转:http://blog.csdn.net/passball/article/details/24037593
主成分分析(PCA)是多元统计分析中用来分析数据的一种方法,它是用一种较少数量的特征对样本进行描述以达到降低特征空间维数的方法,它的本质实际上是K-L变换。PCA方法最著名的应用应该是在人脸识别中特征提取及数据维,我们知道输入200*200大小的人脸图像,单单提取它的灰度值作为原始特征,则这个原始特征将达到40000维,这给后面分类器的处理将带来极大的难度。著名的人脸识别Eigenface算法就是采用PCA算法,用一个低维子空间描述人脸图像,同时用保存了识别所需要的信息。下面先介绍下PCA算法的本质K-L变换。
1、K-L变换(卡洛南-洛伊(Karhunen-Loeve)变换):最优正交变换
- 一种常用的特征提取方法;
- 最小均方误差意义下的最优正交变换;
- 在消除模式特征之间的相关性、突出差异性方面有最优的效果。
离散K-L变换:对向量x(可以想象成 M维=width*height 的人脸图像原始特征)用确定的完备正交归一向量系uj展开:
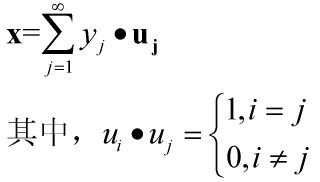
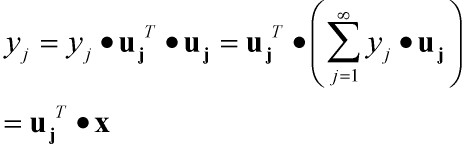
这个公式由来我想应该是任一n维欧式空间V均存在正交基,利用施密特正交化过程即可构建这个正交基。
现在我们希望用d个有限项来估计向量x,公式如下:
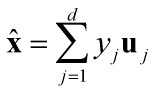
计算该估计的均方误差如下:
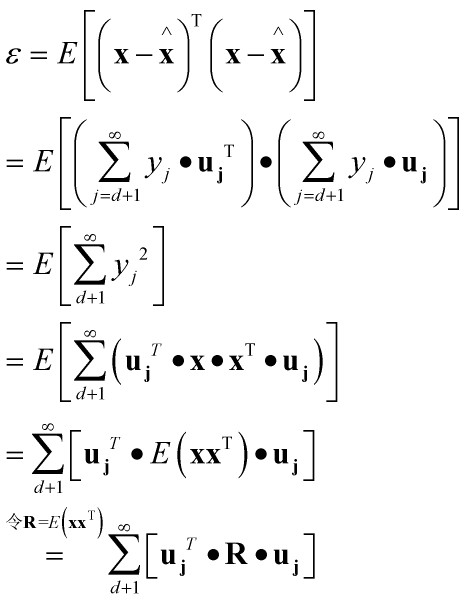
要使用均方误差最小,我们采用Langrange乘子法进行求解:

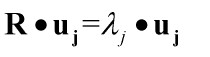
因此,当满足上式时,
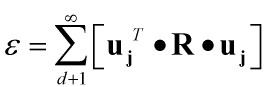 取得最小值。
取得最小值。
即相关矩阵R的d个特征向量(对应d个特征值从大到小排列)为基向量来展开向量x时,其均方误差最小,为:
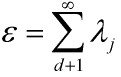
因此,K-L变换定义:当取矩阵R的d个最大特征值对应的特征向量来展开x时,其截断均方误差最小。这d个特征向量组成的正交坐标系称作x所在的D维空间的d维K-L变换坐标系,
x在K-L坐标系上的展开系数向量y称作x的K-L变换。
总结下,K-L变换的方法:对相关矩阵R的特征值由大到小进行排队,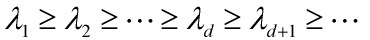
则均方误差最小的x近似于:

矩阵形式:
上式两边乘以U的转置,得
向量y就是变换(降维)后的系数向量,在人脸识别Eigenface算法中就是用系数向量y代替原始特征向量x进行识别。
下面,我们来看看相关矩阵R到底是什么样子。
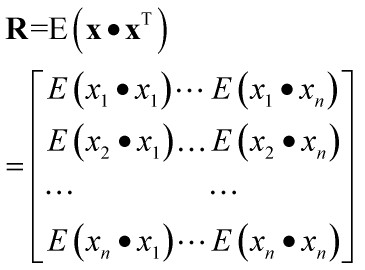
因此,我们可以看出相关矩阵R是一个实对称矩阵(或者严谨的讲叫正规矩阵),正规矩阵有什么特点呢??学过《矩阵分析》的朋友应该知道:
若矩阵R是一个实对称矩阵,则必定存在正交矩阵U,使得R相似于对角形矩阵,即:

