原文链接:RabbitMQ 进程结构分析与性能调优
RabbitMQ是一个流行的开源消息队列系统,是AMQP(高级消息队列协议)标准的实现,由以高性能、健壮、可伸缩性出名的Erlang语言开发,并继承了这些优点。业界有较多项目使用RabbitMQ,包括OpenStack、Spring、Logstash等。
腾讯云在开发云消息队列系统(CMQ)时,对RabbitMQ进行了大量的学习和优化,包括瓶颈分析、内存管理、参数调优等。下文结合Erlang和RabbitMQ架构来分析实践中遇到的问题,并探讨相应的优化方案。
一、RabbitMQ 架构分析

AMQP 是一个异步消息传递所使用的应用层协议规范,AMQP 客户端能够无视消息来源任意发送和接受消息,Broker 提供消息的路由、队列等功能。Broker 主要由 Exchange 和 Queue 组成:Exchange 负责接收消息、转发消息到绑定的队列,提供持久化、队列等功能。AMQP 客户端通过 Channel 与 Broker 通信,Channel 是多路复用连接中的一条独立的双向数据流通道。
1. RabbitMQ 的进程模型
RabbitMQ Server实现了AMQP模型中Broker部分,将 Channel 和 Queue 设计成了 Erlang 进程,并用 Channel 进程的运算实现 Exchange 的功能。
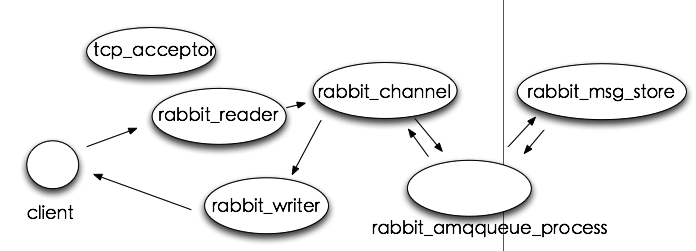
上图中,tcp_acceptor 进程接收客户端连接,创建 rabbit_reader、rabbit_writer、rabbit_channel进程。rabbit_reader 接收客户端连接,解析 AMQP 帧;rabbit_writer 向客户端返回数据;rabbit_channel 解析 AMQP 方法,对消息进行路由,然后发给相应队列进程。
rabbit_amqqueue_process 是队列进程,在 RabbitMQ 启动(恢复 durable 类型队列)或创建队列时创建。rabbit_msg_store 是负责消息持久化的进程。
在整个系统中,存在一个 tcp_accepter 进程,一个 rabbit_msg_store 进程,有多少个队列就有多少个 rabbit_amqqueue_process 进程,每个客户端连接对应一个 rabbit_reader 和 rabbit_writer 进程。
2. RabbitMQ 流控
RabbitMQ 可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞(block),直到对应项恢复正常。除了这两个阈值,RabbitMQ 在正常情况下还用流控(Flow Control)机制来确保稳定性。
Erlang 进程之间并不共享内存(binaries类型除外),而是通过消息传递来通信,每个进程都有自己的进程邮箱。Erlang 默认没有对进程邮箱大小设限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。
在 RabbitMQ 中,如果生产者持续高速发送,而消费者消费速度较低时,如果没有流控,很快就会使内部进程邮箱大小达到内存阈值,阻塞生产者(得益于 block 机制,并不会崩溃)。然后 RabbitMQ 会进行 page 操作,将内存中的数据持久化到磁盘中。
为了解决该问题,RabbitMQ 使用了一种基于信用证的流控机制。消息处理进程有一个信用组 {InitialCredit, MoreCreditAfter},默认值为 {200, 50}。消息发送者进程 A 向接收者进程 B 发送消息,每发一条消息,Credit 数量减 1,直到为 0,A 被 block 住;对于接收者 B,每接收 MoreCreditAfter 条消息,会向 A 发送一条消息,给予 A MoreCreditAfter 个 Credit,当 A 的 Credit > 0 时,A 可以继续向 B 发送消息。

可以看出基于信用证的流控最终将消息发送进程的发送速度限制在消息处理进程的处理速度内。RabbitMQ 中与流控有关的进程构成了一个有向无环图。
