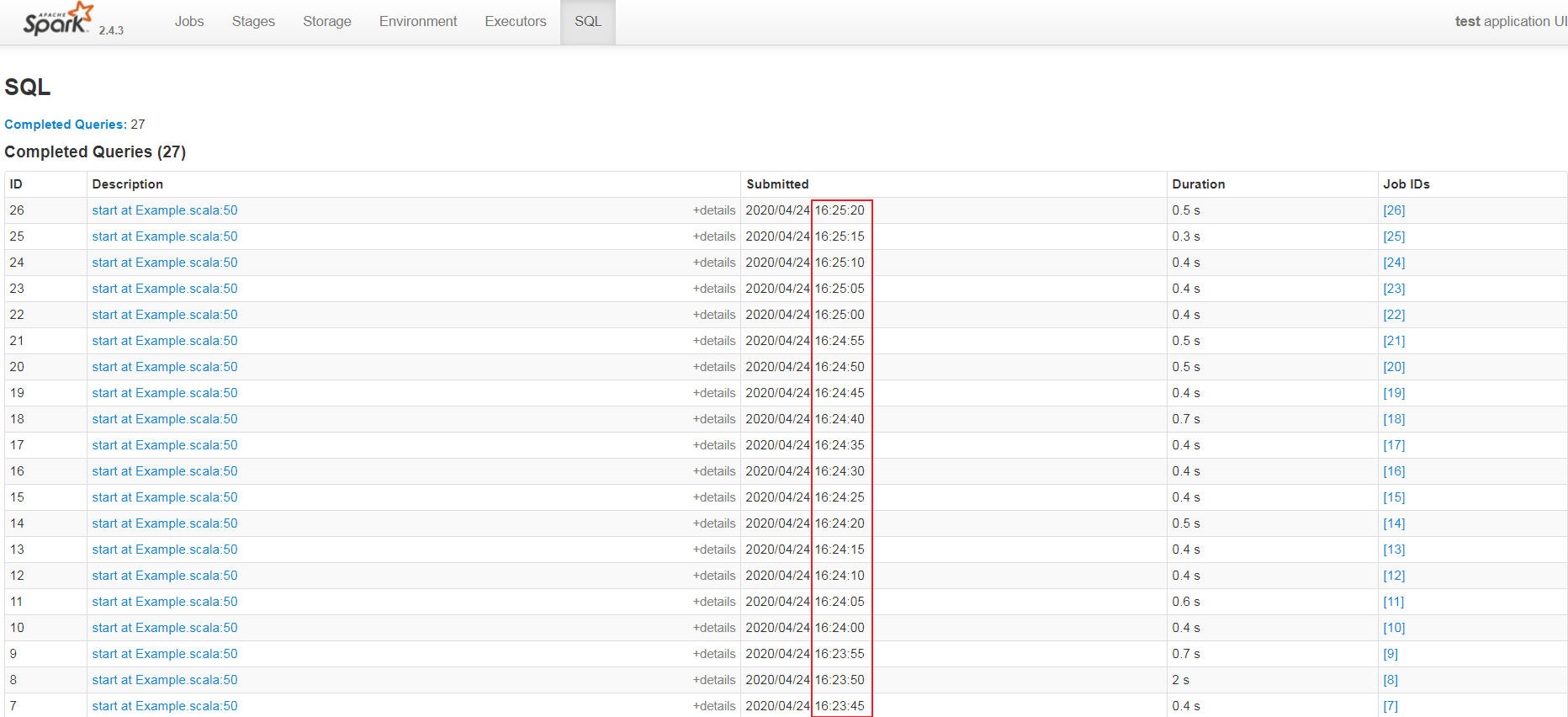
每一个batch的query任务的提交是有规律可寻的,即每隔5s提交一次代码,即trigger设置生效!