因此,我们可以得出这样一个结论:
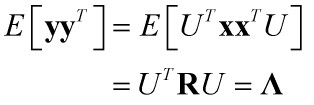
降维后的系数向量y的相关矩阵是对角矩阵,即通过K-L变换消除原有向量x的各分量间的相关性,从而有可能去掉那些带有较少信息的分量以达到降低特征维数的目的。
2、主成分分析(PCA)
主成分分析(PCA)的原理就是将一个高维向量x,通过一个特殊的特征向量矩阵U,投影到一个低维的向量空间中,表征为一个低维向量y,并且仅仅损失了一些次要信息。也就是说,通过低维表征的向量和特征向量矩阵,可以基本重构出所对应的原始高维向量。
在人脸识别中,特征向量矩阵U称为特征脸(eigenface)空间,因此其中的特征向量ui进行量化后可以看出人脸轮廓,在下面的实验中可以看出。
以人脸识别为例,说明下PCA的应用。
设有N个人脸训练样本,每个样本由其像素灰度值组成一个向量xi,则样本图像的像素点数即为xi的维数,M=width*height
,由向量构成的训练样本集为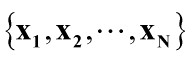 。
。
该样本集的平均向量为:
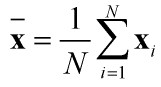
平均向量又叫平均脸。
样本集的协方差矩阵为:
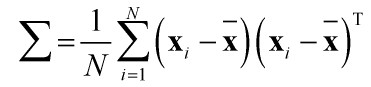
求出协方差矩阵的特征向量ui和对应的特征值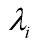 ,这些特征向量组成的矩阵U就是人脸空间的正交基底,用它们的线性组合可以重构出样本中任意的人脸图像,(如果有朋友不太理解这句话的意思,请看下面的总结2。)并且图像信息集中在特征值大的特征向量中,即使丢弃特征值小的向量也不会影响图像质量。
,这些特征向量组成的矩阵U就是人脸空间的正交基底,用它们的线性组合可以重构出样本中任意的人脸图像,(如果有朋友不太理解这句话的意思,请看下面的总结2。)并且图像信息集中在特征值大的特征向量中,即使丢弃特征值小的向量也不会影响图像质量。
将协方差矩阵的特征值按大到小排序:。由大于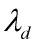 的对应的特征向量构成主成分,主成分构成的变换矩阵为:
的对应的特征向量构成主成分,主成分构成的变换矩阵为:
这样每一幅人脸图像都可以投影到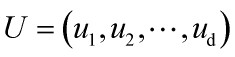 构成的特征脸子空间中,U的维数为M×d。有了这样一个降维的子空间,任何一幅人脸图像都可以向其作投影
构成的特征脸子空间中,U的维数为M×d。有了这样一个降维的子空间,任何一幅人脸图像都可以向其作投影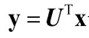 ,即并获得一组坐标系数,即低维向量y,维数d×1,为称为KL分解系数。这组系数表明了图像在子空间的位置,从而可以作为人脸识别的依据。
,即并获得一组坐标系数,即低维向量y,维数d×1,为称为KL分解系数。这组系数表明了图像在子空间的位置,从而可以作为人脸识别的依据。
有朋友可能不太理解,第一部分讲K-L变换的时候,求的是相关矩阵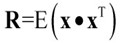 的特征向量和特征值,这里怎么求的是协方差矩阵
的特征向量和特征值,这里怎么求的是协方差矩阵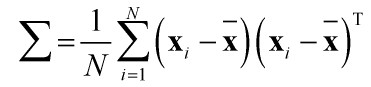 ?
?
其实协方差矩阵也是:
总结下:
1、在人脸识别过程中,对输入的一个测试样本x,求出它与平均脸的偏差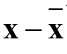 ,则在特征脸空间U的投影,可以表示为系数向量y:
,则在特征脸空间U的投影,可以表示为系数向量y:
U的维数为M×d,的维数为M×1,y的维数d×1。若M为200*200=40000维,取200个主成分,即200个特征向量,则最后投影的系数向量y维数降维200维。
2、根据1中的式子,可以得出:
这里的x就是根据投影系数向量y重构出的人脸图像,丢失了部分图像信息,但不会影响图像质量。