3. amqqueue 进程与 Paging
如上所述,消息的存储和队列功能是在 amqqueue 进程中实现。为了高效处理入队和出队的消息、避免不必要的磁盘 IO,amqqueue 进程为消息设计了 4 种状态和 5 个内部队列。
4 种状态包括:alpha,消息的内容和索引都在内存中;beta,消息的内容在磁盘,索引在内存;gamma,消息的内容在磁盘,索引在磁盘和内存中都有;delta,消息的内容和索引都在磁盘。对于持久化消息,RabbitMQ 先将消息的内容和索引保存在磁盘中,然后才处于上面的某种状态(即只可能处于 alpha、gamma、delta 三种状态之一)。
5 个内部队列包括:q1、q2、delta、q3、q4。q1 和 q4 队列中只有 alpha 状态的消息;delta 队列是消息按序存盘后的一种逻辑队列,只有 delta 状态的消息。所以 delta 队列并不在内存中,其他 4 个队列则是由 Erlang queue 模块实现的。

消息从 q1 入队,q4 出队,在内部队列中传递的过程一般是经 q1 到 q4。实际执行并非如此:开始时所有队列都为空,消息直接进入 q4(没有消息堆积时);内存紧张时将 q4 队尾部分消息传入 q3,进而再由 q3 传入 delta,此时新来的消息将存入 q1(有消息堆积时)。
Paging 就是在内存紧张时触发的,paging 将大量 alpha 状态的消息转换为 beat 和 gamma;如果内存依然紧张,继续将beta 和 gamma 状态转换为 delta 状态。Paging 是一个持续过程,涉及到大量消息的多种状态转换,所以 Paging 的开销较大,严重影响系统性能。
二、问题分析
在生产者、消费者均正常情况下,RabbitMQ 压测性能非常稳定,保持在一个恒定的速度。当消费者异常或不消费时,RabbitMQ 则表现极不稳定。
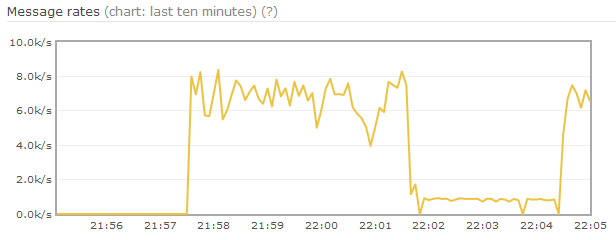

测试场景如下,exchange 和队列都是持久化的,消息也是持久化的、固定为 1k,并且无消费者。如上图所示,在达到内存 paging 阈值后,生产速率降低,并持续较长时间。内存情况表明,在内存中的消息数目只有 18M 内容,其他消息已经 page 到磁盘中,然而进程内存仍占用 2G。Erlang 内存使用表明,Queue 占用了 2G,Binaries 占用了 2.1 G。
该情况说明在消息从内存page到磁盘后(即从 q2、q3 队列转到 delta 后),系统中产生了大量的垃圾(garbage),而 Erlang VM 没有进行及时的垃圾回收(GC)。这导致 RabbitMQ 错误地计算了内存使用量,并持续调用 paging 流程,直到 Erlang VM 隐式垃圾回收。
三、内存管理优化
RabbitMQ 内存使用量的计算是在memory_monitor进程内执行的,该进程周期性计算系统内存使用量。同时amqqueue进程会周期性拉取内存使用量,当内存达到 paging 阈值时,触发 amqqueue 进程进行 paging。paging 发生后,amqqueue 进程每收到一条消息都会对内部队列进行 page(每次 page 都会计算出一定数目的消息存盘)。
该过程可行的优化方案是:在 amqqueue 进程将大部分消息paging到磁盘后,显式调用GC,同时将memory_monitor周期设为0.5s、amqqueue拉取周期设为1s,这样就能够达到秒级恢复;去掉对每条消息执行paging的操作,用amqqueue周期性拉取内存使用量的操作来触发page,这样能够更快将消息paging到磁盘,而且保持这个周期内生产速度不下降。
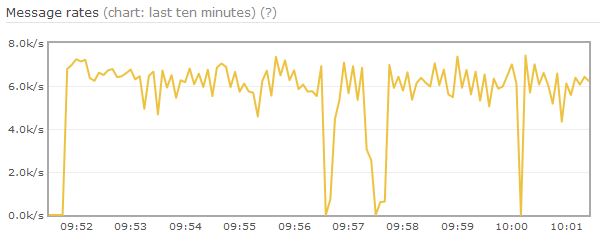
从修改后效果可以看出,三次paging都很快结束,前两次paging相邻较近是因为两个镜像节点分别执行了paging。
(注:目前版本好像解决了这个问题)
从前文图中还可以发现,在22:01时生产速度有一个明显的下降(此时未发生paging)。通过流控分析,链路被block在amqqueue进程;经观察发现节点内存使用下降了,说明该节点执行了GC。Erlang GC是按进程级别的标记-清扫模式,会将当前进程暂停,直至GC结束。由于在RabbitMQ中,一个队列只有一个amqqueue进程,该进程又会处理大量的消息,产生大量的垃圾。这就导致该进程GC较慢,进而流控block上游更长时间。
查看RabbitMQ代码发现,amqqueue进程的gen_server模型在正常的逻辑中调用了hibernate,该操作可能导致两次不必要的GC。优化掉hibernate对系统稳定性有一些帮助。
对流控可能比较好的优化方案是:用多个amqqueue进程来实现一个队列,这样可以降低rabbit_channel被单个amqqueue进程block的概率,同时在单队列的场景下也能更好利用多核的特性。不过该方案对RabbitMQ现有的架构改动很大,难度也很大。
四、参数调优
RabbitMQ可优化的参数分为两个部分,Erlang部分和RabbitMQ自身。
-
IO_THREAD_POOL_SIZE:CPU大于或等于16核时,将Erlang异步线程池数目设为100左右,提高文件IO性能。
-
hipe_compile:开启Erlang HiPE编译选项(相当于Erlang的jit技术),能够提高性能20%-50%。在Erlang R17后HiPE已经相当稳定,RabbitMQ官方也建议开启此选项。
-
queue_index_embed_msgs_below:RabbitMQ 3.5版本引入了将小消息直接存入队列索引(queue_index)的优化,消息持久化直接在amqqueue进程中处理,不再通过msg_store进程。由于消息在5个内部队列中是有序的,所以不再需要额外的位置索引(msg_store_index)。该优化提高了系统性能10%左右。
-
vm_memory_high_watermark:用于配置内存阈值,建议小于0.5,因为Erlang GC在最坏情况下会消耗一倍的内存。
-
vm_memory_high_watermark_paging_ratio:用于配置paging阈值,该值为1时,直接触发内存满阈值,block生产者。
-
queue_index_max_journal_entries:journal文件是queue_index为避免过多磁盘寻址添加的一层缓冲(内存文件)。对于生产消费正常的情况,消息生产和消费的记录在journal文件中一致,则不用再保存;对于无消费者情况,该文件增加了一次多余的IO操作。
五、其他优化和注意的地方
1、一定要注意避免触发流控,增加消费者,提高消费者的消费能力;
2、消息的大小会影响消息的发送速率;
3、消费者的预取参数的大小对消费者的消费性能影响很大;
- prefetch设置的过大,可能导致消费者处理不过来,堆积在本地缓存区,导致消息处理延迟过长。
- prefetch设置的过小,会导致消费者不能充分工作。
六、总结
RabbitMQ在2007年发布第一个版本时,只有5000行Erlang代码,到现在已经加入了非常多的特性,但基本架构没有变。从多核的角度看,流控机制和单amqqueue进程之间存在一些冲突,对消费者异常这种场景,还需要从整个架构方面做更多优化。
除了上述内容,RabbitMQ在Cluster、HA、可靠交付、扩展支持等方面也做了大量的工作,这些都值得深入的学习。
参考:
https://www.rabbitmq.com/admin-guide.html
https://github.com/rabbitmq/rabbitmq-server/issues/101
http://prog21.dadgum.com/16.html
http://www.erlang.org/doc/man/gen_server.html
http://docs.basho.com/riak/latest/ops/tuning/erlang/
http://www.erlang.org/doc/efficiency_guide/introduction.html