注意,如果消息不能马上被消费,消息会有积压,structured streaming 目前并无与spark streaming效果等同的背压机制,为防止单批次query查询的数据源数据量过大,避免程序出现数据倾斜或者无法挽回的OutOfMemory错误,可以通过 maxOffsetsPerTrigger 参数来设置单个批次允许抓取的最大消息条数。
使用案例如下:
spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "xxx:9092") .option("subscribe", "test-name") .option("startingOffsets", "earliest") .option("maxOffsetsPerTrigger", 1) .option("group.id", "2") .option("auto.offset.reset", "earliest") .load()
验证保留机制
默认保留机制效果
spark任务提交参数
#!/bin/bash spark-submit --class zd.Example --master yarn --deploy-mode client --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.3,org.apache.kafka:kafka-clients:2.0.0 --repositories http://maven.aliyun.com/nexus/content/groups/public/ /root/spark-test-1.0-SNAPSHOT.jar
如下图,offsets和commits最终最少各保留100个文件。
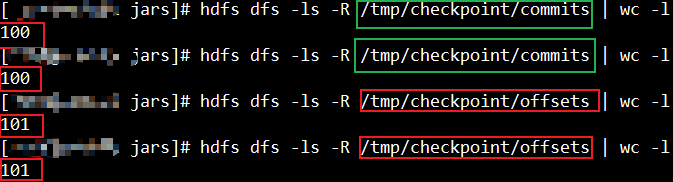
修改保留策略
通过修改任务提交参数来进一步修改checkpoint的保留策略。
添加 --conf spark.sql.streaming.minBatchesToRetain=2 ,完整脚本如下:
#!/bin/bash spark-submit --class zd.Example --master yarn --deploy-mode client --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.3,org.apache.kafka:kafka-clients:2.0.0 --repositories http://maven.aliyun.com/nexus/content/groups/public/ --conf spark.sql.streaming.minBatchesToRetain=2 /root/spark-test-1.0-SNAPSHOT.jar
修改后保留策略效果
修改后保留策略截图如下:
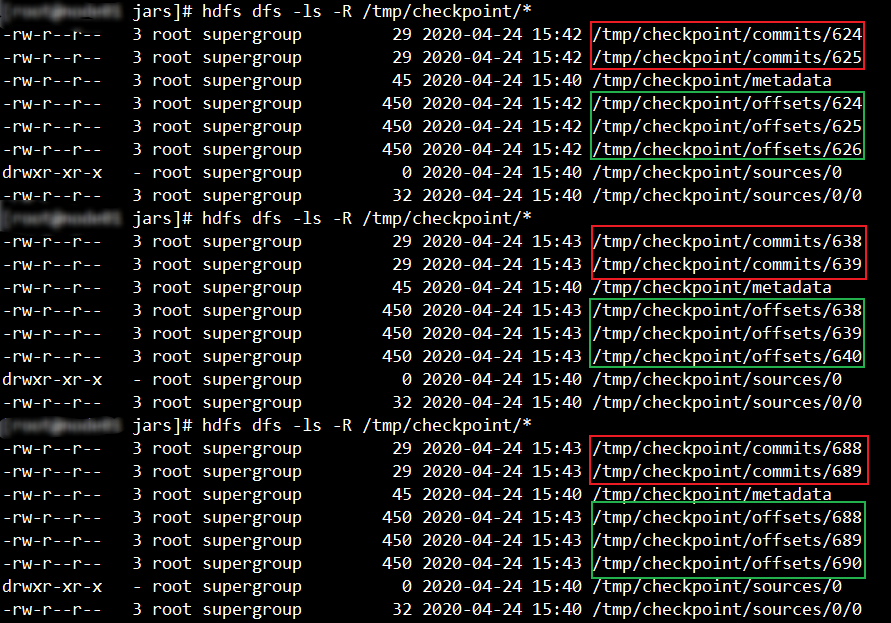
即 checkpoint的保留策略参数设置生效!
总结
综上,可以通过设置 trigger 来控制每一个batch的query提交的时间间隔,可以通过设置checkpoint文件最少保留batch的大小来减少checkpoint小文件的保留个数。
参照
- https://github.com/apache/spark/blob/master/docs/running-on-yarn.md
- https://blog.csdn.net/lm709409753/article/details/85250859
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousExecution.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/streaming/ProcessingTime.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousTrigger.scala
- https://github.com/apache/spark/blob/v2.4.3/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala